
멀티태스킹 & 멀티프로세싱
- 프로그램 실행
- 프로그램을 구성하는 코드를 순서대로 CPU(=프로세서)에서 연산하는 일
- 초창기 컴퓨터
- 하나의 CPU 코어에서 한 프로그램 코드를 모두 수행 후 다른 프로그램 코드 실행
- e.g. 사용자는 음악 프로그램 끝난 후에야 워드 프로그램 실행 가능해 불편
- 멀티태스킹 (소프트웨어 관점 - 운영체제)
-
단일 CPU(단일 CPU 코어)가 여러 작업을 동시에 수행하는 것처럼 보이게 하는 것
- e.g. 현대 운영체제에서 여러 애플리케이션이 동시에 실행되는 환경
-
CPU가 매우 빠르게 두 프로그램의 코드를 번갈아 수행한다면, 사람은 동시에 실행되는 것처럼 느낄 것
- 현대 CPU는 초당 수십억 번 이상의 연산 수행
- 대략 0.01초(10ms) 동안 한 프로그램을 수십만 번 연산
- 하나의 CPU 코어 -> 프로그램 A 코드 수행 (약 10ms) -> 프로그램 B 코드 수행 (약 10ms) -> 프로그램 A의 이전 실행 중인 코드부터 다시 수행 (약 10ms) -> …
-
단일 CPU(단일 CPU 코어)가 여러 작업을 동시에 수행하는 것처럼 보이게 하는 것
- 멀티프로세싱 (하드웨어 관점)
-
여러 CPU(여러 CPU 코어)를 사용하여 여러 작업을 동시에 수행하는 것
- e.g. 멀티코어 프로세서를 사용하는 현대 컴퓨터 시스템
-
여러 개의 CPU 코어에서 여러 프로그램이 물리적으로 동시에 실행
- 코어가 2개여도 2개보다 많은 프로그램 실행 가능
- 하나의 CPU 코어만 사용하는 시스템보다 동시에 더 많은 작업을 처리
- e.g. CPU 코어 2개에서 프로그램 A, B, C 처리
- CPU 코어 2개에서 물리적으로 동시에 2개의 프로그램 처리
- A, B 실행 (약 10ms)
- B, C 실행 (약 10ms)
- …
- CPU 코어 2개에서 물리적으로 동시에 2개의 프로그램 처리
-
여러 CPU(여러 CPU 코어)를 사용하여 여러 작업을 동시에 수행하는 것
- 멀티 태스킹과 멀티프로세싱은 함께 일어날 수 있는 개념
CPU 코어
최근의 일반적인 컴퓨터는 하나의 CPU 안에 여러 개의 코어를 가지는 멀티코어 프로세서를 가진다.
코어는 CPU 안의 실제 연산을 처리하는 장치를 말한다.
과거에는 하나의 CPU 안에 하나의 코어만 들어있었다.
프로세스와 스레드
