
DDD (Domain Driven Design)
-
도메인이 중심이 되는 개발 방식
- DDD는 추상적인 설계 철학이고 여러 답이 나올 수 있다는 점에서 예술이다
- 기존 Model Driven Design을 한 단계 발전시킴
- 기존 Model Driven Design은 생산성 향상에 초점을 맞춘 기술 중심적 접근 방식
- DDD는 MDD에 비즈니스 중심의 접근 방식과 전략적 설계 개념을 추가
- 핵심 목표: Loose Coupling, High Cohesion
- 지속적으로 진화하는 모델을 만들면서 복잡한 어플리케이션을 쉽게 만들어 가는 것
전략적 설계 & 전술적 설계
-
전략적 설계 (Strategic Design)
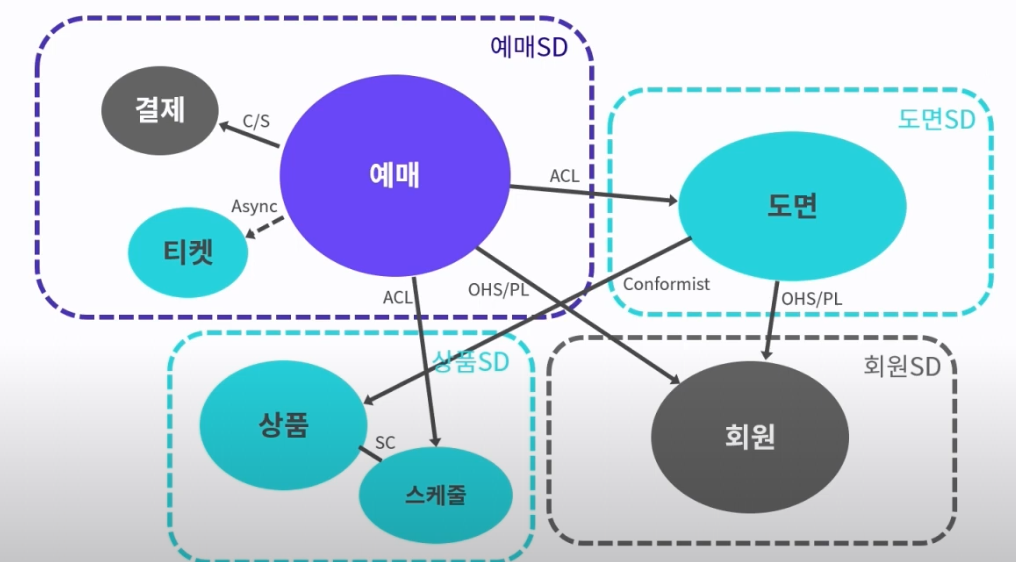
-
도메인 문제를 문제 공간에서 해결 공간으로 가져가는 과정 (도메인 전문가와 기술팀이 함께 회의)
- 문제 공간(Problem Space): 도메인 추출 및 하위 도메인 분류 (도메인 전문가가 주요 역할)
- 해결 공간(Solution Space): 바운디드 컨텍스트 및 컨텍스트 맵 정의 (개발자가 주요 역할)
- 범위: 전반적
- 핵심 개념: Ubiquitous Language (보편 언어)
- 핵심은 유비쿼터스 언어에 기반한 팀 간 커뮤니케이션
- 유용한 도구
- 사용 사례(유스케이스) 분석
- 이벤트 스토밍 (Event Stroming)
- Business Model 분석
- …
-
도메인 문제를 문제 공간에서 해결 공간으로 가져가는 과정 (도메인 전문가와 기술팀이 함께 회의)
-
전술적 설계 (Tactical Design)
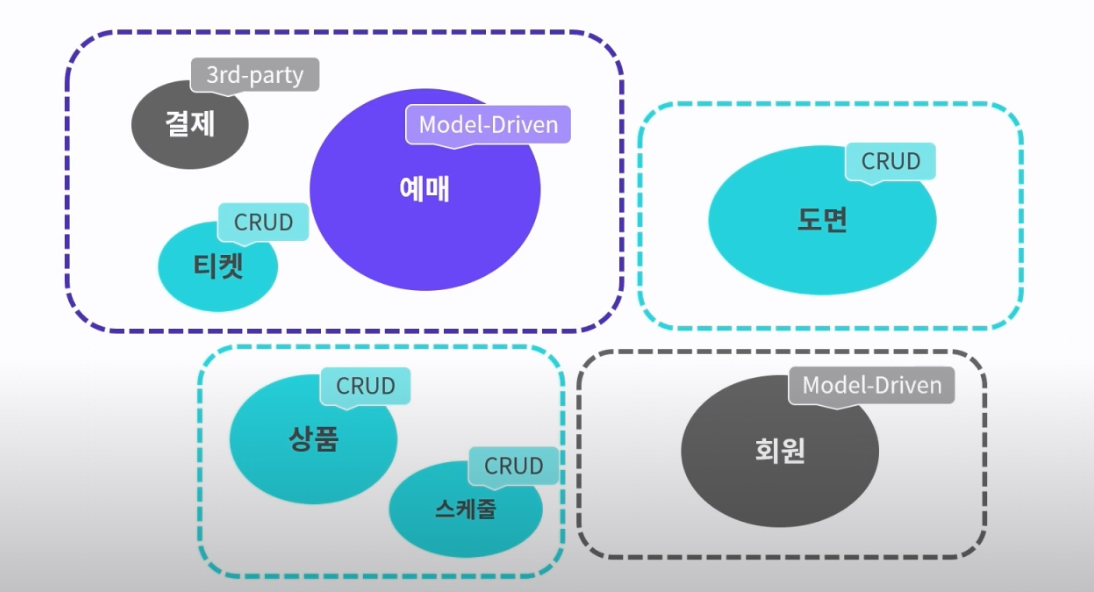
- 전략적 설계에서 도출된 도메인 모델과 컨텍스트 맵을 이용해 실제 구현 진행
- e.g. 바운디드 컨텍스트마다 도메인에 알맞은 아키텍처 사용
- 핵심 Bounded Context는 Model-Driven
- 지원 Bounded Context는 CRUD (서비스-DAO)
- 일반 Bounded Context는 Model-Driven, 3rd-party…
- e.g. 컨텍스트 내 혼합도 가능 (CQRS)
- 상태 변경 관련 기능은 Model-Driven
- 조회 기능은 CRUD (서비스-DAO)
- e.g. 바운디드 컨텍스트마다 서로 다른 구현 기술 사용도 가능
- 바운디드 컨텍스트 1: 스프링 MVC + JPA
- 바운디드 컨텍스트 2: Netty + Mybatis
- 바운디드 컨텍스트 3: 스프링 MVC + 몽고 DB
- e.g. 바운디드 컨텍스트마다 도메인에 알맞은 아키텍처 사용
- 범위: 특정 Bounded Context
- 핵심 개념: Model Driven Design (모델 주도 설계)
- 도메인 모델을 중심으로 패턴 적용
- 유용한 패턴
- 계층형 아키텍처
- Entity, Value Object
- Aggregate
- Factory
- Repository
- Domain Event
- 전략적 설계에서 도출된 도메인 모델과 컨텍스트 맵을 이용해 실제 구현 진행
콘웨이의 법칙
소프트웨어의 구조는 해당 소프트웨어를 개발하는 조직의 구조를 따라간다.
역콘웨이의 전략
개발하는 조직의 구조를 소프트웨어의 구조에 맞춘다. 바운디드 컨텍스트 별로 팀을 구성하는 것도 좋다.
DDD 주요 개념
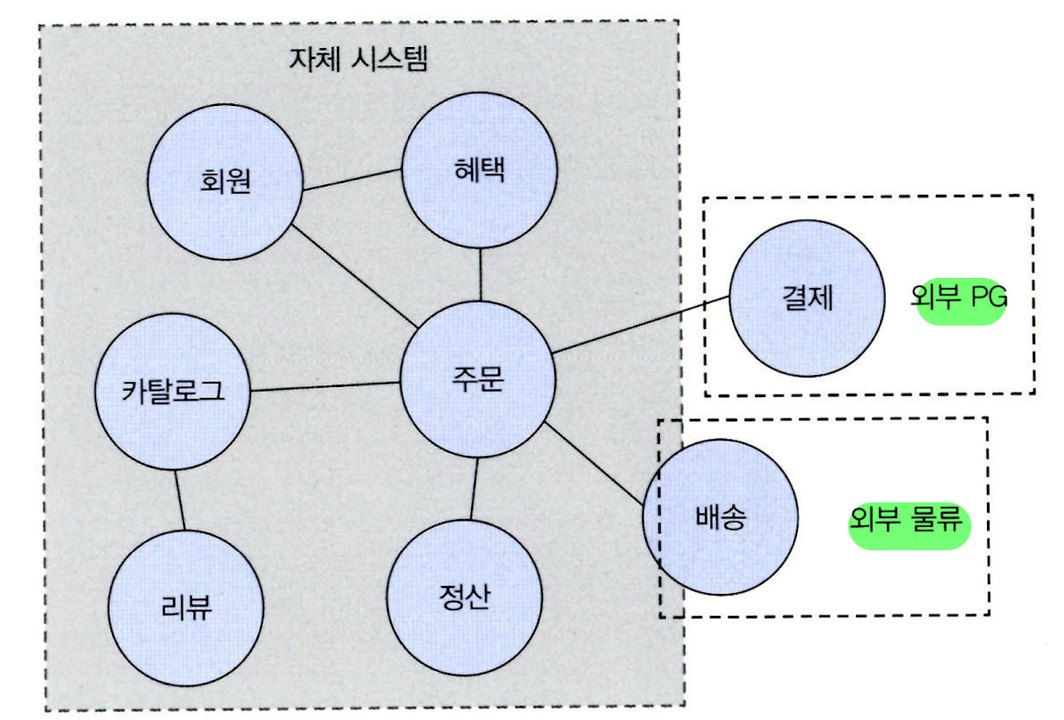
- 도메인
- 소프트웨어로 해결하고자 하는 현실 세계의 문제 영역
- e.g. 온라인 서점
- 세부적 분류
- 비즈니스 도메인: 전체 문제 영역
- 문제 도메인: 전체 문제 영역 중 IT로 해결하고자 하는 문제 영역
- 도서 기업의 경우 문제 도메인은 전체 비즈니스 도메인의 일부분
- IT 기업의 경우 비즈니스 도메인 전부가 문제 도메인
- 소프트웨어로 해결하고자 하는 현실 세계의 문제 영역
- 하위 도메인
- 한 도메인은 여러 하위 도메인으로 나눌 수 있음
- e.g. 카탈로그, 주문, 혜택, 배송 …
- 3가지 유형으로 분류 가능
- 핵심 하위 도메인: 가장 중요한 문제
- 지원 하위 도메인: 핵심 도메인을 지원하는 문제
- 일반 하위 도메인: 대부분의 소프트웨어가 가지고 있는 문제 (e.g. 회원)
- 하위 도메인들은 서로 연동하여 완전한 기능을 제공
- 도메인의 특정 기능은 외부 시스템이나 수작업을 활용하기도 함
- e.g. 배송 업체, 결제 대행 업체, 소규모 업체의 정산 수작업 엑셀 처리
- 한 도메인은 여러 하위 도메인으로 나눌 수 있음
- 도메인 전문가
- 온라인 홍보, 정산, 배송 등 각 영역에는 전문가 존재
-
요구사항을 제대로 이해할수록 도메인 전문가가 원하는 제품으로 향할 가능성 높음
-
개발자와 전문가는 직접 대화해야 함
- 중간에서 발생하는 정보의 왜곡과 손실을 방지
- 개발자는 전문가가 진짜 원하는 것을 찾아야 함
- 도메인 전문가 스스로도 요구사항을 정확히 표현 못할 수 있음
-
개발자와 전문가는 직접 대화해야 함
- 도메인 모델
-
특정 도메인을 개념적으로 표현한 것
- e.g. 객체 기반 모델링 (기능과 데이터), 상태 다이어그램 기반 모델링 (상태 전이) - UML 예시
- 도메인을 이해하는데 도움이 된다면 표현 방식은 어느 것이든 괜찮음 (중요한 내용만 담음)
- 관계가 중요한 도메인은 그래프, 계산 규칙이 중요하면 수학 공식 이용
- 도메인 모델 (개념) VS 구현 모델 (구현 기술)
-
각 하위 도메인마다 별도로 모델을 만들어야 함 (올바른 방법)
- 같은 용어라도 하위 도메인마다 의미가 달라질 수 있음
- e.g. 카탈로그 상품 (이미지, 상품명, 가격 위주), 재고 관리 상품 (실존 개별 객체 추적 목적)
- 도메인 모델은 엔터티와 밸류 타입으로 구분 가능
- 모델링 방법
- 요구사항을 바탕으로 도메인 모델을 구성하는 핵심 구성요소(엔터티, 속성), 규칙, 기능 찾기
- 상위 수준에서 정리한 문서화가 매우 큰 도움이 됨 (e.g. 화이트 보드, 위키 등)
-
특정 도메인을 개념적으로 표현한 것
- 바운디드 컨텍스트 (Bounded Context)
