
데이터 관련 테크닉
DTO (Data Transfer Object)
- 기능은 없고 데이터를 전달만 하는 용도로 사용하는 객체
- 기능이 있어도 주 기능이 데이터 전달이면 DTO라 할 수 있음
- 네이밍 컨벤션은 자유여서 DTO를 꼭 붙이지 않아도 됨
- DTO는 최종 호출되는 곳이 소유자이므로, 소유자가 있는 패키지에 위치하는 것이 맞다!
- 보통은 리포지토리 패키지에 위치할 것이고, 만일 서비스에서 사용이 끝난다면 서비스 패키지에 둠
- 이를 지키지 않으면 순환참조가 발생할 수 있음
별칭 (as)
-
별칭을 사용하면 DB 컬럼 이름과 객체의 이름의 표기법이 불일치하거나 이름이 아얘 다른 문제 해결 가능
- 관례적으로 DB는 snake case를 쓰고 자바는 camel case를 써서 문제 발생
- BeanProperty 관련 기능을 쓸 때,
select item_name쿼리의 경우setItem_name()이라는 메서드가 없으므로 문제가 생기는데select item_name as itemName은 불일치 문제를 해결
- 보통 DB 관련 기능들은 표기법 자동 변환을 지원
-
NamedParameterJdbcTemplate의BeanPropertyRowMapper()등
-
- 컬럼 이름과 객체 이름이 완전히 다를 때만 SQL에서 별칭을 사용하면 됨
테스트 원칙과 방법
- 테스트는 다른 환경과 철저히 분리해야 함
-
메모리 모드 (=임베디드 모드)
- DB를 애플리케이션에 내장해 함께 실행 (애플리케이션 실행 시 DB를 JVM 메모리에 포함)
- 애플리케이션이 종료되면 임베디드 모드 DB도 함께 종료되고 데이터도 모두 사라짐
-
DB 초기화 SQL 스크립트 필요 (테이블 생성 etc…)
- 스프링 부트가 SQL 스크립트를 실행해 애플리케이션 로딩 시점에 DB 초기화 제공
- 위치와 파일 이름 일치 필요
src/test/resources/schema.sql
- SQL 실행 로그 확인 방법 (
application.properties)logging.level.org.springframework.jdbc=debug
- 방법
-
별 다른 DB 설정 안하기
- 스프링 부트는 별 다른 DB 설정이 없으면 메모리 DB로 접속
-
src/test/resources/application.properties의 DB 접근 정보 지우기
- 테스트 프로필로 메모리 DB 접속하는
dataSource빈 등록하기-
jdbc:h2:mem:db등의 메모리 주소로 데이터 소스 생성 및 사용
-
-
별 다른 DB 설정 안하기
- 테스트 전용 DB 사용하기
- 다른 이름의 데이터베이스를 하나 생성하고 테스트 시에는 해당 주소에 접속
-
메모리 모드 (=임베디드 모드)
- 테스트는 다른 테스트와 격리해야 하고 반복 실행할 수 있어야 함
-
트랜잭션 & 롤백 전략
- 각각의 테스트를 시작할 때 트랜잭션을 열고 끝날 때 해당 트랜잭션을 롤백
- 방법
-
@Transactional- 기본은 로직이 성공적으로 수행되면 커밋
-
테스트에서 사용하면, 테스트를 각각 트랜잭션 안에서 실행하고 끝나면 자동 롤백
- 트랜잭션 전파로 서비스, 리포지토리도 테스트에서 시작한 같은 트랜잭션에 참여
- 클래스, 메서드 단위 적용 가능
- 간혹 테스트에서 실제 저장을 하고 싶을 때는
@Commit을 테스트에 함께 붙이면 됨
-
@BeforeEach,@AfterEach에서 트랜잭션 열고 롤백transactionManager.getTransaction(...);transactionManager.rollback();
-
-
트랜잭션 & 롤백 전략
테스트 유의점
- 테스트시
application.properties는src/test/resources에 있는 것이 우선순위 실행 -
@SpringBootTest:@SpringBootApplication을 찾아 설정으로 사용
SQL Mapper 종류
선택기준
- ORM 기술 스택을 사용하면, 네이티브 SQL을 사용할 때 JdbcTemplate 수준에서 거의 해결될 것
- 따라서, 단순한 쿼리가 많다면 JdbcTemplate 사용