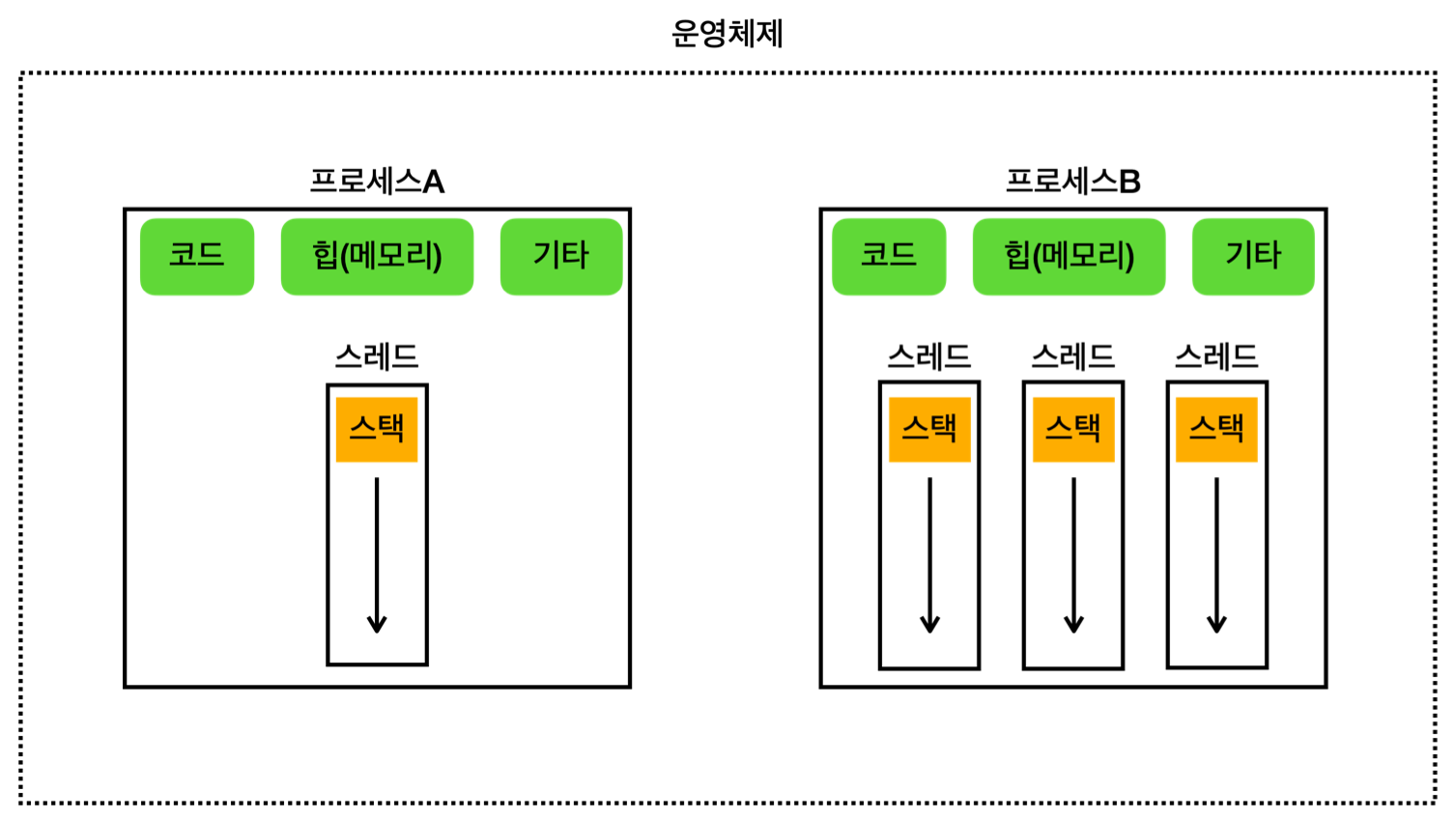
- 프로세스
-
운영체제 안에서 실행 중인 프로그램
- 실행 환경과 자원을 제공하는 컨테이너 역할
- 자바 언어와 비유하면 클래스는 프로그램(=코드뭉치, 파일), 인스턴스는 프로세스
- 메모리 구성
- 각 프로세스는 독립적인 메모리 공간을 가짐
- 서로의 메모리에 직접 접근 불가
- 특정 프로세스에 심각한 문제가 발생해도 다른 프로세스에 영향 X (해당 프로세스만 종료)
- 구성
- 코드 섹션: 실행할 프로그램의 코드가 저장되는 부분
- 데이터 섹션: 전역 변수 및 정적 변수가 저장되는 부분 (위 그림의 기타에 포함)
- 힙: 동적으로 할당되는 메모리 영역
- 스택: 메서드(함수) 호출 시 생성되는 지역 변수와 반환 주소의 저장 영역 (스레드에 포함)
- 각 프로세스는 독립적인 메모리 공간을 가짐
- 하나 이상의 스레드를 반드시 포함
-
운영체제 안에서 실행 중인 프로그램
- 스레드
-
프로세스 내에서 실행되는 작업 단위
- CPU를 사용해 코드를 하나하나 실행
- 메모리 구성
- 공유 메모리
- 한 프로세스 내 여러 스레드들은 프로세스가 제공하는 메모리 공간을 공유
- e.g. 코드 섹션, 데이터 섹션, 힙, 스택을 프로세스 안 모든 스레드가 공유
- 개별 스택
- 각 스레드는 자신의 스택을 가짐
- 공유 메모리
- 프로세스보다 생성 및 관리가 단순하고 가벼움
-
프로세스 내에서 실행되는 작업 단위
- 멀티스레드가 필요한 이유
- 하나의 프로그램도 그 안에서 동시에 여러 작업이 필요하다
- e.g.
- 워드 프로그램 - 프로세스A
- 스레드1: 문서 편집
- 스레드2: 자동 저장
- 스레드3: 맞춤법 검사
- 유튜브 - 프로세스B
- 스레드1: 영상 재생
- 스레드2: 댓글
- 워드 프로그램 - 프로세스A
- 멀티스레드도 단일 코어 스케줄링 & 멀티 코어 스케줄링 모두 발생 가능
프로그램 실행
프로그램을 실행하면 운영체제는 먼저 디스크에 있는 파일 덩어리인 프로그램을 메모리로 불러와 프로세스를 만든다. 프로그램이 실행된다는 것은 사실 프로세스 안에 있는 코드가 한 줄씩 실행되는 것이다.
코드는 보통main()부터 시작해서 스레드가 하나씩 순서대로 내려가면서 실행한다.
한 프로세스 안에는 최소 하나의 스레드가 존재한다. 그래야 프로그램이 실행될 수 있다.