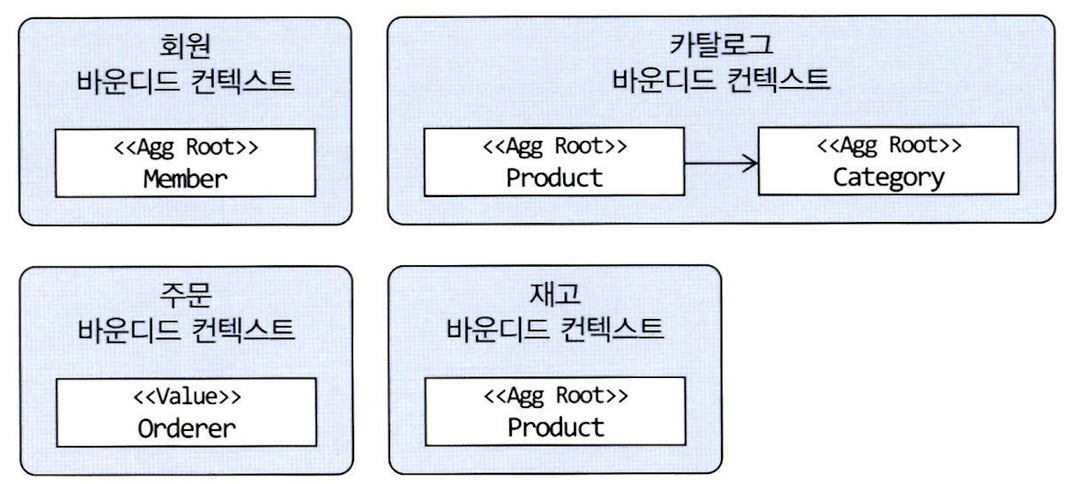
- 특정 도메인 모델을 구분하는 경계를 정의
- 구조: 도메인 모델 + 표현 영역, 응용 서비스, 도메인, 인프라스트럭처, DBMS를 모두 포함
- 바운디드 컨텍스트는 용어를 기준으로 구분 (컨택스트 내에서 동일한 유비쿼터스 언어 사용)
- e.g. 같은 상품도 카탈로그 B.C의 Product와 재고 B.C의 Product는 각 B.C에 맞는 모델 가짐
- 바운디드 컨텍스트가 하위 도메인과 1 : 1 관계를 가지면 이상적이지만, 현실은 그렇지 않을 때가 많음
- 이상적 목표: 바운디드 컨텍스트 1 : 하위 도메인 1 : 도메인 모델 1
- 현실
- e.g. 팀 조직 구조에 따라 결정
- 주문 바운디드 컨텍스트 + 결제 금액 계산 바운디드 컨텍스트 = 주문 하위 도메인
- e.g. 용어를 명확히 구분 못해 두 하위 도메인을 하나의 바운디드 컨텍스트에서 구현
- 상품 바운디드 컨텍스트 = 카탈로그 하위 도메인 + 재고 하위 도메인
- e.g. 규모가 작은 기업은 전체 시스템을 한 개팀에서 구현
- 소규모 쇼핑몰을 1개의 웹 애플리케이션으로 제공
- 1개 바운디드 컨텍스트 = 회원 + 카탈로그 + 재고 + 구매 + 결제 하위 도메인
- e.g. 팀 조직 구조에 따라 결정
-
여러 하위 도메인을 하나의 바운디드 컨텍스트에서 개발할 때, 하위 도메인 모델이 섞이지 않도록 하자
- 물리 바운디드 컨텍스트가 1개여도 논리 바운디드 컨텍스트 생성하자 (내부에서 패키지 활용)
-
바운디드 컨텍스트 간 통합
- e.g. 카탈로그 하위 도메인에서 카탈로그 B.C와 추천 B.C 개발
- 카탈로그 B.C와 추천 B.C는 서로 다른 도메인 모델 가짐
-
직접 통합 방식 (e.g. REST API)
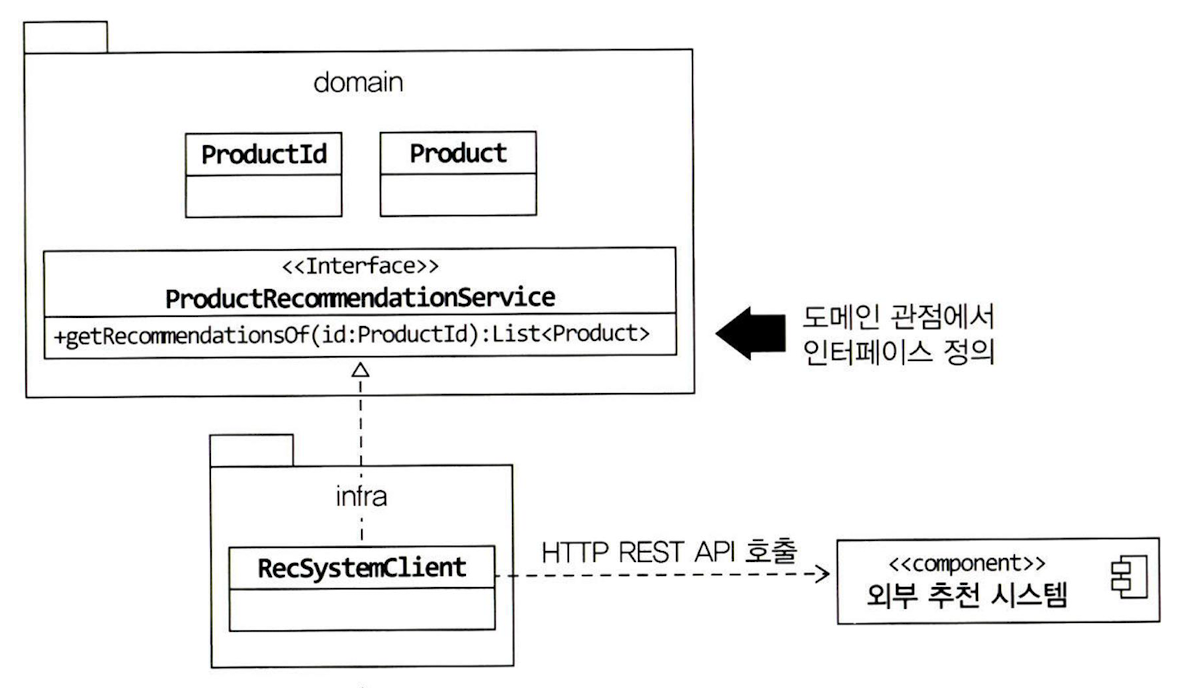
- 클라이언트로 호출한 후 응답 받은 데이터를 현재 도메인에 맞는 모델로 변환
- e.g.
- 카탈로그 시스템은 카탈로그 도메인 모델에 기반한 도메인 서비스로 상품 추천 기능 표현
-
ProductRecommendationService(도메인 서비스) -RecSystemClient(Infra) -
RecSystemClient-
externalRecClient로 추천 시스템의 REST API 호출 - 응답받은 추천 데이터를 카탈로그 도메인에 맞는 상품 모델로 변환
- 변환이 복잡하면 별도의
Translator클래스를 만들어 처리해도 됨
- 변환이 복잡하면 별도의
-
-
간접 통합 방식 (e.g. 메시지 큐)
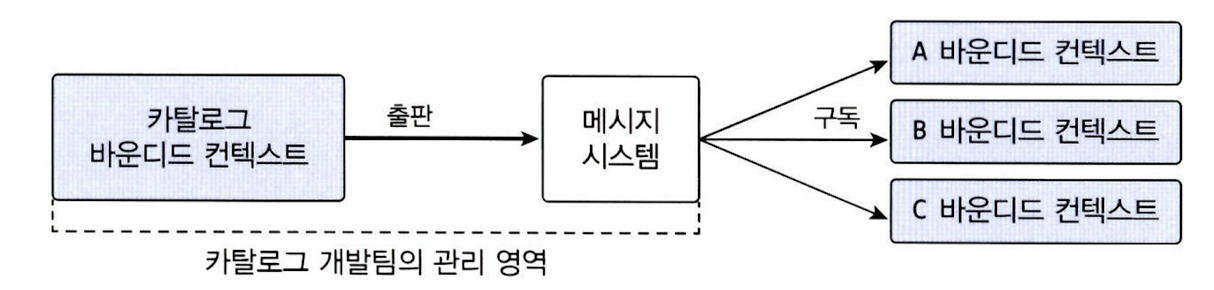
-
출판/구독 모델을 이용해 바운디드 컨텍스트끼리 연동
- 한 바운디드 컨텍스트가 메시지 큐에 필요한 데이터를 저장
- 다른 바운디드 컨텍스트들은 메시지 큐에서 데이터 수신
- 서로 메시지 형식을 맞춰야 함
- 보통 큐를 제공하는 주체에 기반해 데이터 구조 결정
- e.g.
- 추천 시스템은 사용자 활동 이력이 필요 (조회 상품 이력이나 구매 이력 등)
- 메시지 교환
- 카탈로그 시스템은 메시지 큐에 사용자 활동 이력 추가
- 추천 시스템은 메시지 큐에서 메시지를 읽어와 사용
-
카탈로그 시스템에서 큐를 제공하면 메시지 형식은 카탈로그 도메인 모델에 기반함
- 메시지 형식은 어떤 도메인 관점을 쓸지에 따라 달라짐
- 카탈로그 도메인 관점 (
ViewLog,OrderLog-OrderLineLog)- 카탈로그 도메인 모델 기준의 데이터를 메시지 큐에 저장
- 추천 도메인 관점 (
ActiveLog)- 추천 도메인 모델 기준의 데이터로 변환해 메시지 큐에 저장
- 카탈로그 도메인 관점 (
- 메시지 형식은 어떤 도메인 관점을 쓸지에 따라 달라짐
- 만일, 큐를 추천 시스템에서 제공하면 REST API와 비슷해짐
- 물론 카탈로그 시스템이 비동기로 전달한다는 차이는 있음
-
출판/구독 모델을 이용해 바운디드 컨텍스트끼리 연동
- e.g. 카탈로그 하위 도메인에서 카탈로그 B.C와 추천 B.C 개발
-
바운디드 컨텍스트 간 관계
- API 호출 방식 (e.g. REST API, 프로토콜 버퍼) - 메시지 큐 방식도 포함될 듯함!
- 단점은 하류 컴포넌트(Downstream)는 상류 컴포넌트(Upstream)에 의존
- 즉, API를 사용하는 바운디드 컨텍스트는 API를 제공하는 바운디드 컨텍스트에 의존
- 상류 컴포넌트는 상류 B.C의 도메인 모델을 따름
-
공개 호스트 서비스 (Open Host Service)
- 상류 팀이 여러 하류팀의 요구사항을 수용할 수 있는 API를 만들어 제공하는 서비스
- e.g. 검색 B.C (상류 컴포넌트) : 블로그, 카페, 게시판 B.C (하류 컴포넌트)
-
안티코럽션 계층 (Anticorruption Layer)
- 하류 서비스는 상류 서비스 모델이 자신의 모델에 영향을 주지 않도록 완충지대 구성
- e.g. 앞선
RecSystemClient는 모델 변환 처리와 안티코럽션 계층 역할을 함
- 단점은 하류 컴포넌트(Downstream)는 상류 컴포넌트(Upstream)에 의존
- 공유 커널 방식 (Shared Kernel)
- 두 바운디드 컨텍스트가 같은 모델을 공유
- 공유 커널: 함께 공유하는 모델
- e.g. 운영자를 위한 주문 관리 도구 개발 팀 VS 고객을 위한 주문 서비스 개발 팀
- 주문을 표현하는 모델을 서로 공유해 주문과 관련된 중복 설계 방지
- 중복을 줄여주는 장점 (동일한 모델을 두 번 개발하는 것을 방지)
- 공유 커널을 사용하는 두 팀은 반드시 밀접한 관계를 유지해야 함
- 두 바운디드 컨텍스트가 같은 모델을 공유
- 독립 방식 (Separate Way)
- 서로 통합하지 않는 방식
- 두 바운디드 컨텍스트 간 통합이 필요하다면 수동으로 진행
- e.g. 온라인 쇼핑몰 판매 정보를 운영자가 직접 ERP 시스템에 입력
- 규모가 커지면 결국 두 바운디드 컨텍스트를 통합해야 함 (수동 통합은 한계가 있음)
- API 호출 방식 (e.g. REST API, 프로토콜 버퍼) - 메시지 큐 방식도 포함될 듯함!