- 반면에, 프로젝트에 복잡한 쿼리가 많다면 MyBatis 사용
- 둘 다 사용해도 되지만, MyBatis를 선택했다면 그것으로 충분할 것
JdbcTemplate
- 장점
-
설정의 편리함
-
spring-jdbc라이브러리에 포함되어 있어 간단하게 바로 사용 가능 -
spring-jdbc는 스프링으로 JDBC 사용할 때 기본으로 사용되는 라이브러리
-
-
반복 문제 해결
- 템플릿 콜백 패턴으로 JDBC를 직접 사용할 때 발생하는 반복 작업을 대신 처리
-
설정의 편리함
- 단점
- 동적 SQL 해결이 어려움
- SQL을 자바 코드로 작성하기 때문에, SQL 라인이 넘어갈 때 마다 문자 더하기를 해주어야 함
- 패키지 설정
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
- 추가 설정(
application.properties)- SQL 로그:
logging.level.org.springframework.jdbc=debug - main, test 모두 추가
- SQL 로그:
- 주요 기능
-
JdbcTemplate- 순서 기반 파라미터 바인딩 지원
- 객체 생성
private final JdbcTemplate templatetemplate = new JdbcTemplate(dataSource);
- 단건 조회
template.queryForObject(sql, memberRowMapper(), memberId);- 결과 로우가 하나일 때 사용
- 결과가 없으면
EmpytyResultDataAccessException발생 - 결과가 둘 이상이면
IncorrectResultSizeDataAccessException발생
- 리스트 조회
template.query(sql, memberRowMapper(), param.toArray());- 결과가 하나 이상일 때 사용
- 결과 없으면 빈 컬렉션을 반환
- 갱신
template.update(sql, money, memberId);-
KeyHolder- DB가 Identity (auto increment) 전략을 사용할 때, Insert 완료 후 PK 값을 채움
- 임의의 SQL (DDL 등)
jdbcTemplate.execute("create table mytable (id integer, name varchar(100))");
- 응답 결과 매핑
RowMapper- 데이터베이스의 반환 결과인
ResultSet을 객체로 변환private RowMapper<Member> memberRowMapper() { return (rs, rowNum) -> { Member member = new Member(); member.setMemberId(rs.getString("member_id")); member.setMoney(rs.getInt("money")); return member; }; }
-
NamedParameterJdbcTemplate(권장)- 이름 기반 파라미터 바인딩 지원
- 객체 생성
private final NamedParameterJdbcTemplate template;template = new NamedParameterJdbcTemplate(dataSource);
- 자주 사용하는 파라미터 종류
-
MapMap<String, Object> param = Map.of("id", id);Item item = template.queryForObject(sql, param, itemRowMapper());
-
MapSqlParameterSourceSqlParameterSource param = new MapSqlParameterSource() .addValue("itemName", updateParam.getItemName()) .addValue("price", updateParam.getPrice()) .addValue("quantity", updateParam.getQuantity()) .addValue("id", itemId); template.update(sql, param); -