CPU 스케줄링
- 운영체제가 CPU에 어떤 프로그램을 얼마만큼 실행할지 결정하는 것
- CPU를 최대한 활용할 수 있는 다양한 우선순위와 최적화 기법 사용
- e.g. 시분할 기법 (Time Sharing, 시간 공유)
- 각 프로그램의 실행 시간을 분할해서 마치 동시에 실행되는 것처럼 하는 기법
- 운영체제는 내부에 스케줄링 큐를 가지고, 각각의 스레드는 스케줄링 큐에서 대기
- 스레드들이 운영체제한테 내가 실행되어야 한다고 알리면 운영체제는 해당 스레드들을 큐에 넣음
- 운영체제는 큐에서 대기중인 스레드를 하나씩 꺼내 CPU를 통해 실행
- 스레드는 CPU 연산을 통해 프로그램 코드를 수행
- 운영체제는 10ms 정도 후 작업 중인 스레드를 잠시 멈추고 다시 스케줄링 큐에 넣음
- 스케줄링 큐에서 다음 스레드를 꺼내 CPU를 통해 실행
- 반복…
단일 스레드: 한 프로세스 내에 하나의 스레드만 존재
멀티 스레드: 한 프로세스 내에 여러 스레드가 존재
컨텍스트 스위칭 (Context Switching)
- CPU는 컴퓨터에 있는 여러 Process, 여러 Thread 들을 돌아가면서 실행함
- 컨텍스트 (Context)
- Process나 Thread가 중단 됐다가 다시 실행될 때 필요한 정보
- 컨텍스트 스위칭 (Context Switching)
- 현재 실행 중인 Context를 잠시 중단 및 저장하고 새로운 Context를 로딩 및 실행하는 것
- 멈춰지는 스레드는 수행 위치와 CPU에서 사용하던 변수 값들을 메모리에 저장
- 실행하는 스레드는 수행 위치와 CPU에서 사용하던 변수 값들을 메모리에서 CPU로 불러옴
- 컨텍스트 스위칭 발생 시 CPU Cache가 초기화됨
- 다른 코드 수행을 위해 Cache를 비우고 새로 메모리를 읽어 Caching함
- 값을 저장하고 불러오는 과정은 약간의 비용을 발생시킴
- 실제로 컨텍스트 스위칭 시간은 짧지만, 스레드가 매우 많다면 비용이 커질 수 있음
- 유력한 발생 시점
- Sleep
- Lock
- I/O 작업 (Network I/O, File I/O, Console 출력)
- 시스템 API 호출
- 혹은 큰 단위 계산을 할 때 컨텍스트 스위칭 발생 가능성 높음
- 현재 실행 중인 Context를 잠시 중단 및 저장하고 새로운 Context를 로딩 및 실행하는 것
-
멀티스레드는 대부분 효율적이지만, 컨텍스트 스위칭 과정이 필요하므로 항상 효율적이진 않음
- 90% 경우는 효율적, 1~3% 경우는 비효율적
- 예시
- CPU 코어가 2개이고 스레드 2개 만들어 연산
- 2배 빠르게 처리 가능 (효율적)
- CPU 코어가 1개인데 스레드 2개 만들어 연산
- 연산 시간 + 컨텍스트 스위칭 시간 (비효율적)
- 단일 스레드로 연산하는 것이 오히려 효율적
- CPU 코어가 2개이고 스레드 2개 만들어 연산
스레드 숫자 최적화 전략
- CPU 개수와 스레드 개수
- CPU 4개, 스레드 2개
- CPU 100% 활용 X, 컨텍스트 스위칭 비용은 감소
- 컨텍스트 스위칭이 일어날 수는 있지만 거의 없을 것
- CPU 4개, 스레드 100개
- CPU 100% 활용 O, 컨텍스트 스위칭 비용 증가
- CPU 4개, 스레드 4개
- 최적 상태 (CPU 100% 활용 O, 컨텍스트 스위칭 비용 거의 X)
- 스레드 개수로 CPU 코어 개수 + 1개가 이상적 (특정 스레드 대기 시 남은 스레드 활용 가능)
- CPU 4개, 스레드 2개
- 스레드 작업 유형
- CPU 바운드 작업
- CPU 연산 능력을 많이 요구하는 작업
- e.g. 복잡한 수학 연산, 데이터 분석, 비디오 인코딩, 과학적 시뮬레이션…
- I/O 바운드 작업
- 입출력(I/O) 작업을 많이 요구하는 작업 (대기 시간으로 인해 CPU 유휴 상태 빈번)
- e.g. DB 쿼리 처리, 파일 읽기/쓰기, 네트워크 통신, 사용자 입력 처리…
- CPU 바운드 작업
- 실무 전략
-
스레드 숫자는 작업 유형에 따라 다르게 설정해야 한다!
- CPU 바운드 작업: CPU 코어 수 + 1개
- CPU를 거의 100% 사용하는 작업이므로 스레드를 CPU 숫자에 최적화
- I/O 바운드 작업: CPU 코어 수 보다 많은 스레드 생성
- 성능 테스트 통해 CPU를 최대한 활용하는 최적의 스레드 개수 찾을 것!
- 너무 많은 스레드는 컨텍스트 스위칭 비용 증가
- CPU 바운드 작업: CPU 코어 수 + 1개
-
웹 애플리케이션 서버 실무는 I/O 바운드 작업이 많음 -> CPU 코어 수 보다 많은 스레드 생성할 것!