- 컨텍스트 맵 (Context Map)
-
바운디드 컨텍스트 간의 관계를 표시한 지도
- 전체 비즈니스 조망 가능 (시스템의 전체 구조)
- 규칙은 크게 없음
- 해결 공간의 대표적 산출물
-
매핑 관계 용어
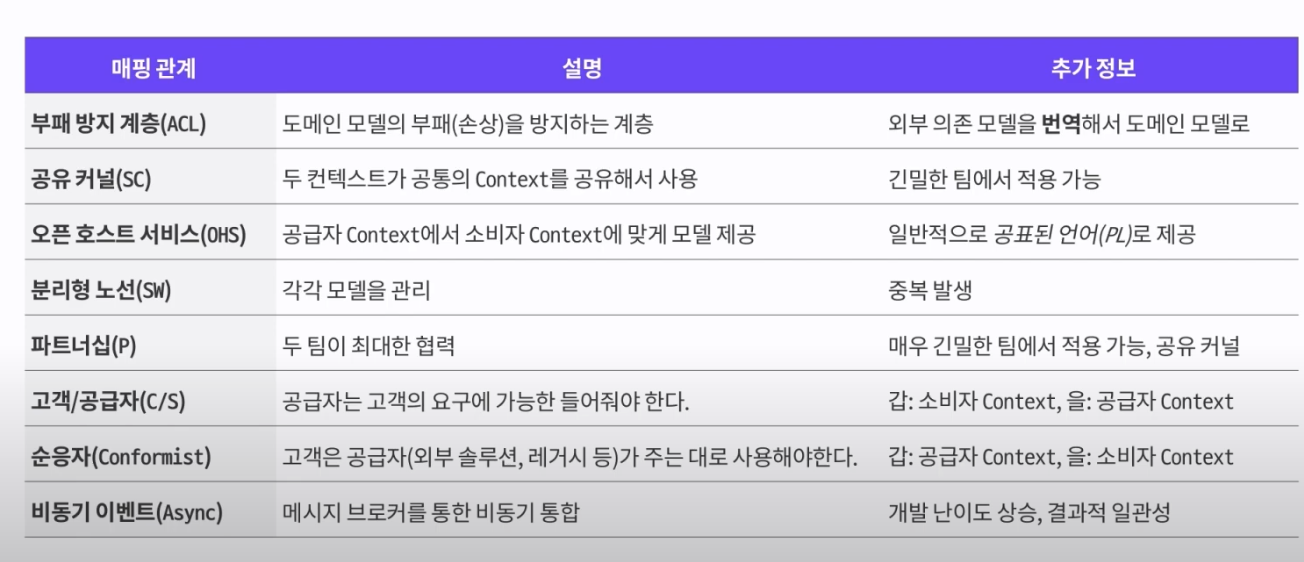
-
바운디드 컨텍스트 간의 관계를 표시한 지도
- 유비쿼터스 언어 (Ubiquitous Language, 전략적 설계의 핵심)
- 전문가, 관계자, 개발자가 공유하는 도메인과 관련된 공통 언어 (도메인에서 사용하는 용어)
- 바운디드 컨텍스트 내에서 동일한 유비쿼터스 언어 공유
-
대화, 문서, 도메인 모델, 코드, 테스트 등 모든 곳에 반영해야 한다
- 소통 과정에서 용어의 모호함이 감소
- 개발자는 도메인과 코드 사이에서 불필요한 의미 해석 과정 감소
- 알맞은 영어 단어 찾는 시간을 아끼지 말고, 코드와 문서는 변화를 바로 반영해 최신 상태를 유지
- 모델 주도 설계 (Model Driven Design, 전술적 설계의 핵심)
- 비즈니스 도메인의 핵심 개념과 규칙을 반영한 모델을 기반으로 설계하는 방법론
- DDD를 위한 패턴들을 사용해 모델이 생명력을 잃지 않도록 지속적으로 관리
- e.g. 계층형 아키텍처, Entity, Value Object, Aggregate, Factory, Repository…
객체 기반 도메인 모델링
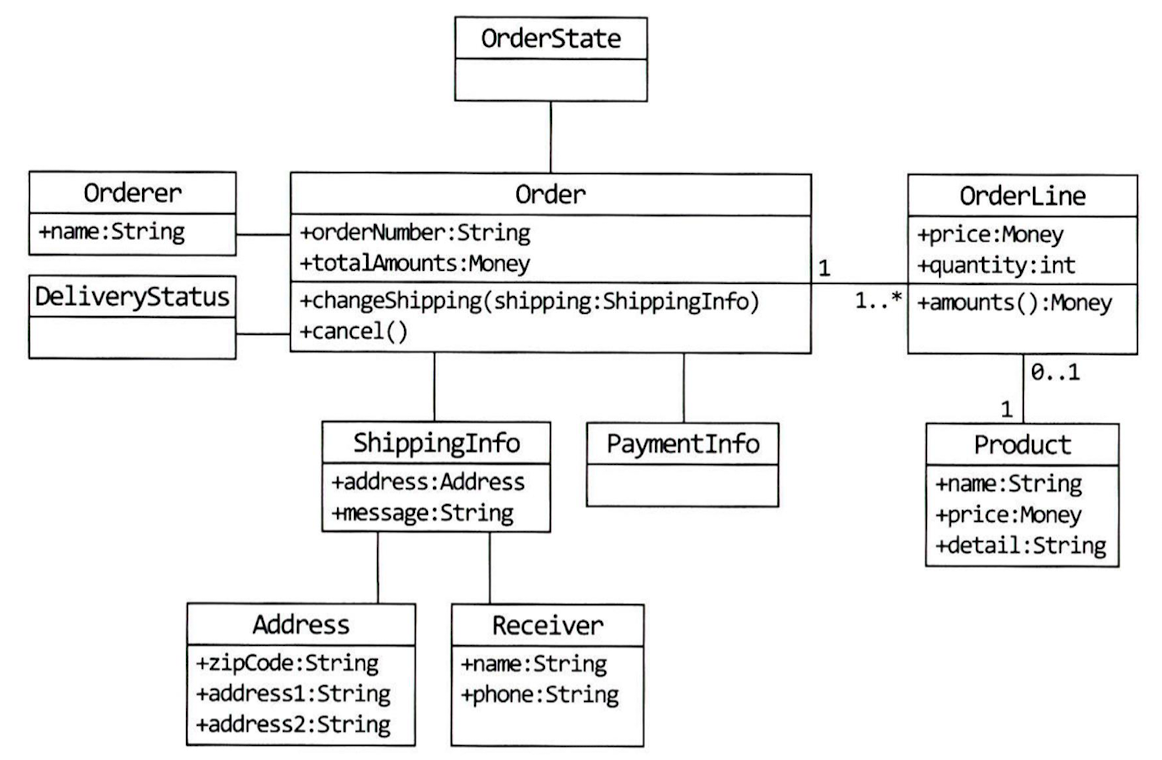
상태 다이어그램 기반 도메인 모델링
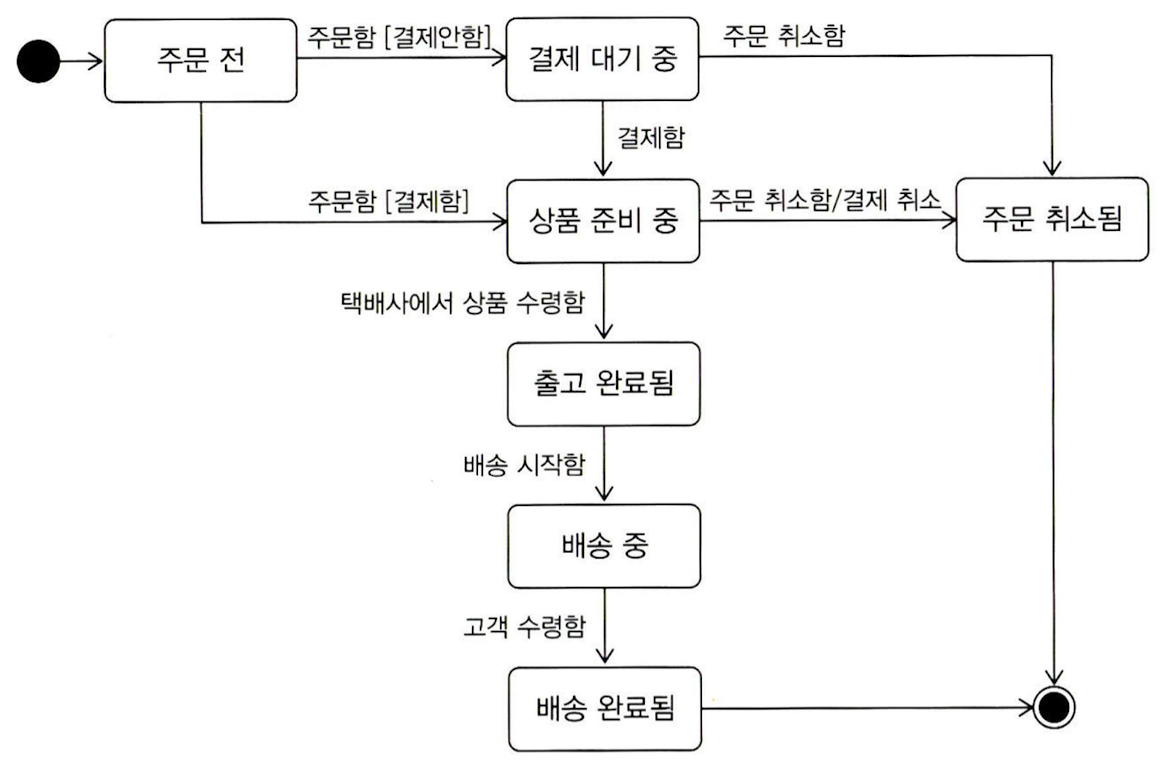
도메인 모델, DTO와
get/set메서드도메인 모델에
get/set메서드를 무조건 추가하는 것은 좋지 않은 버릇이다.
특히set메서드는 필드값만 변경하고 끝나기 때문에 상태 변경과 관련된 도메인의 핵심 개념이나 의도를 코드에서 사라지게 한다. 또한,set메서드를 열어두는 것은 도메인 객체를 불완전하게 생성하도록 허용한다.따라서, 도메인 객체는 생성자를 통해 필요한 데이터를 모두 받도록 설계해야 한다. (이 경우,
private한set을 만들어 생성자에서 사용할 수 있음)
또한, 불변 밸류 타입을 사용하면 자연스럽게set메서드 사용이 사라진다.DTO는 도메인 로직이 없어
get/set메서드를 사용해도 데이터 일관성에 영향을 덜 주지만, 프레임워크의private필드 직접 할당 기능을 최대한 사용하면 불변 객체의 장점을 DTO까지 확장할 수 있어 권장한다.
그린 필드 & 브라운 필드
그린필드: 소프트웨어의 초기 개발 시점 (코드가 깨끗함)
브라운 필드: 소프트웨어가 장기간 개발되어 복잡해진 시점
계층 구조 아키텍처 구성 - 도메인 모델 패턴
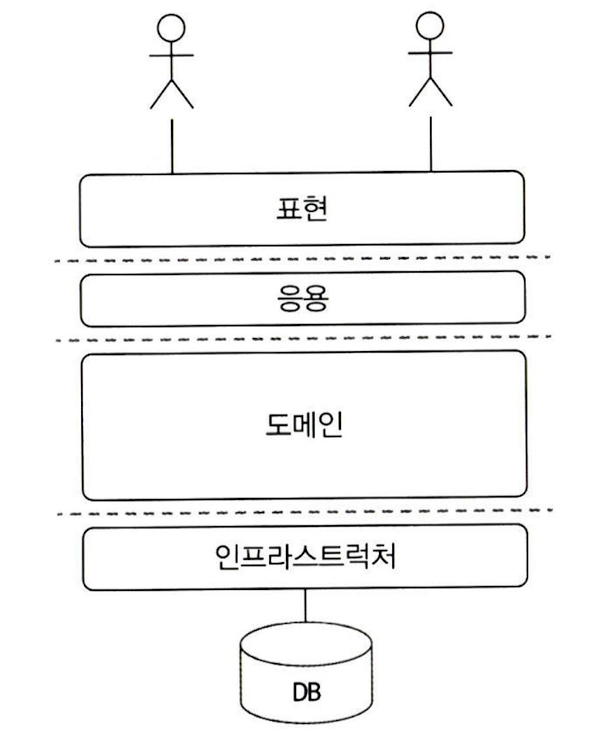
- 아키텍처 상의 도메인 계층을 객체 지향 기법으로 구현하는 패턴
- 마틴파울러, <엔터프라이즈 애플리케이션="" 아키텍처="" 패턴="">엔터프라이즈>
- 계층 구조는 상위 계층에서 하위 계층으로만 의존하는 특성을 가짐 (지름길은 허용)
-
DIP 적용 -> 인프라스트럭처 영역이 응용 영역과 도메인 영역에 의존하는 구조로 변화
- 인프라스트럭처의 클래스가 도메인이나 응용 영역에 정의된 인터페이스를 상속
-
DIP를 항상 적용할 필요 X -> DIP 장점(변경에 유연, 테스트가 쉬움) VS 구현의 편리함 적절히 고려
-
DIP의 장점을 해치지 않는 범위라면 응용 영역과 도메인 영역이 구현 기술을 의존해도 괜찮다
- 응용 영역의 트랜잭션 처리 의존 정도는 괜찮음 (
@Transactional) -
리포지터리와 도메인 모델은 구현기술이 거의 바뀌지 않아 타협도 좋음 (테스트 문제도 X)
- e.g.1 JPA 애너테이션이 적용된 도메인 모델 (
@Entity,@Table) - e.g.2 스프링 데이터 JPA를 상속하는 리포지터리 인터페이스
- e.g.1 JPA 애너테이션이 적용된 도메인 모델 (
- 응용 영역의 트랜잭션 처리 의존 정도는 괜찮음 (
-
DIP의 장점을 해치지 않는 범위라면 응용 영역과 도메인 영역이 구현 기술을 의존해도 괜찮다
-
DIP 적용 -> 인프라스트럭처 영역이 응용 영역과 도메인 영역에 의존하는 구조로 변화
- 구조
- 표현 계층 (Presentation, UI)
- 사용자의 요청을 처리하고 정보를 보여줌
-
데이터 변환 역할
- 요청 데이터를 응용 서비스가 요구하는 알맞은 형태로 변환해 전달
- 실행 결과를 사용자에게 알맞은 형식으로 응답
- 응용 계층 (Application)
- 도메인 계층을 조합해서 사용자가 요청한 기능을 실행
- 주로 오케스트레이션을 하는 계층이어서 단순한 형태를 가짐
- 도메인 기능 예시
- 리포지터리에서 애그리거트를 구한다
- 애그리거트의 도메인 기능을 실행한다
- 결과를 리턴한다
- 새 애그리거트 생성 예시
- 데이터가 유효한지 검사한다 (데이터 중복 등)
- 애그리거트를 생성한다
- 리포지터리에 애그리거트를 저장한다
- 결과를 리턴한다
- 도메인 기능 예시
- 트랜잭션 처리, 접근 제어, 이벤트 처리 등을 담당
- 도메인 계층 (Domain)
- 도메인 모델에 도메인 핵심 규칙을 구현
- 인프라스트럭처 계층 (Infrastructure)
- 외부 시스템과의 연동 처리 (e.g. DB, SMTP, REST, 메시징 시스템)
- 표현 계층 (Presentation, UI)
- 구현 전략
-
인증 및 인가 전략
- URL 이용 인증 및 인가는 서블릿 필터가 좋은 위치 (스프링 시큐리티도 유사하게 동작)
- URL만으로 어려운 경우 응용 서비스의 메서드 단위로 인증 및 인가 수행 (
@PreAuthorize) - 개별 도메인 객체 단위로 필요한 경우, 직접 권한 로직 구현 (심화: 스프링 시큐리티 확장)
- e.g. 게시글 삭제는 본인 또는 관리자 역할을 가진 사용자만 할 수 있다
- 게시글 애그리거트를 로딩해야 권한 검사할 수 있음 (도메인 서비스에 구현)
permissionService.checkDeletePermission(userId, article);
- e.g. 게시글 삭제는 본인 또는 관리자 역할을 가진 사용자만 할 수 있다
-
응용 계층 전략
- 한 도메인과 관련된 기능은 각각 별도의 서비스 클래스로 구현하자.
- 각 클래스 별로 필요한 의존 객체만 포함하므로 코드 품질 유지와 이해에 도움이 됨
- 클래스의 개수가 많아지고 단순 코드 중복은 문제
- 필요 시, 한 응용 서비스 클래스에서 1개 내지 2~3개 기능 정도를 가지도록 허용
-
코드 중복이 신경쓰인다면 별도의 헬퍼 클래스를 둬서 해결
// 각 응용 서비스에서 공통되는 로직을 별도 클래스로 구현 public final class MemberServiceHelper { public static Member findExistingMember(MemberRepository repo, String memberId) { Member member = repo.findById(memberId); if (member == null) throw new NoMemberException(memberId); return member; } } // 공통 로직을 제공하는 메서드를 응용 서비스에서 사용 import static com.myshop.member.application.MemberServiceHelper.*; public class ChangePasswordService { private MemberRepository memberRepository; public void changePassword(String memberId, String curPw, String newPw) { Member member = findExistingMember(memberRepository, memberId); member.changePassword(curPw, newPw); } // ... }
- 응용 계층 전달 데이터가 2개 이상이면 DTO 객체를 사용해 표현 계층에서 자동 변환하면 편리
- e.g. 스프링 MVC 웹 요청 파라미터 자바 객체 변환 기능
- 응용 서비스는 표현 영역에서 필요한 데이터만 리턴하자
- 도메인 객체 리턴하면 도메인 로직을 표현 영역에서 실행할 가능성이 생김
-
요청 값에 대한 검증은 표현 계층 보다 응용 서비스에서 처리하자 (응용서비스 완성도 상승)
- 여러 검증 정보가 한 번에 필요하면, 서비스에서 에러 코드를 모아 1개 예외로 발생시키자
List<ValidationError> errors = new ArrayList<>;if (!errors.isEmpty()) throw new ValidationErrorException(errors);- 표현 영역에서 예외 잡아 변환 -
bindingResult.rejectValue()
- 여러 검증 정보가 한 번에 필요하면, 서비스에서 에러 코드를 모아 1개 예외로 발생시키자
- 조회 전용 기능의 경우 서비스 없이 표현 영역에서 바로 사용해도 괜찮음
- 한 도메인과 관련된 기능은 각각 별도의 서비스 클래스로 구현하자.