BeanPropertySqlParameterSource- 자바빈 프로퍼티 규약을 통해 자동으로 파라미터 객체 생성
- 전달하는 객체에
getXxx메소드가 있어야 함SqlParameterSource param = new BeanPropertySqlParameterSource(item); KeyHolder keyHolder = new GeneratedKeyHolder(); template.update(sql, param, keyHolder);
-
- 응답 결과 매핑
BeanPropertyRowMapper-
ResultSet의 결과를 받아서 자바빈 규약에 맞추어 데이터를 변환private RowMapper<Item> itemRowMapper() { return BeanPropertyRowMapper.newInstance(Item.class); //camel 변환 지원 }
-
SimpleJdbcInsert- INSERT SQL을 직접 작성하지 않아도 되도록 지원
- 생성 시점에 DB 테이블 메타 데이터 조회, 어떤 칼럼이 있는지 확인 (
usingColumns생략 가능) - 객체 생성
private final SimpleJdbcInsert jdbcInsert;jdbcInsert = new SimpleJdbcInsert(dataSource)- ` .withTableName(“item”)`
- ` .usingGeneratedKeyColumns(“id”);`
- ` // .usingColumns(“item_name”, “price”, “quantity”); //생략 가능`
- 삽입
SqlParameterSource param = new BeanPropertySqlParameterSource(item); Number key = jdbcInsert.executeAndReturnKey(param); //생성된 키 자동 조회
-
SimpleJdbcCall- 스토어드 프로시저를 편리하게 호출 가능
-
MyBatis
-
JdbcTemplate의 대부분의 기능 및 추가 기능 제공 - 장점
- SQL을 XML에 편리하게 작성 가능 (문자 더하기 불편 X)
- 동적 쿼리를 편리하게 작성 가능
- 단점
- 약간의 설정이 필요
- 패키지 설정
-
implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.0- 스프링 부트가 관리해주는 공식 라이브러리가 아니므로 뒤에 버전 정보를 붙여야 함
- 스프링 부트 3.0 이상 ->
mybatis-spring-boot-starter3.0.3 사용
-
- 추가 설정 (
application.properties)mybatis.type-aliases-package=hello.itemservice.domain //패키지 이름 mybatis.configuration.map-underscore-to-camel-case=true logging.level.hello.itemservice.repository.mybatis=trace-
mybatis.type-aliases-package- 마이바티스에서 타입 정보 사용할 때 패키지 이름을 적어야 하는데, 여기 명시 시 생략 가능
- 지정 패키지 및 하위 패키지까지 자동 인식
- 여러 위치 지정 시
,,;로 구분
-
mybatis.configuration.map-underscore-to-camel-case- 언더바 -> 카멜 케이스 자동 변경 기능 활성화
- DB 컬럼 이름과 자바 객체 이름 사이의 불일치 해결
-
logging.level.hello.itemservice.repository.mybatis=trace- 쿼리 로그 확인
- main, test 모두 추가
-
- 주요 기능
-
매퍼 인터페이스
-
@Mapper- 마이바티스 매핑 XML을 호출해주는 매퍼 인터페이스에
@Mapper애노테이션을 적용 - 매퍼 인터페이스의 메서드를 호출하면 연결된 XML의 SQL을 실행하고 결과를 반환
- 마이바티스 매핑 XML을 호출해주는 매퍼 인터페이스에
- 원리
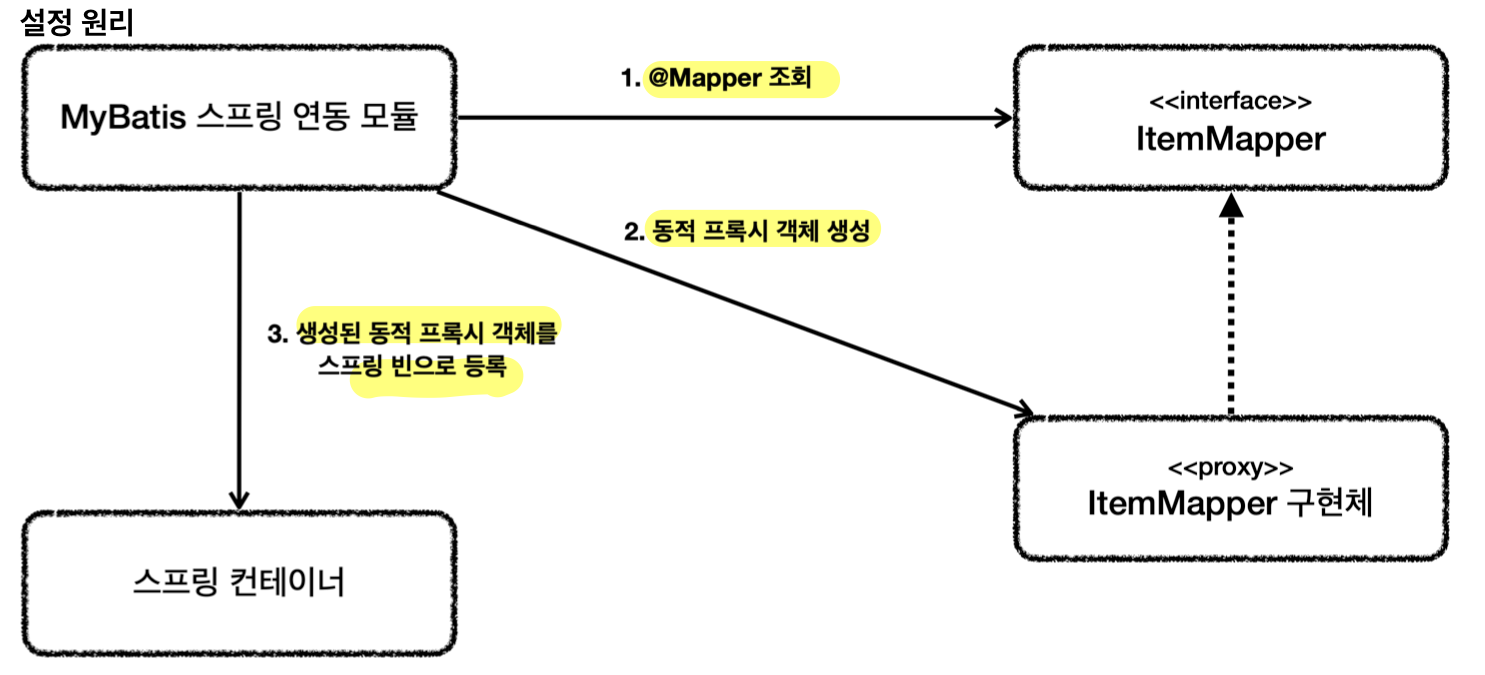