- 사용자 요청 1개 처리 -> 스레드 1개 필요 (CPU 1%)
- I/O 작업(DB 쿼리 대기 등)을 생각하면 스레드는 CPU를 거의 사용하지 않고 대기
- 이 경우 CPU 코어가 4개 있다고 해서 스레드도 4개만 만들면 안됨
- 동시에 4명의 사용자 요청만 처리 -> CPU 4% 사용 -> CPU가 심하게 놀고 있음!
- 단순 생각해도 100개 스레드 생성 가능 (CPU 100%)
- 스레드 개수만 늘리면 되는데, 서버 장비를 늘리는 비효율적인 사태가 벌어지기도…
- 웹 애플리케이션 서버도 상황에 따라 CPU 바운드 작업이 많을 수 있음
- 이 때는 CPU 코어 수 + 1개 고려
-
스레드 숫자는 작업 유형에 따라 다르게 설정해야 한다!
스레드 생성 및 실행
- 스레드 생성과 메모리
-
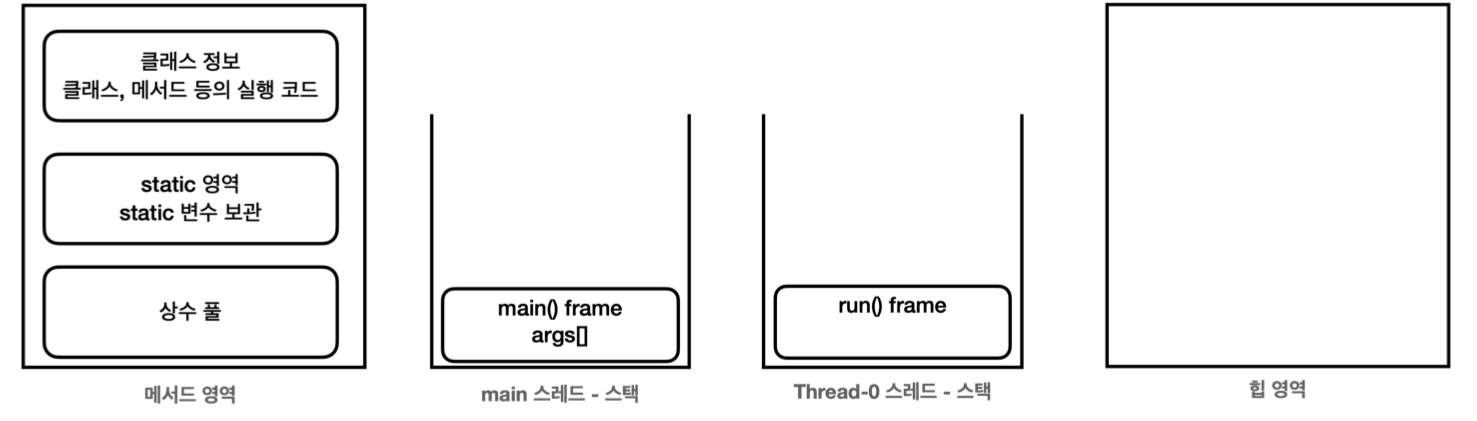
자바는 실행 시점에
main이라는 이름의 스레드를 만들고, 프로그램의 시작점인main()메서드 실행 -
새로운 스레드를 생성 및 시작하면 자바는 스레드를 위한 실행 스택을 할당
-
start()메서드- 새로운 스레드를 실행
-
main스레드는 다른 스레드에게 일을 시작하라고 지시만 하고 바로 빠져나옴
- 스레드에 이름을 주지 않으면 임의의 이름 부여 (
Thread-0,Thread-1…)
-
-
메서드를 실행하면 스택 위에 스택 프레임이 쌓임
-
main스레드는main()메서드 스택 프레임 올리며 시작 -
새로 만든 스레드는
run()메서드 스택 프레임 올리며 시작
-
-
자바는 실행 시점에
- 유의점
- 반드시
run()메서드가 아닌start()메서드 호출해야 함-
start()호출 O -> 실행 스택 생성되고 별도의 스레드로 작동 -
start()호출 X ->run()호출은 단순 함수 실행, 생성한 스레드도 단순한 객체일 뿐- 일반적인 메서드 호출 (
main스레드의 실행 스택 위에서 실행)
- 일반적인 메서드 호출 (
-
-
스레드 간 실행 순서를 보장하지 않음 -> 이것이 멀티스레드!