-
인증 및 인가 전략
- 요청 처리 흐름
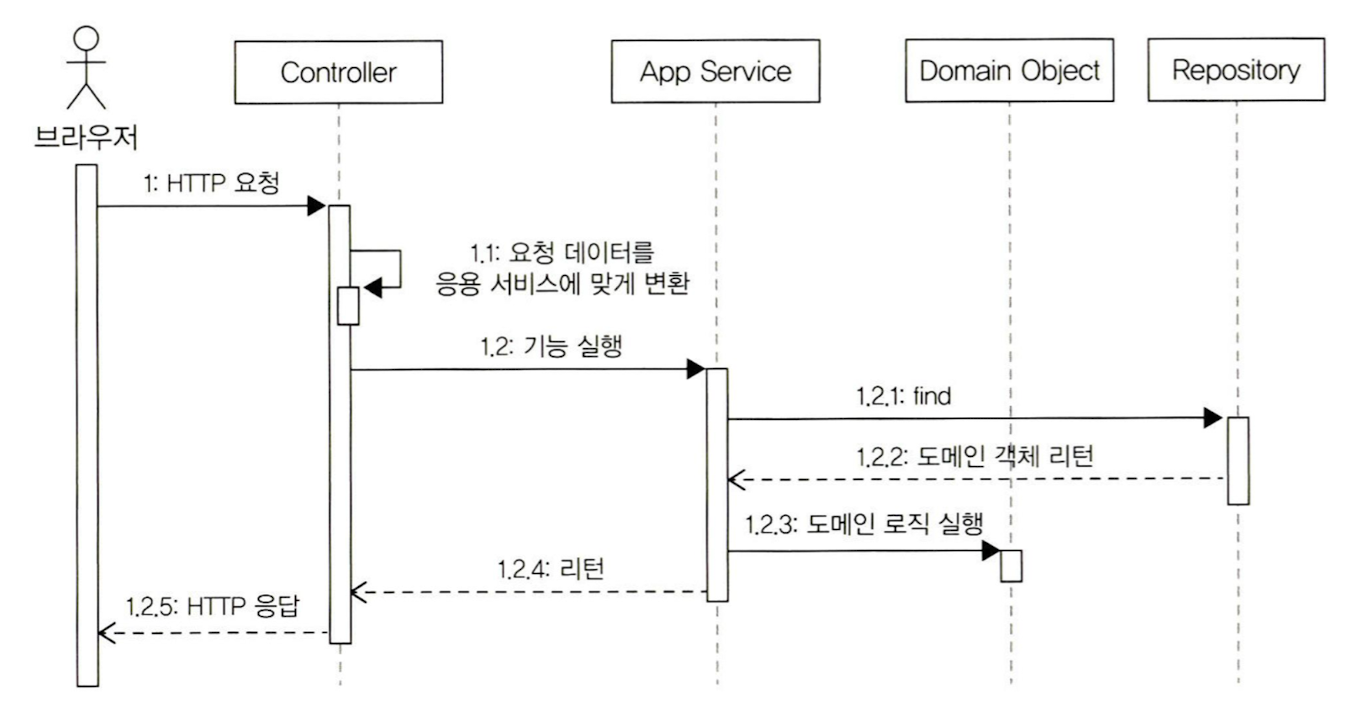
- 패키지 구조
- 한 패키지는 가능한 10~15개 미만으로 타입 개수 유지 (코드 찾기 불편하지 않을 정도)
- 기본 패키지 구성
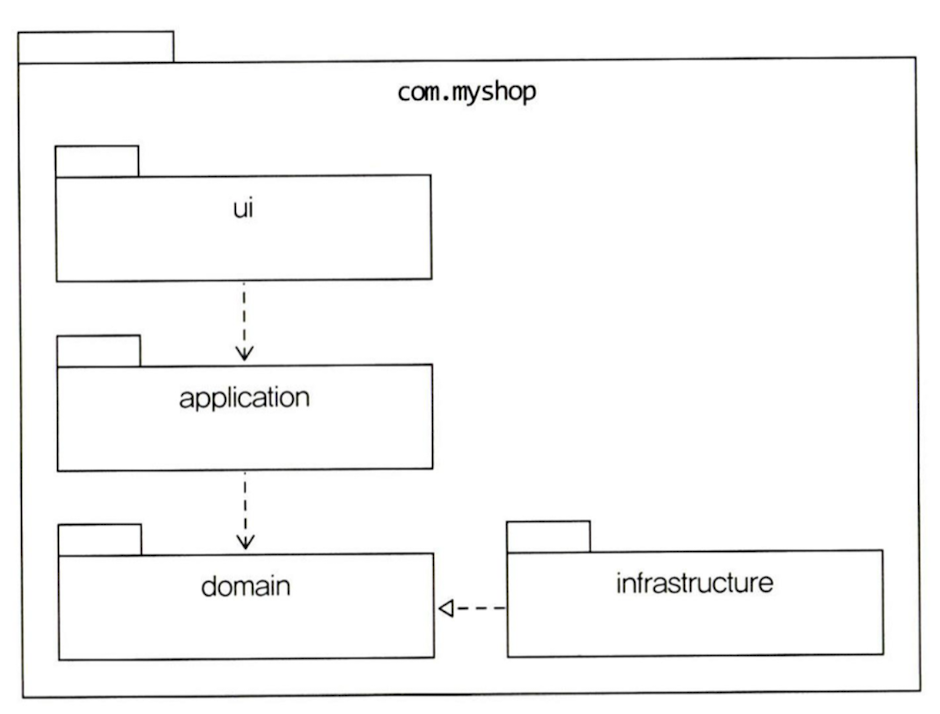
- 도메인이 클 때는 하위 도메인마다 별도로 패키지 구성하자
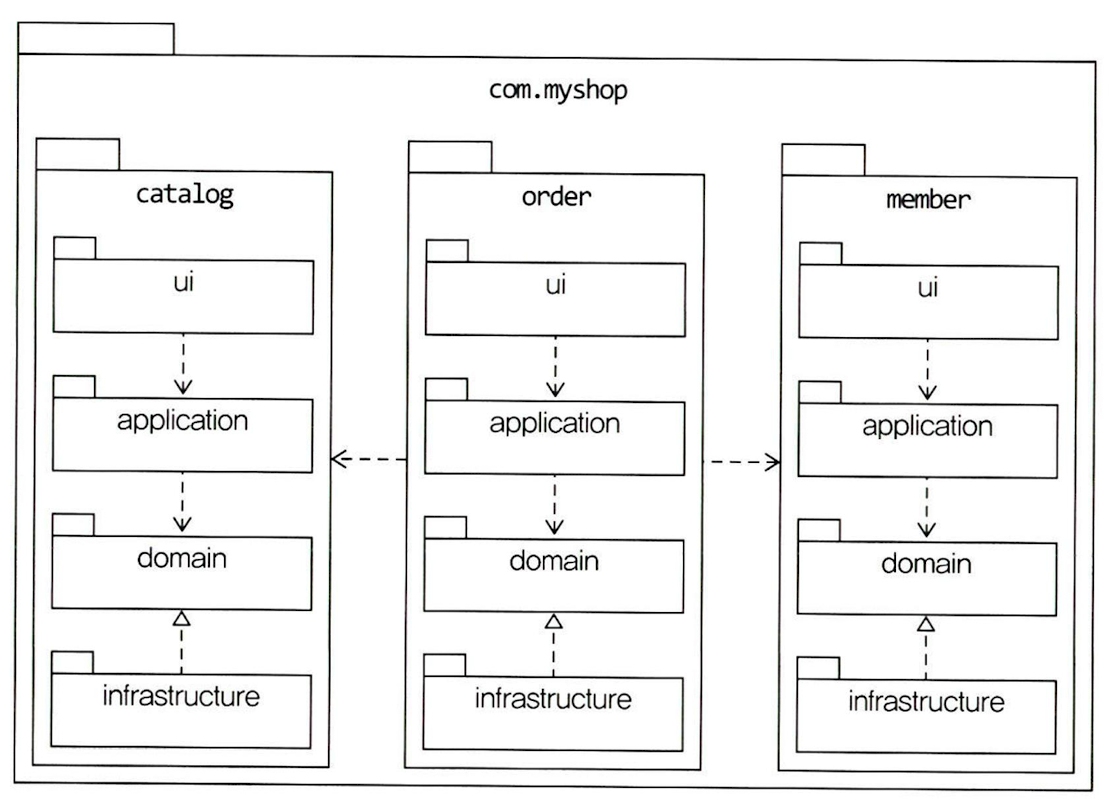
- 각 하위 도메인의 응용 영역과 도메인 영역은 애그리거트 기준으로 나누어 재구성 가능
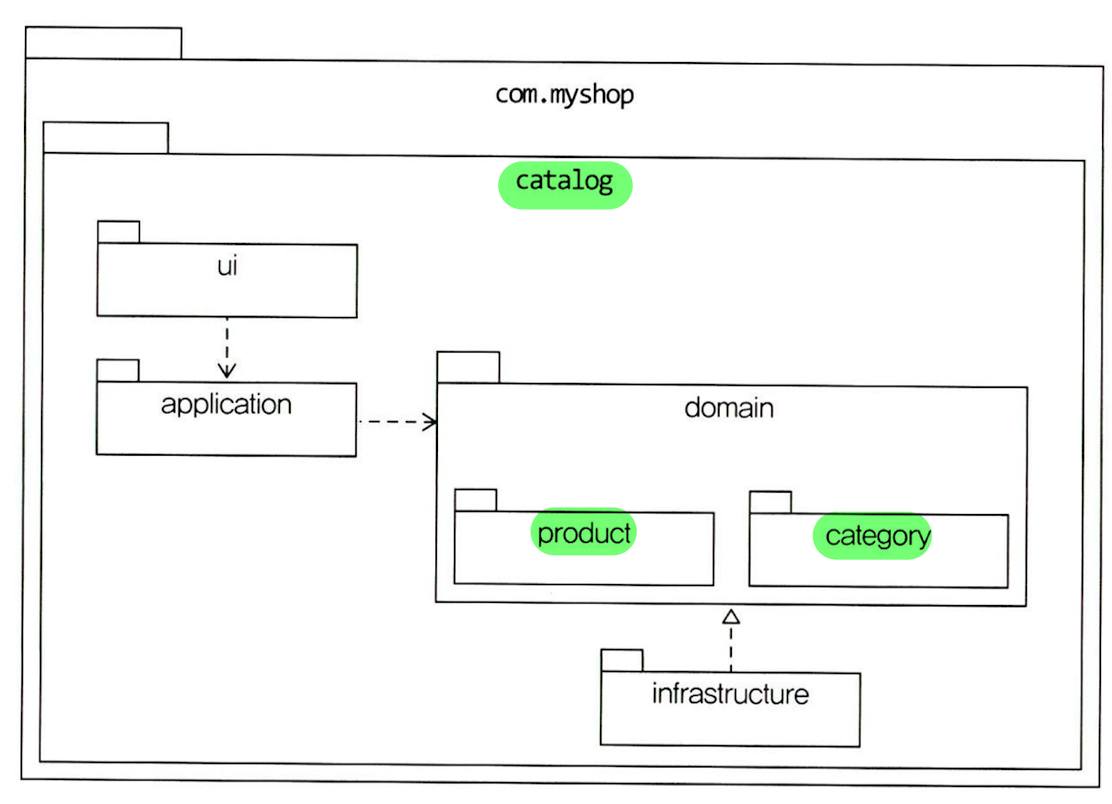
- 애그리거트, 모델, 리포지터리는 같은 도메인 모듈에 위치
- 도메인이 크면 도메인 모델과 도메인 서비스를 별도 패키지로 구분 가능
-
order.domain.order,order.domain.service
-
도메인 영역의 주요 구성요소
엔터티와 밸류 (Entity & Value type)
-
엔터티와 밸류의 구분법: 고유 식별자를 갖는지 확인
- DB 테이블 갖는다고 엔터티는 아님
- 엔터티 식별자와 DB PK 식별자는 다른 것
- e.g.
Article-ArticleContent-
ArticleContent는 밸류이며, DB에 PK가 있지만 도메인에서의 식별자는 아님
-
- e.g.
- 참고: 식별자 구현 위치
- 식별자 생성규칙(도메인 규칙)이 있으면, 도메인 영역에 위치 (e.g. 도메인 서비스, 리포지토리)
-
엔터티
- 고유의 식별자를 갖는 객체
-
식별자가 같으면 두 엔터티는 같다 (
equals()및hashCode()로 구현)
-
식별자가 같으면 두 엔터티는 같다 (
- 자신의 라이프 사이클을 가짐
- 도메인 모델 엔터티와 DB 관계형 모델 엔터티는 서로 다름
- 도메인 모델 엔터티는 데이터와 함께 도메인 기능을 제공
- 도메인 모델 엔터티는 두 개 이상의 데이터가 개념적으로 하나인 경우 밸류로 표현 가능
- RDBMS는 밸류 타입이 표현이 어려움
- 개별 데이터로 저장 -> 개념이 드러나지 않음
- 테이블을 분리해 저장 -> 테이블의 엔터티에 가깝고 밸류라는 의미가 드러나지 않음
- RDBMS는 밸류 타입이 표현이 어려움
- 고유의 식별자를 갖는 객체
-
밸류
- 고유의 식별자를 갖지 않는 객체
-
모든 속성이 같으면 두 밸류 객체는 같다 (
equals()및hashCode()로 구현)
-
모든 속성이 같으면 두 밸류 객체는 같다 (
- 주로 개념적으로 하나인 값을 표현하고 싶거나 의미를 명확하게 표현하고 싶을 때 사용
- ex 1.
Receiver=receiverName+receiverPhoneNumber - ex 2.
Address=shippingAddress1+shippingAddress2+shipppingZipcode - ex 3.
ShippingInfo=Receiver+Address - ex 4.
Money- ‘돈’을 의미하도록 하여 코드 이해에 도움을 줌 - ex 5.
OrderNo- 주문 엔터티의 식별자로 밸류를 사용해 코드 이해에 도움을 줌
- ex 1.
- 엔터티의 속성 혹은 다른 밸류 타입의 속성으로 사용됨
- 기능 추가가 가능하다는 장점이 있음
-
불변(immutable) 으로 설계해야 함
- 데이터 변경 기능 제공 X
- 변경할 때는 새로 밸류 객체를 생성해 반환
- 고유의 식별자를 갖지 않는 객체
- JPA 관련 테크닉
- JPA가 강제하는 엔터티와 벨류 정의 시 필요한 기본 생성자는
protected로 선언하자- 값이 없는 온전치 못한 객체 생성 예방
-
@Access(AccessType.FIELD): 메서드 매핑을 완전히 방지하고 필드 매핑 강제
- 원래 JPA는 메서드에도 컬럼 매핑(AccessType.PROPERTY)이 가능하므로 아얘 막자 - 밸류 매핑
-
@Embedded,@Embeddable: 값 객체 지정 애노테이션 -
@EmbeddedId: 식별자 자체를 밸류 타입으로 지정 (식별자 의미 강조 위해)- JPA는 식별자 타입이
Serializable이어야 하므로, 밸류 타입은 상속 필요 - 기능 추가 가능한 장점 (e.g. 주문 번호 세대 구분)
- JPA는 식별자 타입이
-
@SecondaryTable: 밸류를 별도 테이블로 매핑- 조회 성능이 안좋음 (두 테이블을 조인해서 가져옴) -> 조회 전용 DAO 사용 필수!