- 애플리케이션 로딩 시점에 MyBatis 스프링 연동 모듈이
@Mapper인터페이스 조회 - 동적 프록시 기술을 사용해 조회된 해당 인터페이스들의 구현체를 생성
- 생성한 구현체를 스프링 빈으로 등록
- 애플리케이션 로딩 시점에 MyBatis 스프링 연동 모듈이
- 매퍼 구현체
- MyBatis 스프링 연동 모듈이 생성한 구현체 덕에 인터페이스만으로 깔끔하게 사용 가능
- MyBatis 예외를 스프링 예외 추상화인
DataAccessException에 맞게 변환해 반환
-
-
XML 매핑 파일
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="hello.item.repository.mybatis.ItemMapper"> <insert id="save" useGeneratedKeys="true" keyProperty="id"> insert into item (item_name, price, quantity) values (#{itemName}, #{price}, #{quantity}) </insert> <update id="update"> update item set item_name=#{updateParam.itemName}, price=#{updateParam.price}, quantity=#{updateParam.quantity} where id = #{id} </update> <select id="findById" resultType="Item"> select id, item_name, price, quantity from item where id = #{id} </select> <select id="findAll" resultType="Item"> select id, item_name, price, quantity from item <where> <if test="itemName != null and itemName != ''"> and item_name like concat('%',#{itemName},'%') </if> <if test="maxPrice != null"> and price <= #{maxPrice} </if> </where> </select> </mapper>-
src/main/resources하위에 매핑 인터페이스와 패키지 위치를 똑같이 맞추어 생성src/main/resources/hello/item/repository/mybatis/ItemMapper.xml
-
namespace- 매퍼 인터페이스를 지정
- XML 파일 경로 수정 (`application.properties)
mybatis.mapper-locations=classpath:mapper/**/*.xml-
resources/mapper를 포함한 하위 폴더의 XML을 매핑 파일로 인식 - main, test 모두 적용
-
- 기본 쿼리
-
<insert><insert id="save" useGeneratedKeys="true" keyProperty="id"> insert into item (item_name, price, quantity) values (#{itemName}, #{price}, #{quantity}) </insert>-
id: 매퍼 인터페이스에 설정한 메서드 이름 지정 -
#{}: 파라미터 바인딩 -
useGeneratedKeys: IDENTITY 전략일 때 사용 -
keyProperty: 생성되는 키 이름 지정 -
<update>import org.apache.ibatis.annotations.Param; void update(@Param("id") Long id, @Param("updateParam") ItemUpdateDto updateParam);<update id="update"> update item set item_name=#{updateParam.itemName}, price=#{updateParam.price}, quantity=#{updateParam.quantity} where id = #{id} </update>-