-
스레드는 동시에 실행되므로 스레드 간 실행 순서는 얼마든지 달라질 수 있음
- CPU 코어가 2개여서 물리적으로 정말 동시에 실행될 수도 있고
- 하나의 CPU 코어에 시간을 나누어 실행할 수도 있음
-
스레드는 동시에 실행되므로 스레드 간 실행 순서는 얼마든지 달라질 수 있음
- 반드시
- 생성 방법
-
Runnable인터페이스 구현 (권장)- 정의
public class HelloRunnable implements Runnable { @Override public void run() { System.out.println(Thread.currentThread().getName() + ": run()"); } } - 실행
Thread thread = new Thread(new HelloRunnable());thread.start()
-
더 유연하고 유지보수하기 좋은 방식
-
상속이 자유로움 (
Thread상속 방식은 다른 상속이 불가능) - 스레드와 작업 코드가 서로 분리되어 가독성 상승
- 여러 스레드가 동일한
Runnable객체를 공유할 수 있어 자원 관리가 효율적
-
상속이 자유로움 (
- 정의
-
Thread클래스 상속- 정의
public class HelloThread extends Thread { @Override public void run() { System.out.println(Thread.currentThread().getName() + ": run()"); } } - 실행
HelloThread thread = new HelloThread();thread.start()
- 자바는 스레드도 객체로 다룸
- 스레드가 실행할 코드를
run()메서드에 재정의
- 정의
-
Thread주요 메서드
Thread.currentThread(): 해당 코드를 실행하는 스레드 객체 조회 가능
Thread.currentThread().getName(): 실행 중인 스레드의 이름을 조회
Runnable 인터페이스와 체크 예외
자식 클래스가 부모보다 더 넓은 범위의 예외를 던지면, 일관성을 해치고 예상치 못한 런타임 오류를 초래할 수 있다.
따라서, 자바에서는 메서드 재정의 시 다음과 같은 예외 관련 규칙을 적용한다.
- 부모 메서드가 체크 예외를 던지지 않는 경우, 자식 재정의 메서드도 던질 수 없다.
- 자식 메서드는 부모 메서드가 던질 수 있는 체크 예외의 하위 타입만 던질 수 있다.
- 언체크 예외는 강제하지 않으므로 상관없이 던질 수 있다.
Runnable인터페이스의run()메서드는 어떤 예외도 던지지 않기 때문에, 개발자는run()메서드 재정의시 반드시try-catch블록 내에서 체크 예외를 처리해야 한다.
예를 들어, 유틸리티 메서드를 하나 만들어, 내부에서try-catch로 체크 예외를 잡고 언체크 예외로 변경해 재발생시키는 방법도 있다.
this와 스레드
this는 호출된 인스턴스 메서드가 소속된 객체를 가리키는 참조이며, 스택 프레임 내부에 저장된다.메서드를 호출하는 것은 정확히는 특정 스레드가 어떤 메서드를 호출하는 것이다. 스레드는 메서드 호출을 관리하기 위해 메서드 단위로 스택 프레임을 만든다. 이 때 인스턴스 메서드를 호출하면 어떤 인스턴스 메서드를 호출했는지 기억하기 위해 해당 인스턴스의 참조값을 스택 프레임 내부에 저장해두는데, 이것이
this다.따라서, 특정 메서드 안에서
this를 호출하면 스택프레임 내의this값을 불러서 사용하고 필드 접근시this를 생략하면 자동으로this를 참고해 필드에 접근한다.참고로 인스턴스 메서드는
this가 있지만 클래스 메서드는this가 없다.
데몬 스레드 (Daemon Thread)
- 스레드는 2가지 종류로 구분
- 사용자 스레드
- 프로그램의 주요 작업 수행
- 모든 사용자 스레드가 종료되면 JVM도 종료
- Main 뿐만 아니라 다른 사용자 스레드까지 모두 종료되어야 자바 종료 (중간에 작업 끊김 X)
- 데몬 스레드
- 백그라운드에서 보조적인 작업 수행
- 모든 사용자 스레드가 종료되면 JVM이 종료되고 데몬 스레드도 자동 종료 (작업 끊김)
- 사용자 스레드
- 데몬 스레드 실행 방법
thread.setDaemon(true) // 데몬 스레드로 설정 (기본값은 false, user 스레드가 기본)thread.start() // 데몬 스레드 여부는 start() 실행 이후에는 변경되지 않음
데몬
컴퓨터 과학에서는 사용자에게 보이지 않으면서 시스템의 백그라운드에서 작업을 수행하는 것을 데몬 스레드, 데몬 프로세스라고 한다. 예를 들어, 사용하지 않는 파일이나 메모리를 정리하는 작업들이 있다.
스레드 기본 정보
- 스레드 이름 부여
-
Thread myThread = new Thread(new HelloRunnable(), "myThread");- 스레드 이름이 “myThread”
- 디버깅, 로깅 목적으로 유용
-
-
Thread클래스 메서드-
threadId(): 스레드 고유 식별자 반환 (JVM 내 각 스레드에 대해 유일) -
getName(): 스레드 이름 반환 (스레드 이름은 중복 가능) -
getPriority(): 스레드의 우선순위 반환 (1: 가장 낮음 ~ 10: 가장 높음, 기본값: 5)-
setPriority()로 변경 가능하지만, 실제 실행 순서는 운영체제에 달려있음
-
-
getThreadGroup(): 스레드가 속한 그룹을 반환 -
getState(): 스레드의 현재 상태를 반환 (Thread.State열거형에 정의된 상수)- NEW, RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, TERMINATED
-
부모 스레드
새로운 스레드를 생성하는 스레드를 의미한다.