- 지연 로딩을 위해 밸류를 엔터티로 매핑할 수도 있지만, 밸류 정체성을 잃어버려서 안좋음
-
@AttributeOverrides: 값 객체의 칼럼 이름이 다른 값 객체의 그것과 서로 다를 때 사용 -
AttributeConverter: 2개 이상의 프로퍼티를 가진 밸류 타입을 1개 컬럼에 매핑 가능-
AttributeConverter인터페이스를 상속해convertToDatabaseColumn(),convertToEntityAttribute()구현한 후, 해당 클래스에@Converter(autoApply = true)적용 -
autoApply = false인 경우 필요한 곳에@Convert(converter = ...)적용 - e.g.
Length클래스(int value,String unit) -> DB 컬럼width
-
-
- 밸류 컬렉션 매핑
-
@ElementCollection,@CollectionTable: 밸류 컬렉션을 별도 테이블로 매핑- e.g.
Order-OrderLines
- e.g.
-
AttributeConverter: 밸류 컬렉션을 한 개 컬럼에 매핑할 때도 사용- e.g. Email 주소 목록 Set (
EmailSet) -> 1개 DB 칼럼에 콤마로 구분해 저장
- e.g. Email 주소 목록 Set (
- 기술적 혹은 팀 표준적 한계로 인해, 밸류를
@Entity로 구현해야 할 수도 있음- e.g. 밸류 타입인데 상속 매핑이 필요한 경우
- 상태 변경 메서드 제거 &
cascade+orphanRemoval=true적용 - 다만, images 리스트의
clear()호출하면 쿼리가 비효율적이어서,@Embeddable로 단일 클래스 구현하고 기능은 타입에 따라 if-else로 구현하는 것도 방법이다!
- 상태 변경 메서드 제거 &
- e.g. 밸류 타입인데 상속 매핑이 필요한 경우
-
-
@SecondaryTable예제@Entity @Table(name = "article") @SecondaryTable( name = "article_content", pkJoinColumns = @PrimaryKeyJoinColumn(name = "id") ) public class Article { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String title; @AttributeOverrides({ @AttributeOverride( name = "content", column = @Column(table = "article_content", name = "content") ), @AttributeOverride( name = "contentType", column = @Column(table = "article_content", name = "content_type") ) }) @Embedded private ArticleContent content; }
- JPA가 강제하는 엔터티와 벨류 정의 시 필요한 기본 생성자는
애그리거트 (Aggregate)
- 연관된 엔터티와 밸류 객체를 개념적으로 하나로 묶은 군집
-
개념상 완전한 1개의 도메인 모델 표현
- e.g. 주문 애그리거트(상위 개념) = Order 엔터티, OrderLine 밸류, Orderer 밸류(하위)
- 보통 대다수의 애그리거트는 1개의 엔터티 객체만으로 구성되며 2개 이상은 드물다
- 루트 엔터티 이외의 엔터티는 실제 엔터티가 맞는지, 맞다면 다른 애그리거트는 아닌지 의심
-
개념상 완전한 1개의 도메인 모델 표현
-
애그리거트를 나누는 기준: 도메인 규칙에 따라 함께 생성 혹은 변경되는 구성 요소인가? (라이프사이클)
- ‘A가 B를 갖는다’ 라는 요구사항이 있어도 A와 B가 다른 애그리거트일 수 있음
- e.g. 상품과 리뷰는 다른 애그리거트 - 변경 주체가 다르고 함께 생성하거나 함께 변경하지 않음
- 특징
- 커져서 복잡해진 도메인 모델을 상위 수준에서 애그리거트 간 관계로 파악 및 관리 가능
- 애그리거트는 도메인 규칙과 요구사항에 따라 경계를 가짐
- 한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않음
- 애그리거트에 속한 객체는 유사하거나 동일한 라이프사이클을 가짐 (대부분 함께 생성 및 제거)
-
일관성을 관리하는 기준이 됨
- 복잡한 도메인 모델을 단순한 구조로 만들어 도메인 기능 확장 및 변경 비용 감소
-
루트 엔터티
- 애그리거트에 속한 전체 객체를 관리하는 엔터티
- 핵심 역할: 애그리거트의 일관성이 깨지지 않도록 하는 것
- 도메인 규칙을 지켜 애그리거트 내 모든 객체가 항상 정상 상태를 유지하도록 함
- e.g.
OrderLine밸류 변경 시,Order엔터티의 주문 총 금액을 함께 변경 - e.g.
changeShippingInfo()는 배송 시작 전에만 배송지를 변경 가능하도록 구현
- 애그리거트의 유일한 진입점 (애그리거트 단위로 내부 구현 캡슐화)
- 애그리거트의 도메인 기능은 루트 엔터티를 통해서만 실행 가능
- 애그리거트 내 엔터티 및 밸류 객체는 루트 엔터티를 통해서만 간접적으로 접근 가능
- 필요한 구현 습관
-
단순한 필드 변경
publicset메서드는 지양하자-
set메서드는 도메인 의도를 표현하지 못함 - 공개
set만 줄여도cancel,change등 의미가 드러나는 메서드 구현 빈도 상승
-
-
밸류 타입은 불변으로 구현하기
- 덕분에 애그리거트 외부에서 밸류 객체에 접근해도 상태 변경은 불가능
- e.g.
- 루트 엔터티는 내부 다른 객체를 조합(참조, 기능 실행 위임)해 기능 구현 완성
-
Order-calculateTotalAmounts() -
OrderLines-ChangeOrderLines() - 혹시
Order가getOrderLines()를 제공해도OrderLines가 불변이면 애그리거트 외부에서 변경이 불가능해 안전하다
- 혹시 불변 구현이 불가능한 경우, 변경 기능을
default(package-private),protected로 제한하면 애그리거트 외부 상태 변경을 방지할 수 있음
- 애그리거트에 영속성 전파 적용하자 (
@OneToMany,@OneToOne)- 애그리거트의 모든 객체는 함께 저장되고 함께 삭제되어야 함
cascade = {CascadeType.PERSIST, CascadeType.REMOVE}orphanRemoval = true
-
@Embeddable은 기본적으로 함께 저장 및 삭제되므로cascade속성 필요 X
- 애그리거트의 모든 객체는 함께 저장되고 함께 삭제되어야 함
-
단순한 필드 변경
-
애그리거트 간 참조
- = 루트 엔터티가 다른 루트 엔터티를 참조하는 것
-
다른 애그리거트를 참조할 때는 ID 참조하자
- 애그리거트 경계가 명확해지고 응집도가 높아짐
-
여러 애그리거트를 읽어야할 때, 조회 속도 문제는 조회 전용 쿼리로 해결 (DAO)
- 여러 애그리거트를 읽어야할 때, 조회 속도 문제 발생할 수 있음 (N + 1)
- e.g. 주문 개수가 10개 - 주문 쿼리 1, 상품 쿼리 10
-
DAO에서 조인을 이용해 1번의 쿼리로 데이터 로딩하자 (e.g.
OrderViewDao, JPQL) - 만약 애그리거트마다 다른 저장소를 사용한다면, 캐시 적용 혹은 조회 전용 저장소 이용
- 코드는 복잡해져도 시스템 처리량 상승
- 여러 애그리거트를 읽어야할 때, 조회 속도 문제 발생할 수 있음 (N + 1)
- 객체 참조는 구현은 편리하지만 단점이 많음
- 다른 애그리거트의 상태를 쉽게 변경할 수 있다는 단점
- 지연로딩/즉시로딩 고민 필요
- 확장 시에도 하위 도메인마다 기술이 달라질 수 있는데 JPA에 종속되어버림
- 애그리거트를 팩토리로 사용하기
- 한 애그리거트의 상태를 보고 다른 애그리거트를 생성해야 한다면 애그리거트에 팩토리 메서드 추가
- e.g.
Store의 상태를 보고Product를 생성한다면,Store에createProduct()추가- 정보가 많다면
Store-createProduct()-ProductFactory.create()도 가능
- 정보가 많다면
- e.g.
- 도메인의 응집도가 높아짐
- 한 애그리거트의 상태를 보고 다른 애그리거트를 생성해야 한다면 애그리거트에 팩토리 메서드 추가
리포지터리 (Repository)
-
애그리거트 단위로 도메인 객체를 조회하고 저장하는 기능 정의 (도메인 모델의 영속성 처리)
- 구현을 위한 도메인 모델 (엔터티와 밸류는 요구사항에서 도출되는 도메인 모델)
-
애그리거트는 개념적으로 하나이므로 저장할 때도 전체를 저장하고, 불러올 때도 전체를 불러와야 함
- 원자적 변경 구현: RDBMS는 트랜잭션 사용, 몽고 DB는 한 애그리거트를 한 문서에 저장
- 응용 서비스 계층이 사용 주체
- 리포지터리 인터페이스는 도메인 영역, 구현 클래스는 인프라스트럭처 영역에 속함
- 기본 정의 메서드 (애그리거트 저장 및 조회)
save(Some some)findById(SomeId id)- 필요에 따라 다양한 조건의 검색이나
delete(id)나count()추가
리포지터리와 DAO
리포지터리와 DAO는 데이터를 DB로 부터 가져온다. 둘은 목적이 같지만 의미에서 차이가 있다.
CQRS에서 명령 모델에서 사용할 때는 리포지터리라고 지칭하고, 조회 모델에서 사용할 때는 DAO라고 지칭한다.
스프링 데이터 JPA Specification
DAO 구현 시 다양한 조건 검색에는 Specification을 사용이 도움이 된다.
하이버네이트
@Subselect쿼리 결과를
@Entity로 매핑할 수 있는 기능으로, 마치 뷰를 사용하는 것 처럼 쿼리 실행 결과를 매핑할 테이블처럼 사용할 수 있다.@Immutable,@Synchronize를 함께 사용하자.
도메인 서비스 (Domain Service)
- 한 애그리거트만으로는 구현이 불가능한 특정 엔터티에 속하지 않는 도메인 로직을 처리
- 여러 애그리거트가 필요한 기능을 억지로 한 애그리거트에 넣으면 안된다
- 코드가 복잡하고 외부 의존이 높아져 수정이 어려움
- 애그리거트의 범위를 넘어서는 도메인 개념이 애그리거트에 숨어들어 명시적으로 드러나지 않게 됨
-
계산 로직 & 외부 시스템 연동이 필요한 도메인 로직에 사용
- 계산 로직 (e.g. 실제 결제 금액 계산)
- 총 주문 금액은 주문 애그리거트에서 가능
- But, 할인 금액 계산은 상품, 쿠폰, 회원 등급, 구매 금액 등이 필요
- 나아가 2개의 할인 쿠폰 적용은 단일 할인 쿠폰 애그리거트로 처리 불가
-
public class DiscountCalculationService {...}public Money calculateDiscountAmounts(List<OrderLines>, List<Coupon> coupons, MemberGrade grade)
- 외부 시스템 연동 도메인 로직 (e.g. 설문 조사 시스템이 외부 역할 관리 시스템과 연동해야 할 때)
- 설문 조사 생성 권한이 있는지 확인하는 것은 도메인 규칙
- 외부 연동 보다는 도메인 로직 관점에서 인터페이스 작성 - 응용 서비스에서 사용
-
public interface SurveyPermissionCheckerboolean hasUserCreationPermission(String userId)
- 인터페이스는 도메인 영역, 구현 클래스는 인프라스트럭처 영역에 위치
- 계산 로직 (e.g. 실제 결제 금액 계산)
- 구현 및 사용 방법
- 상태 없이 로직만 구현 (엔터티, 밸류 등과의 차이)
-
사용 주체는 애그리거트 혹은 응용 서비스 둘 다 가능
- e.g. 결제 금액 계산:
Order-calculateAmounts(DiscountCalculationService disCalSvc, MemberGrade grade) - e.g. 계좌 이체:
TransferService(도메인 서비스) -transfer(Account fromAcc, Account toAcc, Money amounts)
- e.g. 결제 금액 계산:
- 도메인 서비스는 도메인 영역에 위치
- e.g. 실제 계산 금액 도메인 서비스는 주문 애그리거트와 같은 패키지에 위치
-
domain.model,domain.service,domain.repository로 분할해도 괜찮음
- 도메인 로직이 외부 시스템을 이용해 구현될 때는 인터페이스와 클래스를 분리하자
- 도메인 서비스 인터페이스 (도메인 영역) - 도메인 서비스 구현 클래스 (인프라스트럭처 영역)
애그리거트와 트랜잭션
-
트랜잭션 구현 전략
-
1개의 트랜잭션에서는 1개의 애그리거트만 수정하자
- 트랜잭션 범위는 작을수록 좋다 (1개 테이블 한 행 잠금이 3개 테이블 잠금보다 처리량 높음)
- 2개 이상의 애그리거트 수정 -> 트랜잭션 충돌 가능성 상승 -> 처리량 감소
- 부득이하게 1개 트랜잭션으로 2개 이상의 애그리거트 수정이 필요할 경우 응용 서비스에서 수정
- 다음 상황에서만 허용
- 기술적으로 도메인 이벤트를 사용할 수 없거나 팀 표준인 경우
- UI 구현의 편리 - 운영자의 편의를 위해 여러 주문의 상태를 한 번에 변경하고 싶을 때
- 다음 상황에서만 허용
- 도메인 이벤트 사용 -> 1 트랜잭션 1 애그리거트 수정한 후 다른 애그리거트 수정 가능 (동기, 비동기)
-
1개의 트랜잭션에서는 1개의 애그리거트만 수정하자
- 애그리거트를 위한 추가적인 트랜잭션 처리 기법 (잠금)
- 애그리거트 간 동시성 문제 제어를 위해 필요
- e.g. 운영자와 고객이 동시에 논리적으로 같은 애그리거트에 접근하지만 물리적으로 다른 애그리거트 객체를 사용하게 되어 동시성 문제 발생
- 종류
- 선점 잠금 (Pessimistic Lock)
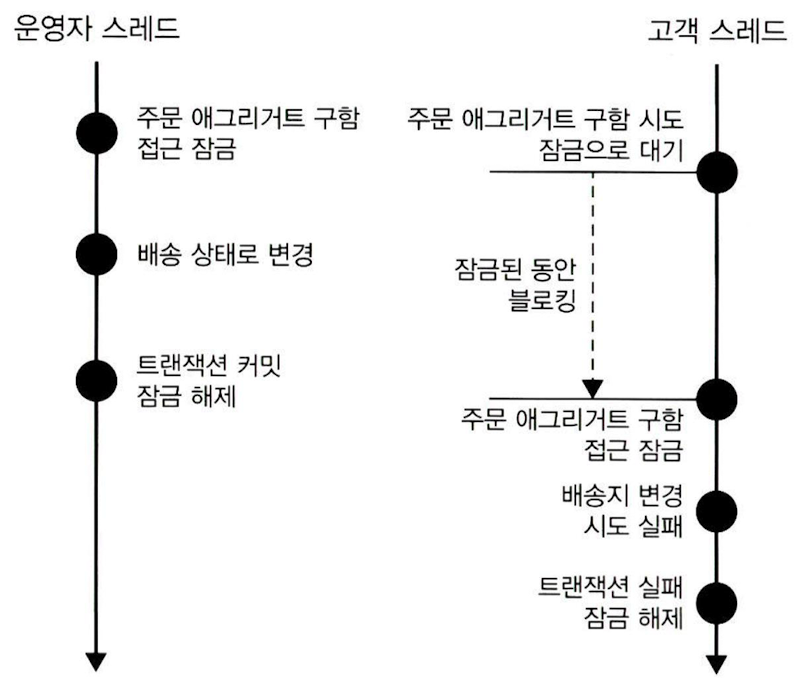
-
한 스레드의 애그리거트 사용이 끝날 때까지 다른 스레드의 해당 애그리거트 수정을 막음
- e.g. 운영자가 배송지 정보를 조회하고 상태를 변경하는 동안, 고객의 애그리거트 수정을 막는다
- 구현:
for update쿼리 (DBMS 지원 행단위 잠금/특정 레코드에 한 커넥션만 접근 가능)- JPA (하이버네이트)
- EntityManger의
find()메서드에LockModeType.PESSIMISTIC_WRITE인자 전달 - e.g.