@Param: 파라미터가 2개 이상이면 애노테이션으로 이름을 지정해 구분해야 함
-
-
-
<select><select id="findById" resultType="Item"> select id, item_name, price, quantity from item where id = #{id} </select>-
resultType: 반환 타입 명시 - SQL 결과를 편리하게 객체로 변환
-
<select>동적 쿼리<select id="findAll" resultType="Item"> select id, item_name, price, quantity from item <where> <if test="itemName != null and itemName != ''"> and item_name like concat('%',#{itemName},'%') </if> <if test="maxPrice != null"> and price <= #{maxPrice} </if> </where> </select>-
<if>: 모두 실패해면where를 만들지 않고, 하나라도 성공하면where,and자동 지원 - XML 특수문자
- XML은 태그 사용으로 인해 특수문자 사용이 제한 되어 다음과 같은 연산 키워드 지원
-
<(<),>(>),&(&)
- CDATA
- CDATA 구문 내에서는 특수문자 사용 가능
<![CDATA[ and price <= #{maxPrice} ]]>
- 다른 동적 쿼리 형태
-
<choose>,<when>,<otherwise>: switch 구문과 유사 -
<foreach>: 컬렉션 반복 처리 시 사용
-
-
-
-
- 애노테이션 SQL 작성
- 인터페이스 메서드에 적용
-
@Select,@Insert,@Update,@Delete@Select("select id, item_name, price from item where id=#{id}")
- MyBatis의 장점은 XML에 있으므로 가끔 간단한 쿼리 정도에만 사용하고 거의 사용 X
- 동적 SQL도 어려움
-
<sql>-
SQL 코드를 재사용 가능
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
-
<include>로 sql 조각을 찾아 사용<include refid="userColumns"><property name="alias" value="t1"/></include>
-
SQL 코드를 재사용 가능
-
<resultMap>- DB 컬럼 이름과 객체 이름 불일치 문제를 별칭 사용 대신 사용자 지정 매핑으로 해결
-
매퍼 인터페이스
스프링 트랜잭션 AOP와 예외 정책
- 스프링 트랜잭션 예외 발생 기본 정책
-
언체크 예외(
RuntimeException,Error)는 롤백- 애플리케이션에서 복구 불가능한 예외로 가정
-
체크 예외(
Exception)는 커밋-
비즈니스적으로 의미가 있을 때 사용할 것으로 가정
-
시스템은 정상 동작했지만 비즈니스 상황에서 문제 존재
- 즉, 예외를 발생시켜 알림
- 예외를 마치 리턴 값처럼 사용하는 상황
- 비즈니스 예외는 매우 중요하고 반드시 처리해야 하는 경우가 많음
-
시스템은 정상 동작했지만 비즈니스 상황에서 문제 존재
- e.g. 결제 잔고 부족 시
- 필요한 후속작업
- 주문 데이터를 저장하고, 결제 상태를 대기로 처리
- 고객에게 잔고 부족을 알리고 별도의 계좌로 입금하도록 안내
-
NotEnoughMoneyException커스텀 체크 예외 발생시킴 (비즈니스 예외)
- 필요한 후속작업
-
비즈니스적으로 의미가 있을 때 사용할 것으로 가정
-
언체크 예외(
- 예외 전략
- 비즈니스 상황에서 체크 예외 던지기 전략 (권장 - 스프링 기본 정책)
-
비즈니스 상황에 따라 체크 예외도 롤백하고 싶은 경우
rollbackFor옵션으로 롤백 가능
-
비즈니스 상황에 따라 체크 예외도 롤백하고 싶은 경우
- 비즈니스 상황에서 리턴 값 사용하기 전략
- 비즈니스 상황은 체크 예외 던지지 않기 (시스템 예외만 예외로 가정)
- 일관성 있는 리턴 값을 통해 다음 프로세스를 태움 (ENUM…)