스레드는 기본적으로 다른 스레드에 의해 생성된다. (main스레드는 제외)
스레드 그룹
직접적으로 잘 사용하지 않는다. 스레드를 그룹화하여 관리할 수 있는 기능을 제공한다.
스레드 그룹에는 특정 작업을 일괄적으로 적용할 수 있다. (e.g. 일괄 종료, 우선순위 설정)
모든 스레드는 부모 스레드와 동일한 스레드 그룹에 속한다.
main스레드는 기본으로 제공되는main스레드 그룹에 속한다.
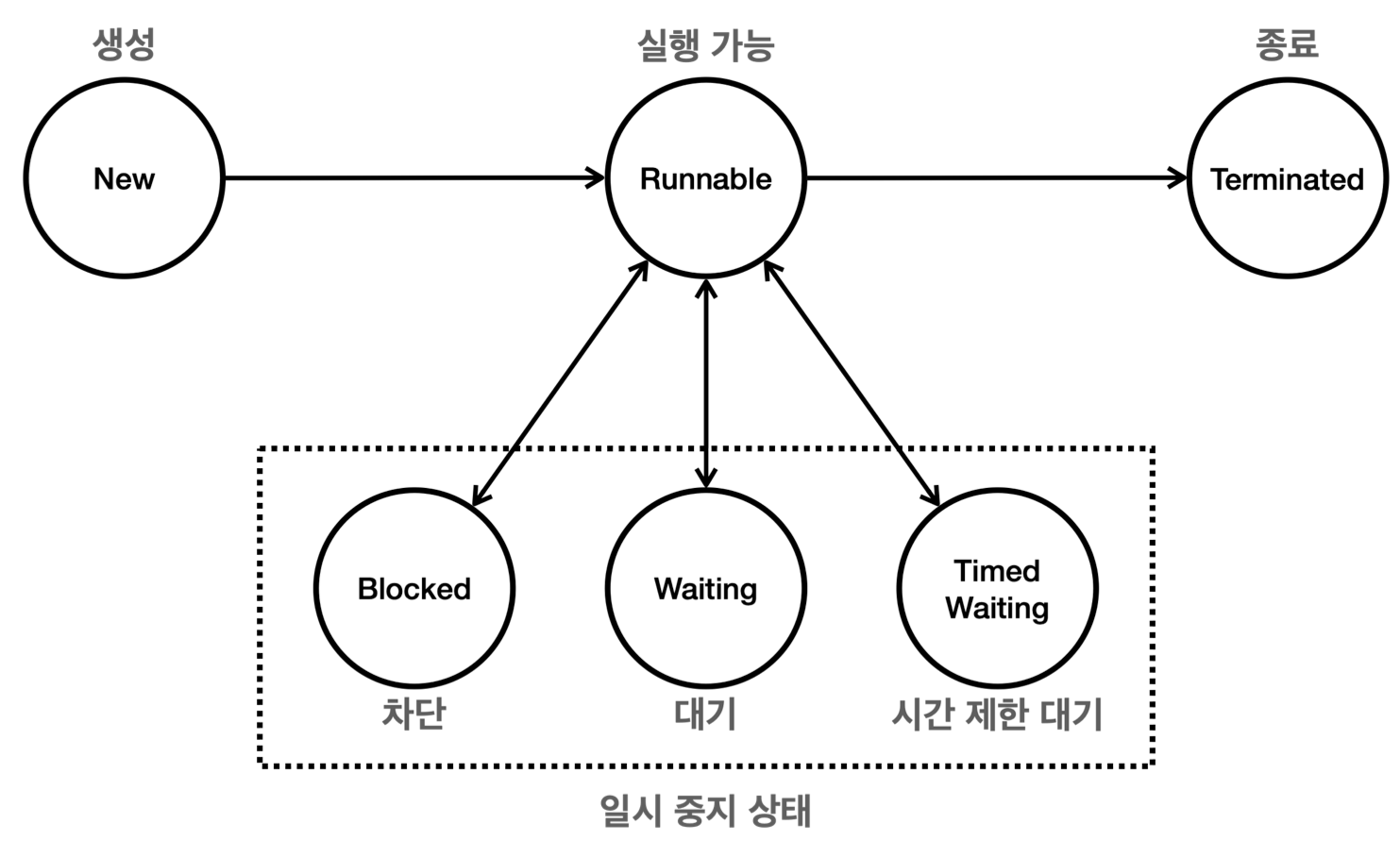
스레드의 생명 주기
-
NEW- 스레드가 생성되었으나 아직 시작되지 않은 상태
-
Thread객체는 생성되었지만start()메서드가 호출되지 않음
-
RUNNABLE- 스레드가 실행 중이거나 실행될 준비가 된 상태 (=CPU에서 실행될 수 있음)
-
start()메서드 호출 후 상태 -
RUNNABLE상태의 모든 스레드가 동시 실행되지는 않음 (운영체제 스케줄러가 CPU 할당하기 때문) - 자바에서는 운영체제 스케줄러에 있든 CPU에서 실제 실행되고 있든 모두
RUNNABLE상태 (구분 X)
-
TERMINATED- 스레드가 실행을 마친 상태 (
run()메서드 정상 종료 혹은 예외 발생 종료) - 스레드는 한 번 종료되면 다시 시작할 수 없음 (새로 만들어서 실행해야 함)
- 스레드가 실행을 마친 상태 (
-
일시 중지 상태
-
BLOCKED- 스레드가 동기화 락을 기다리는 상태
-
synchronized블록 진입 위해 락 획득 대기할 때
-
WAITING- 스레드가 다른 스레드의 특정 작업 완료를 무기한 기다리는 상태
- e.g.