entityManager.find(Order.class, orderNo, LockModeType.PESSIMISTIC_WRITE)
- EntityManger의
- 스프링 데이터 JPA
-
@Lock(LockModeType.PESSIMISTIC_WRITE)지정
-
- JPA (하이버네이트)
- 주의점: 교착 상태 예방을 위해 최대 대기 시간 지정 필요 (DBMS마다 지원 여부 다름)
- JPA
Map<String, Object> hints = new HashMap<>(); hints.put("javax.persistence.lock.timeout", 2000); Order order = entityManager.find( Order.class, orderNo, LockModeType.PESSIMISTIC_WRITE, hints ); - 스프링 데이터 JPA
@QueryHints({ @QueryHint(name = "javax.persistence.lock.timeout", value = "2000") })
- JPA
-
한 스레드의 애그리거트 사용이 끝날 때까지 다른 스레드의 해당 애그리거트 수정을 막음
- 비선점 잠금 (Optimistic Lock)
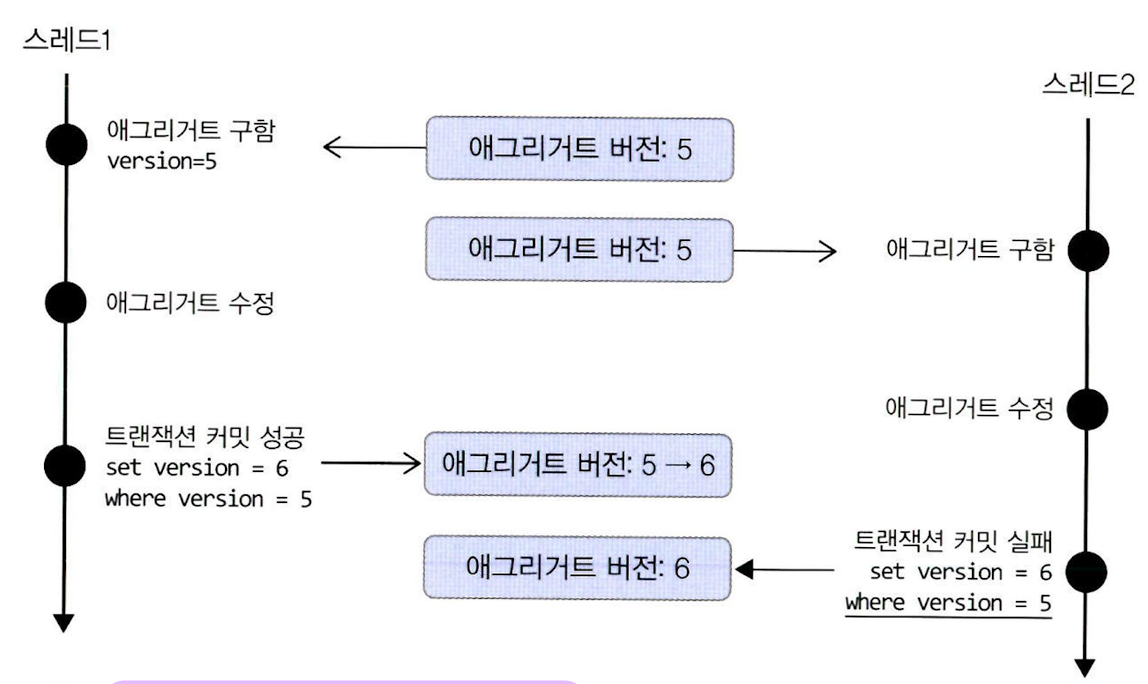
-
버전 값을 사용해서 변경 가능 여부를 실제 DBMS 변경 반영 시점에 확인하는 방법
- e.g. 운영자가 배송지 정보를 조회한 이후에 고객이 정보를 변경하면, 운영자가 애그리거트를 다시 조회한 후 수정하도록 한다
-
선점 잠금으로 해결할 수 없는 경우를 해결
- 사용자가 버전 값을 응답 받고 다음 요청에 버전 값을 함께 보내는 방식
- 덕분에 여러 트랜잭션이나 시간에 걸쳐 락 확장 가능
- 구현: 쿼리에서 애그리거트의 버전이 동일한 경우에만 수정하고 성공하면 버전값도 올리기
- 쿼리
UPDATE aggtable SET version = version + 1, colx = ?, coly = ? WHERE aggid = ? and version = 현재버전
- JPA
-
@Version private long version(필드에 애너테이션 적용)- 트랜잭션 충돌 시
OptimisticLockingFailureException발생
- 트랜잭션 충돌 시
-
- 쿼리
- 주의점: 강제 버전 증가 잠금 모드 필요 (for 애그리거트 일관성 유지)
- 애그리거트에서 일부 구성요소의 값만 바뀌어도 루트 엔터티 버전 값을 증가시키자
- JPA
- EntityManger의
find()메서드에LockModeType.OPTIMISTIC_FORCE_INCREMENT인자 전달 - 엔터티 상태 변경 여부와 상관없이 트랜잭션 종료 시점에 버전 값 증가 처리
- EntityManger의
- 스프링 데이터 JPA
-
@Lock(LockModeType.OPTIMISTIC_FORCE_INCREMENT)지정
-
-
버전 값을 사용해서 변경 가능 여부를 실제 DBMS 변경 반영 시점에 확인하는 방법
- 오프라인 선점 잠금 (Offline Pessimistic Lock)
- 선점 잠금과 달리 여러 트랜잭션에 걸쳐 동시 변경을 막는 방식
- e.g. 누군가 수정 화면을 보고 있을 때, 수정 화면 자체를 실행하지 못하게 막음
- 구현: 락 직접 구현
- 애플리케이션 단 락 구현 (
LockManger) - DB 단 락 구현 (테이블)
- 애플리케이션 단 락 구현 (
- 주의점
- 락을 얻은 사용자가 영원히 반납하지 않는 경우를 고려해 잠금 유효 시간 필요
- 락을 얻은 사용자는 일정 주기로 유효 시간을 증가시켜야 UX 불편 없이 수정 가능
- 수정 폼에서 1분 단위로 Ajax 호출해 1분씩 유효 시간 증가시키기
- 선점 잠금과 달리 여러 트랜잭션에 걸쳐 동시 변경을 막는 방식
- 선점 잠금 (Pessimistic Lock)
- 애그리거트 간 동시성 문제 제어를 위해 필요
이벤트 (Event)
문제점: 바운디드 컨텍스트 간에는 강결합이 발생한다
- e.g. 주문 B.C와 결제 B.C 간의 강결합 (환불 기능의 강결합)
- 환불 기능 구현 2가지 방법
-
Order엔터티의cancel()에RefundService도메인 서비스를 파라미터 넘겨 실행 - 응용 서비스에서
Order엔터티의cancel()과RefundService의refund()실행
-
- 환불은 외부 결제 API에 의존, 도메인 서비스가 필요
-
-
외부 의존으로 생기는 문제점
- 트랜잭션 처리 문제
- 외부결제시스템이 비정상이라 예외가 발생하면, 트랜잭션을 롤백할지 커밋할지 애매
- 환불 실패시 롤백하는 것이 맞아보이지만, 반드시 롤백해야 하는 것은 아님
-
주문은 취소 상태로 변경하고 환불만 나중에 다시 시도하는 방식도 가능
- 성능 문제
- 외부 결제 시스템의 응답 시간이 길어지면 대기 시간도 길어져 성능 문제 발생
-
외부 의존으로 생기는 문제점
-
-
설계상 문제점: 도메인 객체에 도메인 서비스를 전달할 때 도메인 로직이 뒤섞임 (강결합)
- 변경의 이유가 증가
- 주문 도메인에 결제 도메인의 환불 관련 로직이 뒤섞임
- 주문 도메인 객체의 코드가 결제 도메인 때문에 변경될 수 있음
-
기능 추가 시 로직이 더욱 섞임
- 주문취소 및 환불에 통지 기능을 추가하면,
NotiService도 파라미터로 넘김 - 로직이 더욱 섞여 트랜잭션 처리가 복잡해지고 외부 서비스가 2개로 증가
- 주문취소 및 환불에 통지 기능을 추가하면,
-
설계상 문제점: 도메인 객체에 도메인 서비스를 전달할 때 도메인 로직이 뒤섞임 (강결합)
- 환불 기능 구현 2가지 방법
이벤트 (해결책)
-
과거에 벌어진 어떤 것 => 상태 변경
- e.g. 암호를 변경했음, 주문을 취소했음
-
“~할 때”, “~가 발생하면”, “만약 ~하면” 같은 요구사항 -> 이벤트 구현 가능
- 도메인의 상태 변경과 관련되는 경우가 많음
- e.g. 주문을 취소할 때, 이메일을 보낸다. (앞: 이벤트, 뒤: 후속 처리)
- 효과
-
도메인 로직이 섞이지 않아 바운디드 컨텍스트 간 강결합을 크게 해소 (변경 및 기능 확장 용이)
- e.g. 주문 도메인의 결제 도메인 의존을 제거
- e.g. 구매 취소 시 이메일 보내기 기능을 추가하더라도 구매 취소 로직은 수정할 필요 X
-
도메인 로직이 섞이지 않아 바운디드 컨텍스트 간 강결합을 크게 해소 (변경 및 기능 확장 용이)
- 용도
-
트리거
- 도메인의 상태가 바뀔 때 후처리 실행
- e.g. 주문 취소 이벤트 -> 환불 처리, 예매 완료 이벤트 -> SMS 발송
- 시스템 간의 데이터 동기화
- e.g. 배송지 변경 이벤트 -> 핸들러는 외부 배송 서비스와 배송지 정보 동기화
-
트리거
관련 구성요소 (도메인 모델에 이벤트 도입 시)
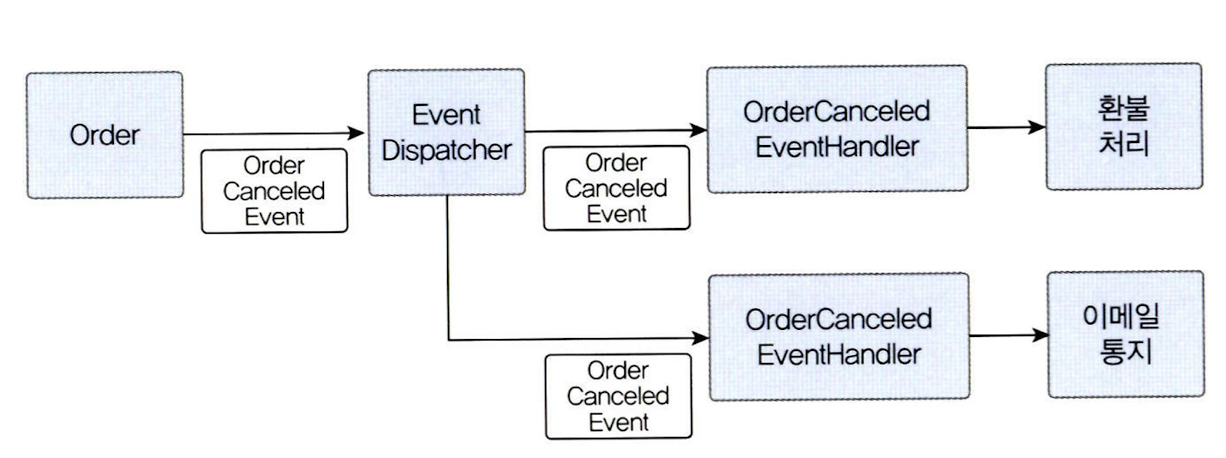
-
이벤트
- 발생한 이벤트에 대한 정보를 담음
- 클래스 이름으로 이벤트 종류 표현
- 이벤트 발생 시간
- 이벤트와 관련된 추가 데이터 (e.g. 주문 번호, 신규 배송지 정보)
- 구현
- 일반 클래스 사용 (과거시제로 명명 e.g.
ShippingInfoChangedEvent)- 공통 프로퍼티가 있다면 상위 이벤트 클래스를 만들어도 괜찮음 (e.g. 발생 시간)
- 이벤트 처리에 필요한 최소한의 정보만 포함
- 일반 클래스 사용 (과거시제로 명명 e.g.