- 비즈니스 상황에서 체크 예외 던지기 전략 (권장 - 스프링 기본 정책)
@Transactional 옵션
-
value,transactionManager- 스프링 빈에 등록된 트랜잭션 매니저 중 어떤 것을 사용할지 지정
- 값 생략 시 기본 등록 트랜잭션 매니저 사용
- 스프링 부트가 라이브러리 보고 판단해 등록한 트랜잭션 매니저
- 보통 생략해서 사용
-
사용하는 트랜잭션 매니저가 둘 이상이라면, 이 값을 지정해 구분
- 애노테이션 속성이 하나인 경우
value생략하고 바로 값 넣기 가능public class TxService { @Transactional("memberTxManager") public void member() {...} @Transactional("orderTxManager") public void order() {...} }
- 애노테이션 속성이 하나인 경우
-
rollbackFor- 스프링 트랜잭션 예외 발생 기본 정책에 추가로 롤백할 예외 지정
@Transactional(rollbackFor = Exception.class)- 이 경우, 체크 예외인
Exception이 발생해도 롤백
- 스프링 트랜잭션 예외 발생 기본 정책에 추가로 롤백할 예외 지정
-
noRollbackFor- 스프링 트랜잭션 예외 발생 기본 정책에 추가로 롤백을 하지 않을 예외 지정
-
propagation- 트랜잭션 전파 옵션
-
isolation- 트랜잭션 격리 수준 지정
- 보통 DB 기본값을 따르고 애플리케이션 개발자가 직접 지정하는 경우는 적음
-
DEFAULT: DB 설정 격리 수준 따름 -
READ_UNCOMMITTED,READ_COMMITED,REPEATABLE_READ,SERIALIZABLE
-
timeout- 트랜잭션 수행 시간 타임아웃 지정 (초 단위)
- 운영 환경에 따라 동작하지 않을 수도 있기 때문에 동작 확인 필요
-
label- @Transactional에 어떠한 태깅을 붙여 직접 읽고 싶을 때 사용
- 예를 들어, A라 적히면 A DB에서 B라 적히면 B DB 에서 조회
- 일반적으로 잘 사용하지 않음
-
readOnly-
읽기 전용 트랜잭션 생성
- 읽기 전용 트랜잭션은 등록, 수정, 삭제가 안되고 읽기만 동작 (환경에 따라 비정상 동작 가능)
-
기본값:
false-
@Transactional == @Transactional(readOnly=false)-
readOnly는 보통 생략
-
- 일반적으로 트랜잭션은 읽기 쓰기가 모두 가능한 형태로 생성됨
-
-
읽기에 대한다양한 성능 최적화 진행
- 프레임워크
- JdbcTemplate은 읽기 전용 트랜잭션 안에서 변경을 실행하면 예외를 던짐
- JPA는 읽기 전용 트랜잭션의 경우 커밋 시점에 플러시를 호출하지 않음
변경 감지를 위한 스냅샷 객체도 생성하지 않고 메모리를 절약
- JDBC 드라이버
- 읽기 전용 트랜잭션 안에서 변경 쿼리가 발생하면 예외 던짐
- 읽기, 쓰기 (마스터, 슬레이브) DB를 구분해서 요청 (리플리케이션)
- 데이터베이스
- 읽기 트랜잭션은 읽기만 하면 되므로, 내부 성능 최적화 발생
- 프레임워크
-
읽기 트랜잭션이라면 일반적으로 true를 주는 것이 좋음
- 보통 JPA를 사용할 경우 성능 최적화가 더 큼
- Jdbc에 대해서는 크게 일어나지 않거나 오히려 성능이 저하되는 경우도 있긴 함
-
읽기 전용 트랜잭션 생성
스프링 트랜잭션 전파 (Propagation)
-
트랜잭션 전파
- 트랜잭션이 이미 진행 중인데 추가로 트랜잭션 수행 시 어떻게 동작할 지 결정하는 것 (스프링)
- 여러 클라이언트가 서비스 혹은 레포지토리를 호출하는 상황에서 다양한 트랜잭션 요구사항 해결
- 용어
- 외부 트랜잭션
- 상대적으로 바깥에 있는 트랜잭션 (처음 시작된 트랜잭션)
- 내부 트랜잭션
- 마치 내부에 있는 것처럼 보이는 트랜잭션 (외부 트랜잭션 수행 도중 호출된 트랜잭션)
- 물리 트랜잭션
- 실제 DB 트랜잭션을 의미
- 논리 트랜잭션
- 트랜잭션 매니저를 통해 트랜잭션을 사용하는 단위
-