wait(),join()혹은LockSupport.park()호출 시 - 다른 스레드가
notify(),notifyAll()호출하거나join()이 완료될 때까지 기다림
-
TIMED_WAITING- 스레드가 다른 스레드의 특정 작업 완료를 일정 시간 동안 기다리는 상태
- e.g.
sleep(long millis),wait(long timeout),join(long millis)
혹은LockSupport.parkNanos(ns)호출 시 - 주어진 시간이 경과하거나 다른 스레드가 해당 스레드를 깨우면 이 상태를 벗어남
-
다른 스레드의 작업 기다리기 - join()
-
다른 스레드의 작업 완료를 기다려하는 상황에 사용
-
join(): 무한정 기다릴 때 사용 (WAITING) -
join(ms): 특정 시간만 기다릴 때 사용 (TIMED_WAITING)
-
- 진행 과정
- 호출 스레드는
WAITING상태가 됨 - 대상 스레드가
TERMINATED상태가 될 때까지 대기- 대상 스레드가
TERMINATED상태가 되면RUNNABLE상태가 되어 다음 코드 수행 - 대상 스레드가 이미
TERMINATED상태라면 바로 빠져나옴
- 대상 스레드가
- 호출 스레드는
- e.g. 연산을 두 개의 스레드로 나누어 진행하고 완료된 후 결과를 합쳐 사용
-
thread-1: 1 ~ 50까지 더하기 -
thread-2: 51 ~ 100까지 더하기 -
main: 두 스레드의 계산 결과를 받아 합치기
-
스레드 작업을 중간에 중단하기
-
다른 스레드의 작업을 중간에 중단하기
-
인터럽트 (권장)
-
대기 상태의 스레드(
WAITING,TIMED_WAITING…)를 직접 깨워,RUNNABLE상태로 변경 - 작업 중단 지시 후, 거의 즉각적으로 인터럽트 발생
- 인터럽트 상태가 되면
InterruptedException예외 발생- 상태 변화
- 인터럽트 상태(
true) ->InterruptedException-> 인터럽트 상태(false)
- 인터럽트 상태(
-
InterruptedException을 던지는 메서드를 호출하거나 호출 중일 때만 예외가 발생- e.g.
Thread.sleep(),join() - 일반 코드에서는 예외가 발생하지 않음
- e.g.
- 상태 변화
- 관련 메서드
-
interrupt(): 특정 스레드에 인터럽트 걸기 -
isInterrupted(): 인터럽트 상태 단순 확인 (인터럽트 상태 변경 X) -
interrupted(): 인터럽트 상태를 확인 및 상태 변경- 스레드가 인터럽트 상태면
true를 반환 및 인터럽트 상태false로 변경 - 스레드가 인터럽트 상태가 아니면
false를 반환 (상태 변경 X)
- 스레드가 인터럽트 상태면
-
- 인터럽트 직접 체크 시,
interrupted()사용할 것! (withinterrupt())-
InterruptedException을 던지는 메서드가 없을 때도 인터럽트 사용 가능 -
isInterrupted()는 인터럽트 상태가true로 남겨진 채 유지됨- 다른 곳에서도 계속 인터럽트가 발생할 수 있어 위험
-
- 방법 예시
- Task 주요 코드 (Runnable)