- 발생한 이벤트에 대한 정보를 담음
-
이벤트 생성 주체
- 도메인 객체(엔터티, 밸류, 도메인 서비스)가 주체
- 도메인 로직 실행으로 상태가 변경되면 관련 이벤트를 발생시킴
- 구현
-
Events: 이벤트 발행 래퍼 클래스 구현 (ApplicationEventPublisher를 이용)public class Events { private static ApplicationEventPublisher publisher; static void setPublisher(ApplicationEventPublisher publisher) { Events.publisher = publisher; } public static void raise(Object event) { if (publisher != null) { publisher.publishEvent(event); } } }-
Events.raise(...): 이벤트를 디스패처에 전달 - 설정 컴포넌트에서 파라미터 전달하고 빈 등록
-
-
-
이벤트 디스패처 (퍼블리셔)
-
이벤트 생성 주체와 이벤트 핸들러를 연결
- 이벤트 생성 주체는 이벤트를 생성해서 디스패처에 전달
- 디스패처는 해당 이벤트를 처리할 수 있는 핸들러에 이벤트를 전파
- 이벤트 생성과 처리는 디스패처 구현 방식에 따라 동기 혹은 비동기로 실행됨
- 구현
-
ApplicationEventPublisher이용 (스프링 제공)
-
-
이벤트 생성 주체와 이벤트 핸들러를 연결
-
이벤트 핸들러 (구독자)
- 발생한 이벤트에 반응
- 이벤트를 전달받고 담긴 데이터를 이용해서 원하는 기능을 실행
- 구현
-
@EventListener(이벤트.class): 이벤트 수신- 이벤트 발생 시 해당 애너테이션이 붙은 메서드를 모두 찾아 실행
-
이벤트 처리 방식
- 동기 이벤트 처리
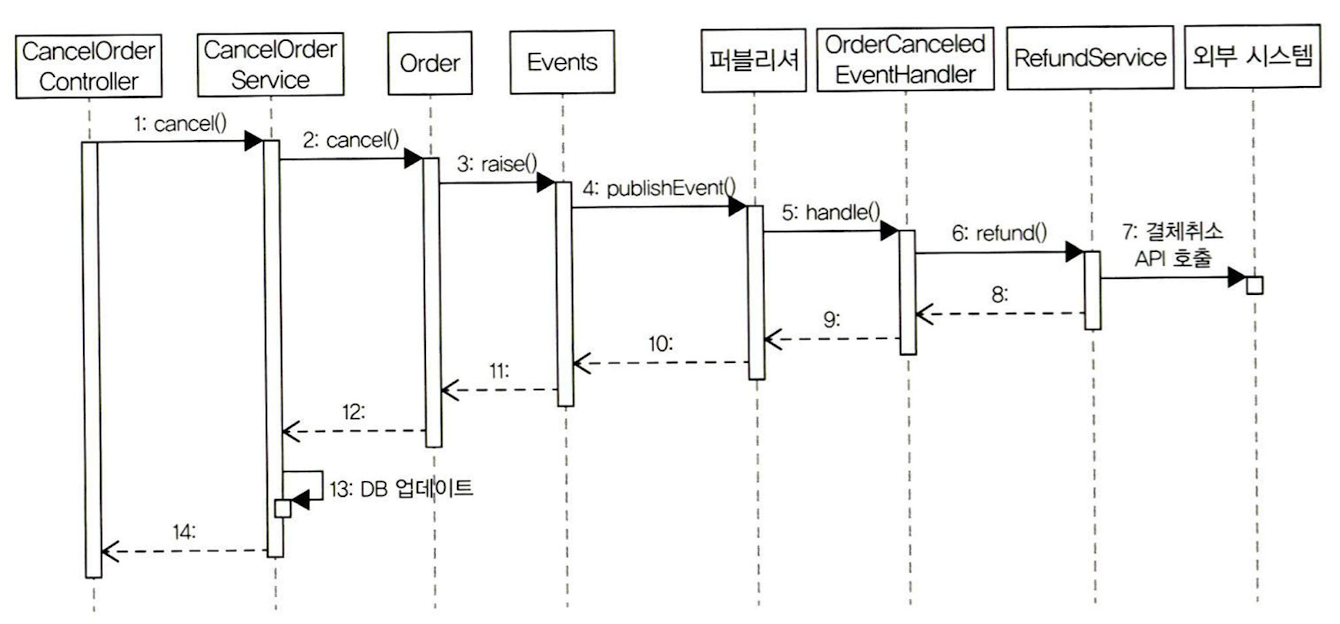
- 응용 서비스와 동일한 트랜잭션 범위에서 이벤트 핸들러 실행 (순차적)
- 도메인 상태 변경과 이벤트 핸들러는 같은 트랜잭션 범위에서 실행
- 문제점: 외부 서비스 영향 문제
- 이벤트를 사용해 강결합 문제는 해결했지만, 외부 서비스 영향 문제는 여전히 남아 있음
- = 트랜잭션 처리 문제 및 성능 문제
- 2가지 해결책: 비동기 이벤트 처리 or 이벤트와 트랜잭션 연계
- e.g.
-
외부 환불 시스템이 실패했다고 반드시 트랜잭션을 롤백해야 할까?
- 구매 취소는 처리하고 환불만 재처리 혹은 수동 처리하는 것도 가능한 방법!
- 즉, 주문 취소 후 수십초 내에 결제 취소가 이루어지면 됨!
- 마찬가지로, 회원 가입 신청 후 몇 초 뒤에 이메일이 도착해도 문제 없음!
- 실패 시 사용자는 이메일 재전송 요청을 이용해 수동으로 인증 메일 다시 받음
-
외부 환불 시스템이 실패했다고 반드시 트랜잭션을 롤백해야 할까?
- e.g.
- 응용 서비스와 동일한 트랜잭션 범위에서 이벤트 핸들러 실행 (순차적)
-
비동기 이벤트 처리
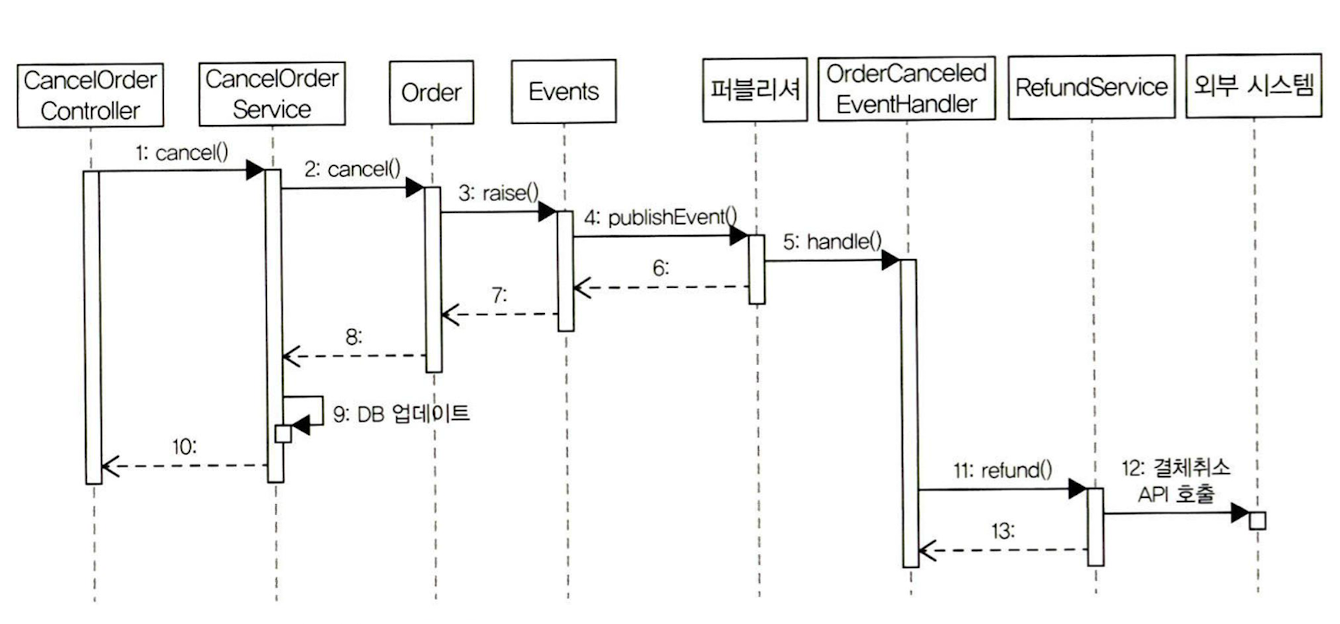
- 요구사항: ‘A 하면 이어서 B 하라’ -> ‘A하면 최대 언제까지 B하라‘인 경우가 많음
- 즉, 대부분 일정 시간 안에만 후속 조치 처리하면 되는 경우가 많음
- B를 실패하면 일정 간격으로 재시도하거나 수동 처리해도 상관 없음
- ‘A하면 최대 언제까지 B하라‘로 바꿀 수 있는 요구사항은 비동기 이벤트 처리로 구현 가능
- 방법: A 이벤트가 발생하면 별도 스레드로 B를 수행하는 핸들러 실행
- 구현 방법
-
로컬 핸들러를 비동기로 실행하기
-
main함수가 있는 클래스에@EnableAsync적용해 비동기 기능 활성화 - 이벤트 핸들러 메서드에
@Async적용 (=이벤트 핸들러를 별도 스레드로 비동기 실행)
-
-
메시지 큐 사용하기 (Kafka or RabbitMQ)
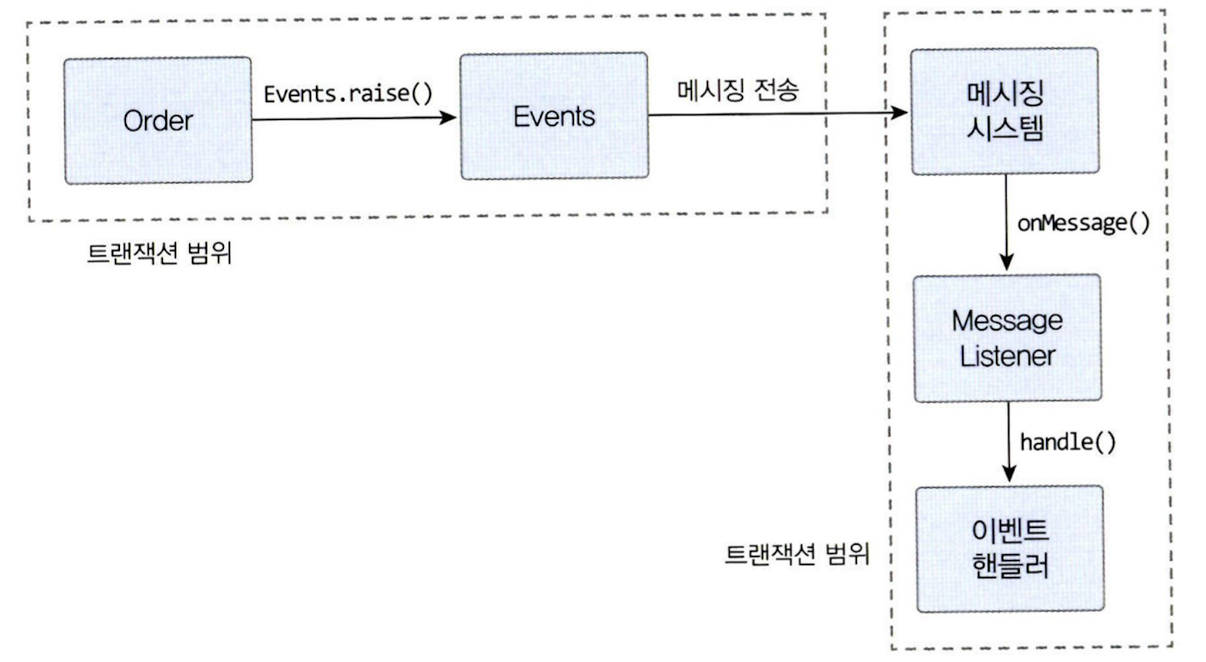
- 보통 이벤트 생성 주체와 이벤트 핸들러는 별도 프로세스에서 동작
- 이벤트 발생 JVM과 이벤트 처리 JVM이 다름
- 동일 JVM에서 비동기를 위해 메시지 큐를 사용할 수 있지만 시스템만 복잡해짐
- 과정 (별도의 스레드나 프로세스로 처리)
- 이벤트가 발생하면 이벤트 디스패처는 이벤트를 메시지 큐로 보냄
- 메시지 큐는 이벤트를 메시지 리스너에 전달
- 메시지 리스너는 알맞은 이벤트 핸들러를 이용해 이벤트 처리
-
글로벌 트랜잭션 (Optional)
- 필요시 도메인 기능과 메시지 큐 이벤트 저장 절차를 한 트랜잭션으로 묶을 수 있음
- e.g. 같은 트랜잭션 범위: 도메인 상태변화 DB 반영 & 이벤트 메시지 큐 저장
- 장점: 이벤트를 안전하게 메시지 큐에 전달 가능
- 단점: 전체 성능 감소, 글로벌 트랜잭션을 지원하지 않는 메시지 시스템 존재
- 필요시 도메인 기능과 메시지 큐 이벤트 저장 절차를 한 트랜잭션으로 묶을 수 있음
- RabbitMQ: 글로벌 트랜잭션 지원 O, 안정적 메시지 전달 (클러스터 및 고가용성 지원)
- Kafka: 글로벌 트랜잭션 지원 X, 높은 성능
- 보통 이벤트 생성 주체와 이벤트 핸들러는 별도 프로세스에서 동작
-
이벤트 저장소(Event Store)를 이용한 비동기 처리 (DB)
- 이벤트를 DB에 저장한 뒤 별도 프로그램을 이용해 이벤트 핸들러에 전달
-
동일한 DB에서 도메인의 상태와 이벤트를 저장
- 도메인 상태 변화와 이벤트 저장이 로컬 트랜잭션으로 처리됨 (한 트랜잭션)
- 트랜잭션에 성공하면 이벤트가 저장소에 보관되는 것을 보장
- 장점
- 물리적 저장소에 이벤트를 저장하므로, 이벤트 핸들러가 처리에 실패해도 다시 저장소에서 읽어와 실행 가능
- 구현
- 이벤트 저장소와 이벤트 포워더 사용하기
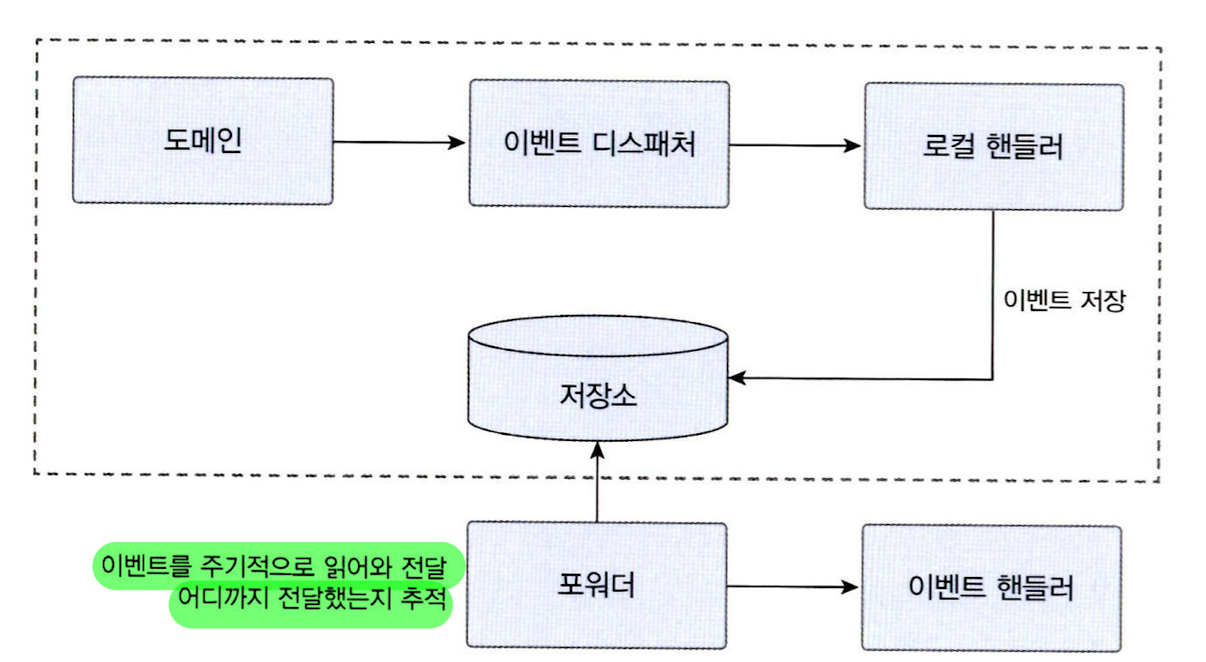
-
포워더가 주기적으로 이벤트 저장소에서 이벤트를 가져와 이벤트 핸들러 실행
- 포워더는 별도의 스레드 이용
-
@Scheduled로 주기적으로 이벤트를 읽고 전달
- 이벤트를 어디까지 처리했는지 이벤트 포워더가 추적해야 함
- DB 테이블이나 로컬 파일에 마지막
offset값 보관
- DB 테이블이나 로컬 파일에 마지막
-
포워더가 주기적으로 이벤트 저장소에서 이벤트를 가져와 이벤트 핸들러 실행
- 이벤트 저장소와 이벤트 제공 API 사용하기
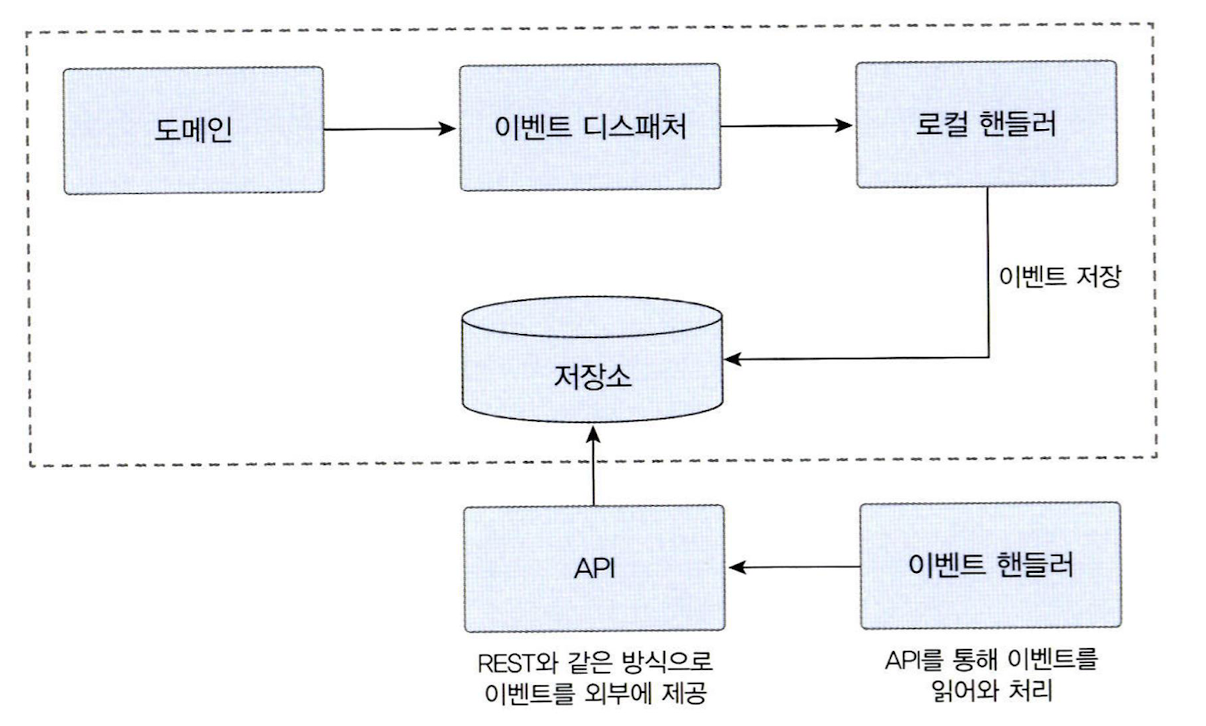
- 외부 핸들러가 API 서버를 통해 이벤트 목록을 가져감
- 어디까지 처리했는지 이벤트 목록을 요구하는 외부 핸들러가 기억해야 함
-