REQUIRED옵션 사용하고 추가 내부 트랜잭션이 있을 때만 적용하는 개념
- 외부 트랜잭션
- 옵션 사용 전략
- 대부분
REQUIRED옵션 사용 - 아주 가끔
REQUIRES_NEW옵션 사용 - 나머지는 거의 사용 X
- 대부분
-
REQUIRED(기본 설정)
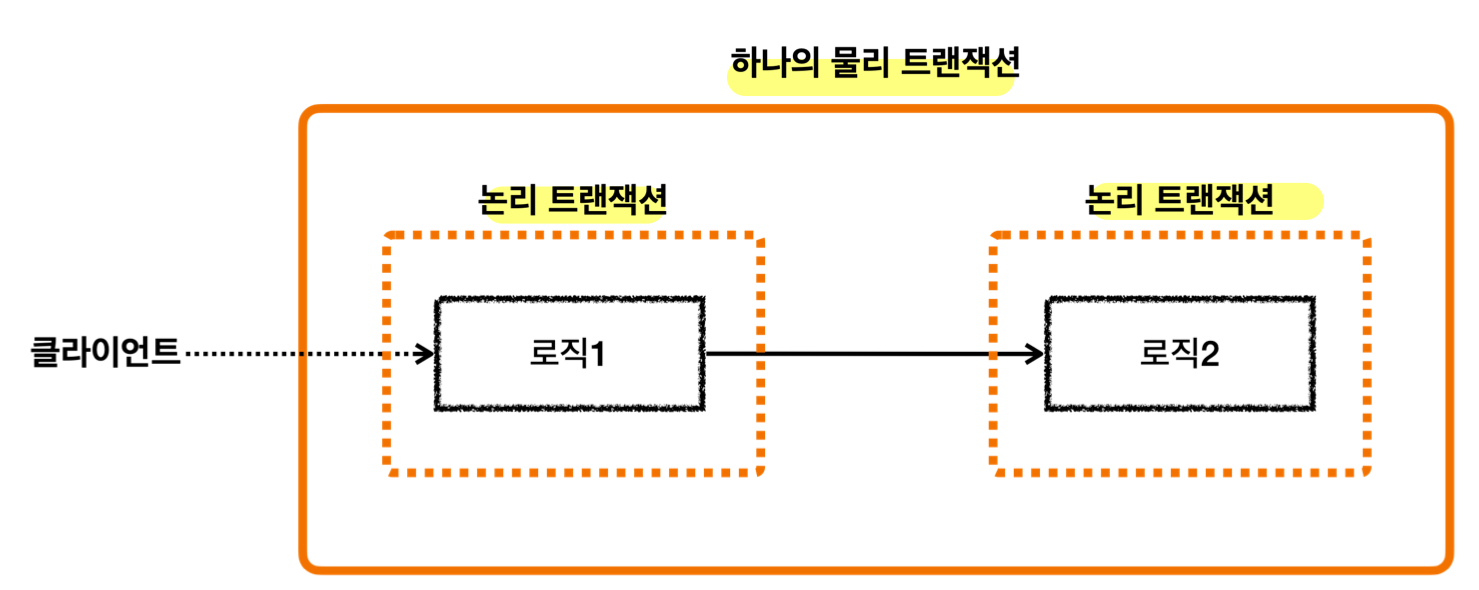
- 기존 트랜잭션이 없으면 생성하고 있으면 참여
- e.g. 회원 등록 시 로그도 무조건 함께 남김
- 한 물리 트랜잭션으로 묶는 것은 데이터 정합성 문제 예방 효과 있음
- 특징
-
여러 개의 논리 트랜잭션을 하나의 물리 트랜잭션으로 묶음
- = 외부 트랜잭션과 내부 트랜잭션을 묶어서 하나의 물리 트랜잭션으로 만들어 줌
- = 내부 트랜잭션이 외부 트랜잭션에 참여한다고도 표현
- = 외부 트랜잭션의 범위가 내부 트랜잭션까지 넓어진다고도 표현
-
외부 트랜잭션이 실제 물리 트랜잭션을 관리
- 물리 트랜잭션의 시작과 실제 커밋 및 롤백을 담당
- 코드 상 논리 트랜잭션마다 커밋 호출이 중복되는데,
실제 커밋은 외부 트랜잭션 커밋 시 발생
-
여러 개의 논리 트랜잭션을 하나의 물리 트랜잭션으로 묶음
- 원칙
- 모든 논리 트랜잭션(=트랜잭션 매니저)이 커밋되어야 물리 트랜잭션이 커밋
- 하나의 논리 트랜잭션(=트랜잭션 매니저)이라도 롤백되면 물리 트랜잭션은 롤백
- 시나리오 별 동작
- 트랜잭션 매니저 커밋 / 롤백 기본 로직
-
신규 트랜잭션(=외부 트랜잭션)인지 확인 (
isNewTransaction)- 신규 트랜잭션인 경우
- 물리 커밋 / 롤백 호출
- 신규 트랜잭션이 아닌 경우
- 커밋인 경우 아무 것도 안함
- 롤백인 경우 트랜잭션 동기화 매니저에
rollbackOnly=true만 설정
- 신규 트랜잭션인 경우
-
물리 커밋 호출 시에는
rollbackOnly설정 확인-
false인 경우 그대로 커밋 -
true인 경우 물리 롤백 진행 및 예외 던짐-
UnexpectedRollbackException.class예외 발생 - e.g. 내부 트랜잭션 롤백 호출
- e.g. 레포지토리에서 런타임 예외 발생했는데, 서비스에서 예외 처리한 경우
- 등록 로그 저장 실패해도 회원 등록은 문제 없게 하려는 상황
- AOP에서 물리 커밋 호출하다가
rollbackOnly=true확인하여 발생 - 개발자는 정상 흐름으로 복구해 커밋을 의도했지만, 결과는 모두 롤백
- 이럴 땐
REQUIRES_NEW도 함께 사용해야 함 (실무에서 많이 하는 실수)
-
-
-
내부 트랜잭션 로직에서 런타임 예외가 발생하는 경우 물리 롤백 호출
- AOP 역시 발생한 예외를 그대로 밖으로 던짐
-
신규 트랜잭션(=외부 트랜잭션)인지 확인 (
- 상황 1: 모든 논리 트랜잭션 정상 커밋
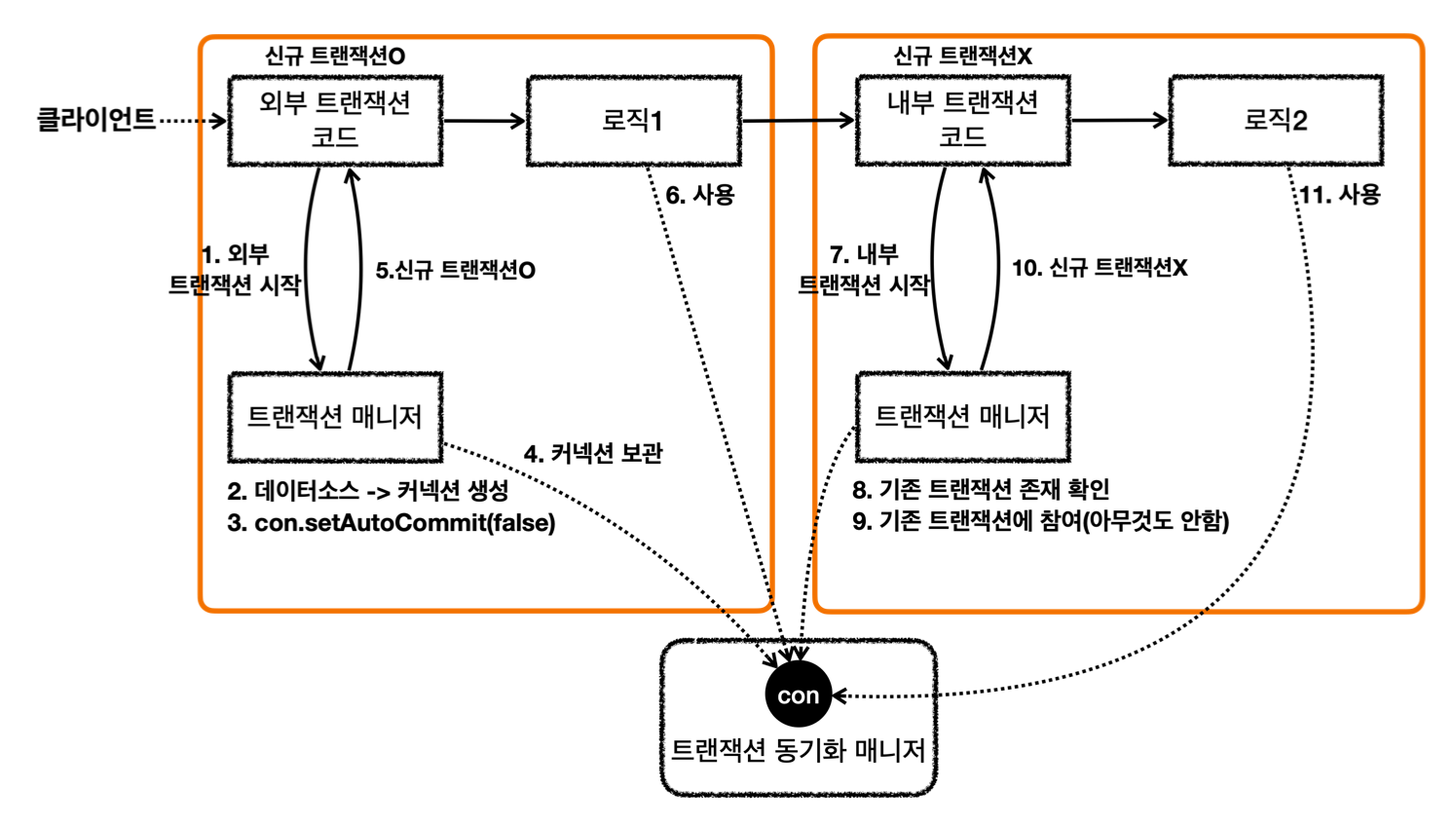
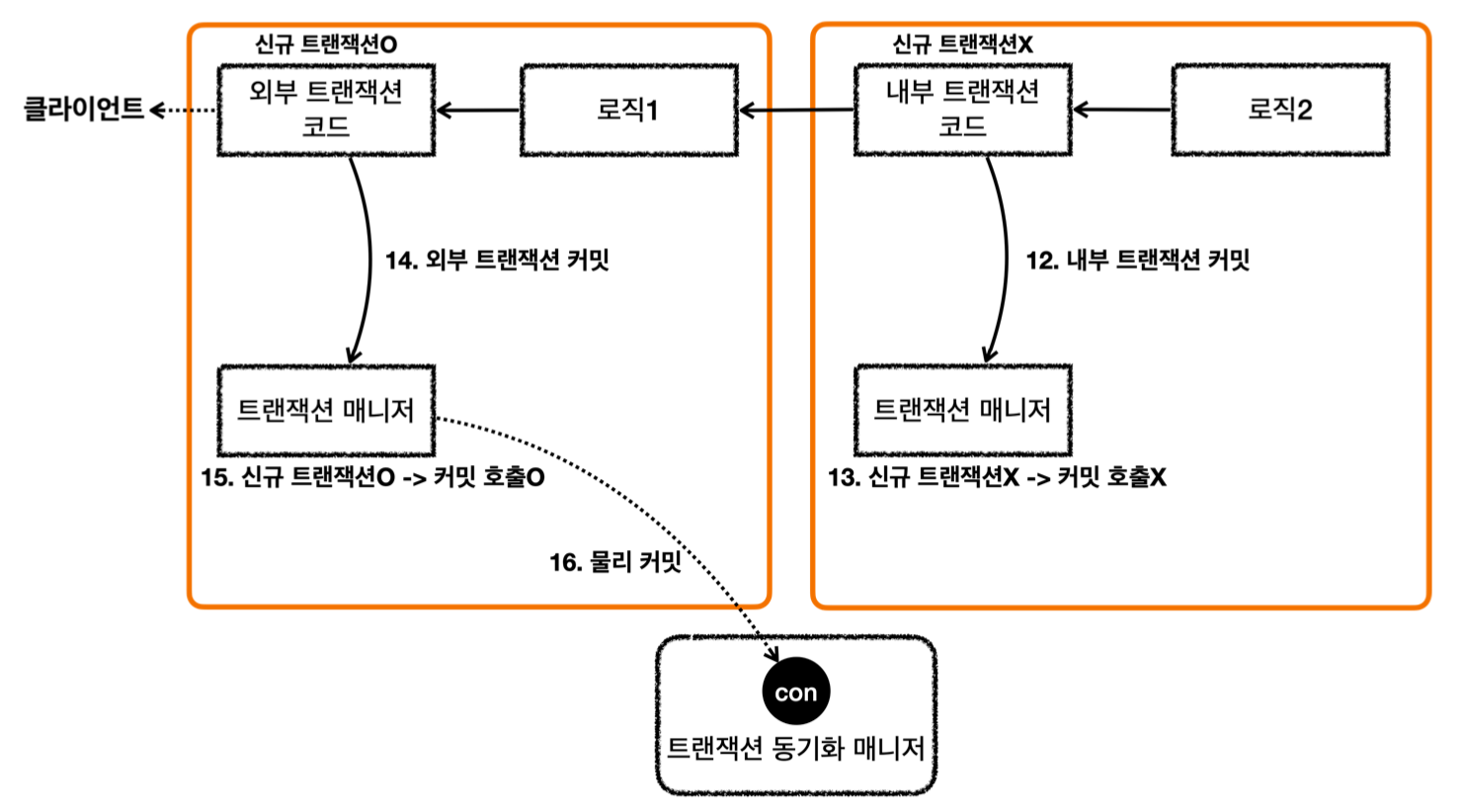
- 신규 트랜잭션(=외부 트랜잭션)인 경우만 실제 물리 커밋 및 롤백 관리
(isNewTransaction) - 결과: 물리 트랜잭션 커밋
- 신규 트랜잭션(=외부 트랜잭션)인 경우만 실제 물리 커밋 및 롤백 관리
- 상황 2: 외부 트랜잭션 롤백, 내부 트랜잭션 커밋
- 외부 트랜잭션이 실제 롤백 실행
- 결과: 물리 트랜잭션 롤백
- 상황 3: 외부 트랜잭션 커밋, 내부 트랜잭션 롤백
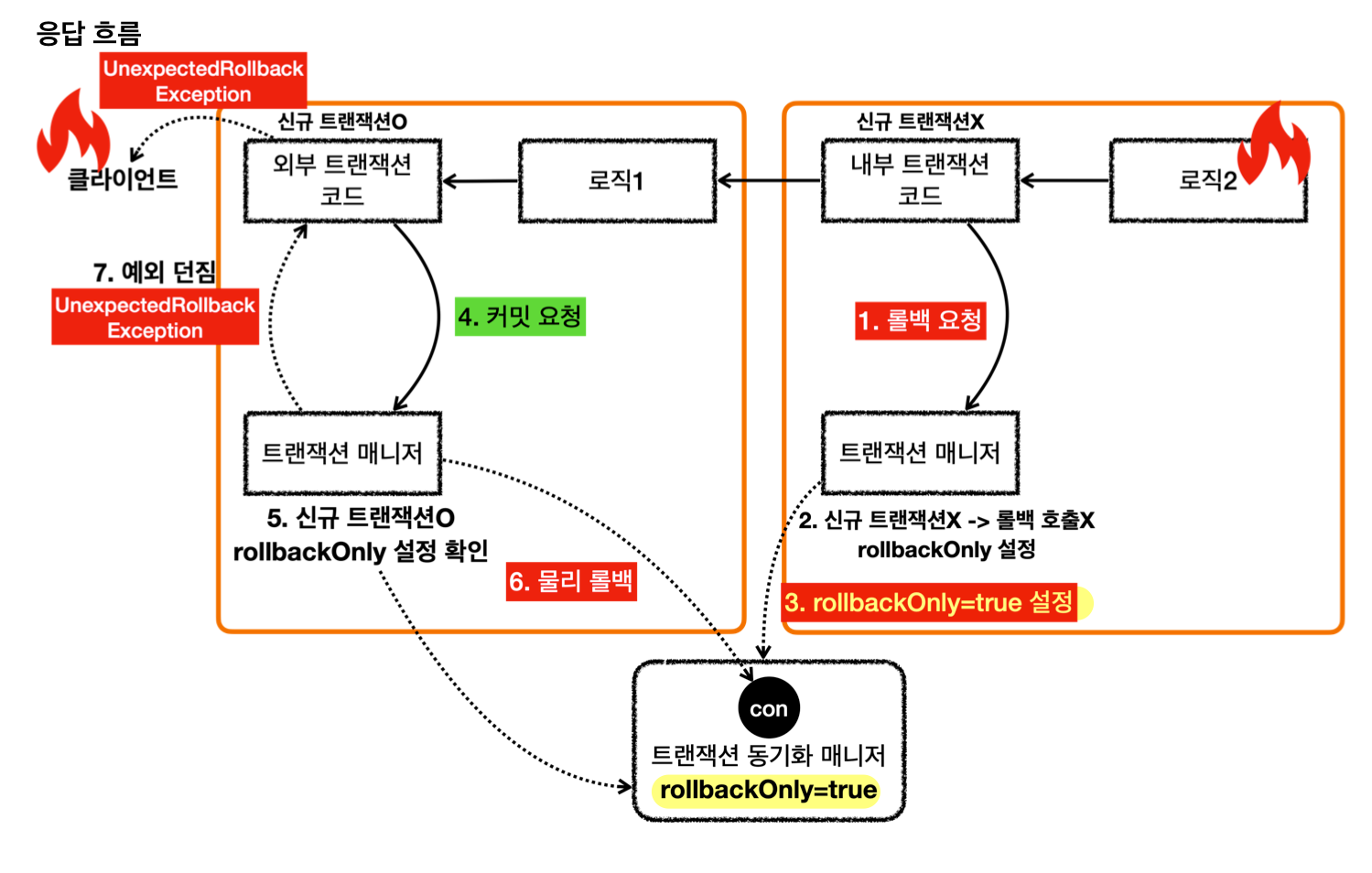
- 내부 트랜잭션 롤백 때, 기존 트랜잭션을 롤백 전용(
rollback-only)으로 표시-
트랜잭션 동기화 매니저에
rollbackOnly=true표시 Participating transaction failed - marking existing transaction as rollback-only
-
트랜잭션 동기화 매니저에
- 외부 트랜잭션 커밋 때,
UnexpectedRollbackException.class예외 발생- 커밋 호출 시 트랜잭션 동기화 매니저에
rollbackOnly=true확인 후 동작 Global transaction is marked as rollback-only
- 커밋 호출 시 트랜잭션 동기화 매니저에
- 결과: 물리 트랜잭션 롤백 + 예외 발생
- 내부 트랜잭션 롤백 때, 기존 트랜잭션을 롤백 전용(
- 트랜잭션 매니저 커밋 / 롤백 기본 로직
-
REQUIRES_NEW- 항상 새로운 트랜잭션을 생성
- e.g. 회원 등록 로그를 남기되, 로그 저장 실패해도 회원 등록은 문제 없게 할 때 유용
- 로그는 콘솔에 로그로 남겨두고 나중에 복구해도 큰 문제 없음
- LogRepository -
save()@Transactional(propagation = Propagation.REQUIRES_NEW) public void save(Log logMessage) - 커넥션이 2개 물리므로 성능이 중요한 곳에서는 주의해서 사용해야 함
-
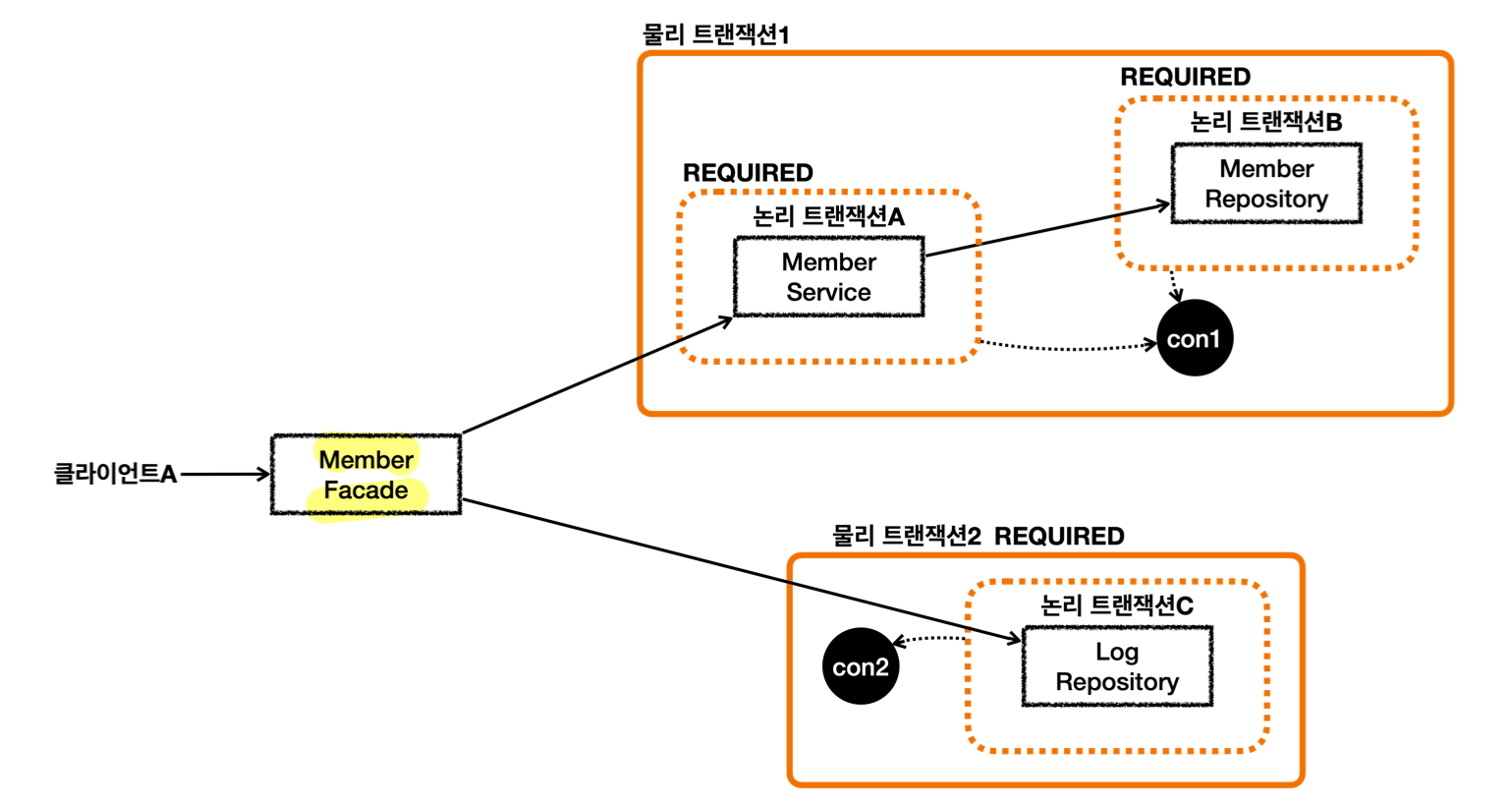
REQUIRES_NEW를 안쓰고 단순한 해결 방법이 있다면 더 좋다!- e.g. 구조 변경으로 해결
-
MemberFacade라는 계층을 하나 더 두고MemberService와LogRepository호출
-
- e.g. 구조 변경으로 해결
- 특징
- 외부 트랜잭션과 내부 트랜잭션을 완전히 분리해 각각 별도의 물리 트랜잭션으로 사용
- 별도의 물리 트랜잭션을 가진다는 뜻은 DB 커넥션을 따로 사용한다는 뜻
- 따라서, 내부 트랜잭션의 커밋 / 롤백이 외부 트랜잭션의 커밋 / 롤백에 영향을 미치지 않음
-
데이터베이스 커넥션을 동시에 2개 사용하므로 성능이 중요한 곳에서는 주의해서 사용
- 1번의 HTTP 요청을 담당한 쓰레드가 두 개의 커넥션을 동시에 물고 있으면 커넥션 풀의 커넥션이 쉽게 고갈될 수 있음
- 빠르게 처리되면 괜찮지만, 하필 해당 로직이 느리다면 커넥션 2개가 말려들어가 위험
-
내부 트랜잭션 시작 시
REQUIRES_NEW옵션 적용- 내부 트랜잭션(
con2)이 완료될 때까지 기존 트랜잭션의 커넥션(con1)은 잠시 보류됨
- 내부 트랜잭션(
- 트랜잭션 매니저 커밋 / 롤백 기본 로직은 똑같이 적용됨
- 외부 트랜잭션과 내부 트랜잭션을 완전히 분리해 각각 별도의 물리 트랜잭션으로 사용
-
SUPPORT- 기존 트랜잭션이 없으면, 트랜잭션 없이 진행
- 기존 트랜잭션이 있으면, 기존 트랜잭션에 참여
-
NOT_SUPPORT- 기존 트랜잭션이 없으면, 트랜잭션 없이 진행
- 기존 트랜잭션이 있다면, 보류하고 트랜잭션 없이 진행
-
MANDATORY- 기존 트랜잭션이 없으면,
IllegalTransactionStateException예외 발생 - 기존 트랜잭션이 있으면, 기존 트랜잭션에 참여
- 기존 트랜잭션이 없으면,
-
NEVER- 기존 트랜잭션이 없으면, 트랜잭션 없이 진행
- 기존 트랜잭션이 있으면,
IllegalTransactionStateException예외 발생
-
NESTED- 기존 트랜잭션이 없으면, 새로운 트랜잭션 생성
- 기존 트랜잭션이 있으면, 중첩 트랜잭션을 만듦
- 중첩 트랜잭션은 외부 트랜잭션에 영향을 받기만 하고 영향을 주지는 않음
- 중첩 트랜잭션이 롤백되어도 외부 트랜잭션은 커밋 가능
- 외부 트랜잭션이 롤백 되면 중첩 트랜잭션도 함께 롤백됨
- JDBC savepoint 기능 사용 (DB 드라이버 기능 지원 확인 필수)
- JPA에서는 사용 불가능
REQUIRES_NEW옵션에서 외부 트랜잭션과 내부 트랜잭션외부 트랜잭션과 내부 트랜잭션이 별개의 물리 트랜잭션을 사용한다. 하지만, 애플리케이션 로직에서 외부 트랜잭션이 닫히면 내부 트랜잭션에 접근할 수 없다.
내부 트랜잭션의 커밋 / 롤백 후 외부 트랜잭션의 커밋 / 롤백은 가능한 반면, 외부 트랜잭션의 커밋 / 롤백 후 내부 트랜잭션의 커밋 / 롤백은 불가능하다.
트랜잭션 전파와 옵션
isolation,timeout,readOnly옵션은 트랜잭션이 처음 시작될 때만 적용되고 참여할 때는 적용되지 않는다.
즉,REQUIRED를 통한 트랜잭션 시작,REQUIRES_NEW를 통한 트랜잭션 시작 시점에만 적용된다.