lastOffset: 마지막에 처리한 데이터의offset을 기억
-
- 이벤트 저장소와 이벤트 포워더 사용하기
-
로컬 핸들러를 비동기로 실행하기
- 요구사항: ‘A 하면 이어서 B 하라’ -> ‘A하면 최대 언제까지 B하라‘인 경우가 많음
이벤트 적용 추가 고려사항
-
이벤트 발생 주체를
EventEntry에 추가할지 여부- e.g “Order가 발생시킨 이벤트만 조회하기” 기능이 필요하다면 이벤트 발생 주체 정보를 추가
- 포워더에서 전송 실패를 얼마나 허용할 것인지
- 특정 이벤트에서 계속 전송에 실패하면, 해당 이벤트 때문에 나머지 이벤트를 전송할 수 없게됨
-
실패한 이벤트의 재전송 횟수 제한을 두자
- e.g. 동일 이벤트 전송 3회 실패 시, 해당 이벤트를 생략하고 다음 이벤트로 넘어가는 정책
-
처리 실패 이벤트를 별도 실패용 DB나 메시지 큐에 저장하는 것도 좋음
- 물리적 저장소에 남겨두면 실패 이유 분석이나 후처리에 도움이 됨
-
이벤트 손실
- 이벤트 저장소 사용 방식은 이벤트 저장을 보장 (도메인 로직과 한 트랜잭션에서 실행됨)
- 반면, 로컬 핸들러 방식은 이벤트 처리에 실패하면 이벤트를 유실하게 됨
-
이벤트 순서
- 이벤트 저장소: 이벤트 발생 순서대로 처리 가능
- 메시징 시스템: 기술에 따라 이벤트 발생 순서와 메시지 전달 순서가 다를 수 있음
- (동일한) 이벤트 재처리
- 마지막으로 처리한 이벤트의 순번을 기억하고 이미 처리한 순번의 이벤트가 도착하면 무시하기
- e.g.
- 회원 가입 신청 이벤트가 처음 도착하면 이메일을 발송
- 동일 순번 이벤트가 다시 들어오면 이메일 발송 X
- e.g.
- 이벤트를 멱등으로 처리
- 동일 이벤트를 한 번 적용하나 여러 번 적용하나 시스템이 같은 상태가 되도록 핸들러 구현
- 시스템 장애로 동일 이벤트 중복 발생이나 처리가 발생해도 부담이 감소
- e.g.
- 배송지 정보 변경 이벤트를 받아서 주소를 변경하는 핸들러
- 마지막으로 처리한 이벤트의 순번을 기억하고 이미 처리한 순번의 이벤트가 도착하면 무시하기
-
DB 트랜잭션 실패와 이벤트 처리 실패
- 동기든 비동기든 트랜잭션 실패와 이벤트 처리는 함께 고려해야 함
- 다만, 경우의 수가 복잡하다
- e.g. 주문 취소 상태 변경과 결제 외부 API 환불 처리 실패 시나리오 예시
- 동기: 결제 취소 API 호출이 완료됐는데, DB 트랜잭션에 실패해 취소 상태가 안됨
- 비동기: 주문은 취소 상태로 DB 반영 됐는데, 결제는 취소되지 않음
- e.g. 주문 취소 상태 변경과 결제 외부 API 환불 처리 실패 시나리오 예시
-
경우의 수 줄이기: 트랜잭션이 성공할 때만 이벤트 핸들러를 실행하도록 처리
- 트랜잭션 실패 경우의 수가 줄어 이벤트 처리 실패만 고민하면 됨
- 이벤트 핸들러를 실행했는데, 트랜잭션이 롤백되는 상황은 없어짐!
- 방법
-
@TransactionalEventListener적용- 스프링 트랜잭션 상태에 따라 이벤트 핸들러를 실행할 수 있게 해줌
-
@TransactionalEventListener(classes = OrderCanceledEvent.class, phase = TransactionPhase.AFTER_COMMIT)(TransactionPhase.AFTER_COMMIT)- 스프링은 트랜잭션 커밋에 성공한 뒤, 핸들러 메서드를 실행
- 중간에 예외 발생으로 롤백 시, 핸들러 메서드 실행 X
- 이벤트 저장소로 DB를 사용하는 것도 동일한 효과 발생
- 트랜잭션 성공할 때만 이벤트가 DB에 저장되므로
-
- 트랜잭션 실패 경우의 수가 줄어 이벤트 처리 실패만 고민하면 됨
CQRS (Command Query Responsibility Segregation)
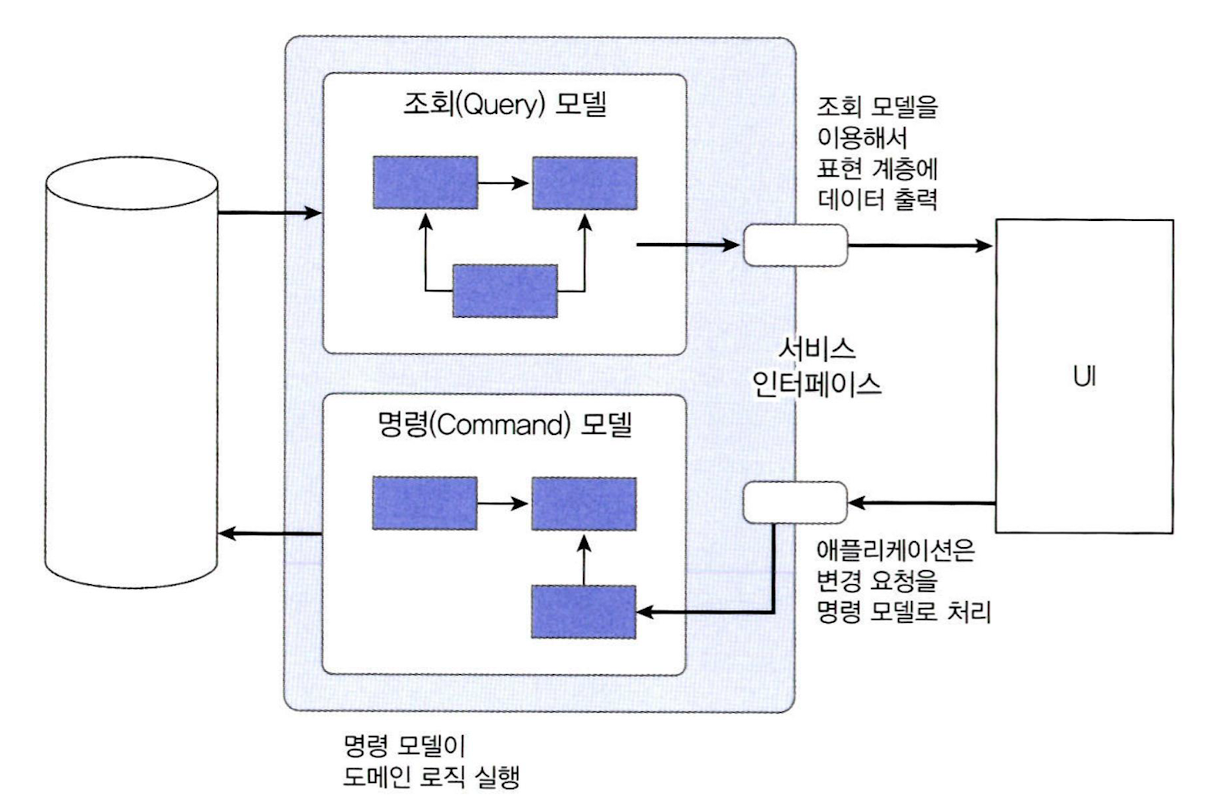
-
명령을 위한 모델과 조회를 위한 모델을 분리하는 패턴
-
명령(Command): 상태를 변경
-
주로 한 애그리거트의 상태를 변경
- e.g. 새 주문 생성, 배송지 정보 변경, 회원 암호 변경
- ORM이 적합: 객체 지향으로 도메인 모델을 구현하기가 편리
-
주로 한 애그리거트의 상태를 변경
-
조회(Query): 상태를 제공
-
2개 이상의 애그리거트가 필요할 때가 많음
- e.g. 주문 상세 내역 보기, 게시글 목록 보기, 회원 정보 보기, 판매 통계 보기
- ORM이 부적합: 애그리거트들이 분리되어 있어, 성능 고려 필요
- 응용 서비스 계층 없이 컨트롤러에서 바로 DAO 실행해도 무방
-
2개 이상의 애그리거트가 필요할 때가 많음
-
명령(Command): 상태를 변경
- 장점
- 명령 모델 구현 시 도메인 자체에 집중 가능 (조회 성능 위한 코드 분리)
- 복잡한 도메인에 적합
- 단일 모델로 처리하면, 조회 기능의 로딩 속도를 위해 도메인 모델이 매우 복잡해짐
-
조회 성능 향상에 유리 (자유롭게 성능 향상 시도 가능)
- 각 모델에 맞는 구현 기술 선택 가능
- e.g.1 명령 모델은 JPA, 조회 모델은 MyBatis…
- e.g.2 명령 모델은 트랜잭션 지원 RDBMS, 조회 모델은 조회 성능이 좋은 메모리 기반 NoSQL
-
대규모 웹 서비스는 조회 성능 개선을 위해 암묵적으로 이미 CQRS를 적용
- 웹 서비스는 상태 변경 요청보다 조회 요청이 월등히 많음
- 쿼리 최적화, 캐싱, 조회 전용 저장소 사용 등의 기법을 적용하게 됨
- 다만, 명시적으로도 CQRS 적용하는 것이 좋음
- 각 모델에 맞는 구현 기술 선택 가능
- 명령 모델 구현 시 도메인 자체에 집중 가능 (조회 성능 위한 코드 분리)
- 단점
-
구현 코드가 더 많아짐
- 도메인이 복잡하거나 대규모 트래픽이 발생하는 서비스 -> 유지보수에 유리
- 도메인이 단순하거나 트래픽이 많지 않은 서비스 -> 비용 상승, 이점이 적음
-
더 많은 구현 기술 필요
- 다른 구현 기술, 다른 저장소, 데이터 동기화를 위한 메시징 시스템 도입 등
-
구현 코드가 더 많아짐
-
중요: 명령 모델과 조회 모델 간 데이터 동기화는 이벤트를 활용해 처리하자
- 명령 모델에서 상태 변경 후 이벤트 발생 -> 조회 모델에 이벤트를 전달해 변경 내역 반영
- DB 저장소가 다른 경우, 동기화 시점에 따라 구현이 달라짐
- 실시간 동기화: 동기 이벤트 or 글로벌 트랜잭션 사용 (성능은 떨어지는 단점)
- 특정 시간 안에만 동기화: 비동기로 데이터 전송
Reference
도메인 주도 개발 시작하기
NHN FORWARD 22 - DDD 뭣이 중헌디? 🧐
Domain Driven Design – 1부 (Strategic Design)
DDD 이야기 part1