while (!Thread.interrupted()) {...}
-
main스레드가thread.interrupt()실행해work스레드에 인터럽트 지시
- Task 주요 코드 (Runnable)
-
대기 상태의 스레드(
- 변수 사용하기
- 방법 예시
- Task 주요 코드 (Runnable)
volatile boolean runFlag = true;while (runFlag) {...}
-
main스레드가runFlag = false;를 실행해work스레드에 작업 중단 지시
- Task 주요 코드 (Runnable)
- 문제점
-
work스레드가 작업 중단 지시에 바로 반응 불가 (반응성이 느림) -
while조건문을 읽을 때에서야 인지하므로 루프 내 작업이 길다면, 반응이 더 느려짐
-
- 방법 예시
-
인터럽트 (권장)
-
스레드 스스로 작업을 중간에 중단하기 (
yield, 양보하기)- 현재 스레드가 크게 바쁘지 않다면, 스케줄링 큐에 대기 중인 다른 스레드에게 CPU 실행 기회를 양보
- 현재 스레드는 다시 스케줄링 큐로 돌아감 (
RUNNABLE상태 유지) - CPU 코어 수보다 많은 스레드가 있을 때 의미가 있음
-
yield는 스케줄러에게 힌트만 줄 뿐, 실행 순서 강제 X- 굳이 양보할 필요 없는 상황이면 본인 스레드 계속 실행 (운영체자가 최적화)
- 구현 예시
while (!Thread.interrupted()) { if (jobQueue.isEmpty()) { Thread.yield(); // 추가 continue; } ... }- 최대한 실시간으로 확인 원할 시
yield()가 효율적 - 만일 좀 더 오래 기다려도 될 것 같아 CPU 사용을 최대한 줄이고 싶다면
sleep()도 괜찮음
- 최대한 실시간으로 확인 원할 시
- 참고:
sleep()의 단점- 복잡한 상태 변화 과정 (
RUNNABLE->TIMED_WAITING->RUNNABLE) - 특정 시간만큼 스레드가 실행되지 않음 (양보할 상황이 아닌데도 휴식)
- 복잡한 상태 변화 과정 (
메모리 가시성 (Memory Visibility)
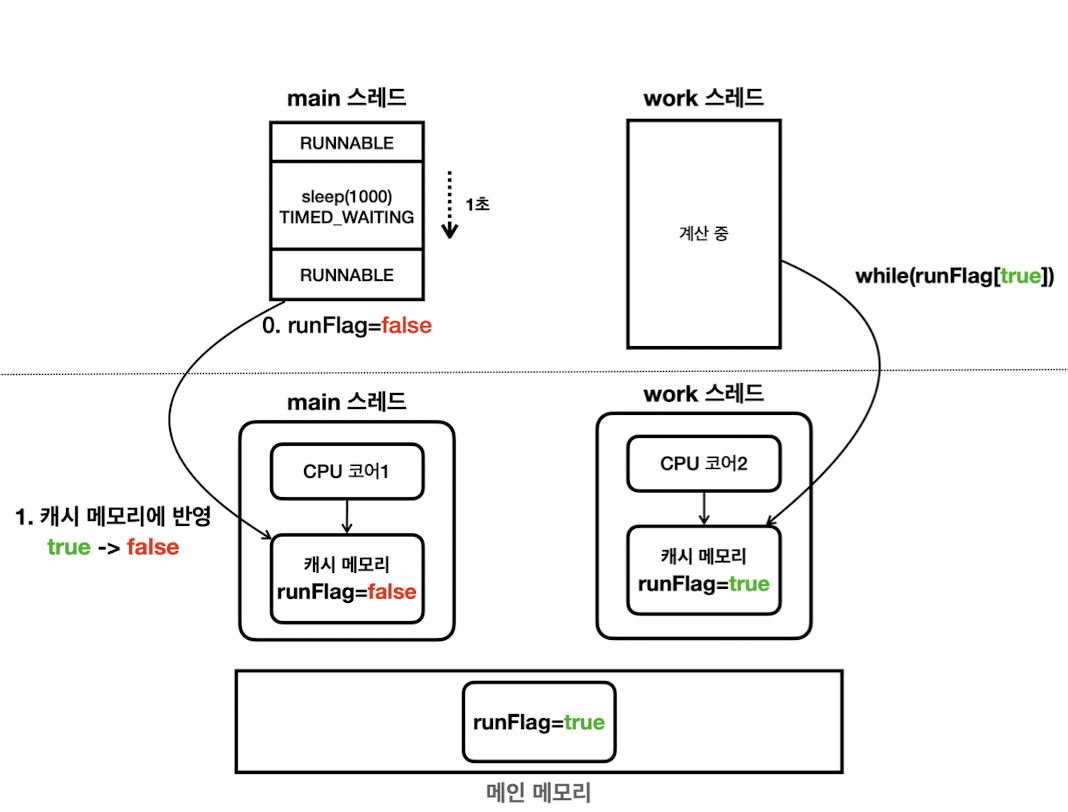
- 멀티 스레딩 환경에서 한 스레드가 변경한 값이 다른 스레드에서 언제 보이는지에 대한 문제
- 다른 스레드는 캐시에서Stale Data(오래된 데이터) 읽을 수 있음
- CPU와 캐시 메모리
- CPU는 처리 성능을 개선하기 위해 캐시 메모리를 사용 (L1, L2, L3 캐시…)
- 현대 CPU는 코어 단위로 캐시 메모리를 보유
-
각 스레드가 각자의 캐시 메모리를 바라보고 작업해 서로 값 변경을 감지하지 못함
- 스레드가 특정 변수 값 사용 시, 점유하는 코어의 캐시 메모리로 값을 불러옴 (From 메인 메모리)
- 값 변경 시, 캐시 메모리의 값만 변경 (메인 메모리에 즉시 반영 X)
-
메인 메모리 반영 및 읽기 시점은 알 수 없음!
- 주로 컨택스트 스위칭이 있을 때 캐시 메모리 함께 갱신 (
sleep(), 콘솔 출력…) - 그러나 환경마다 다르고 갱신이 일어나지 않을 수도 있음
- 주로 컨택스트 스위칭이 있을 때 캐시 메모리 함께 갱신 (
-
volatile
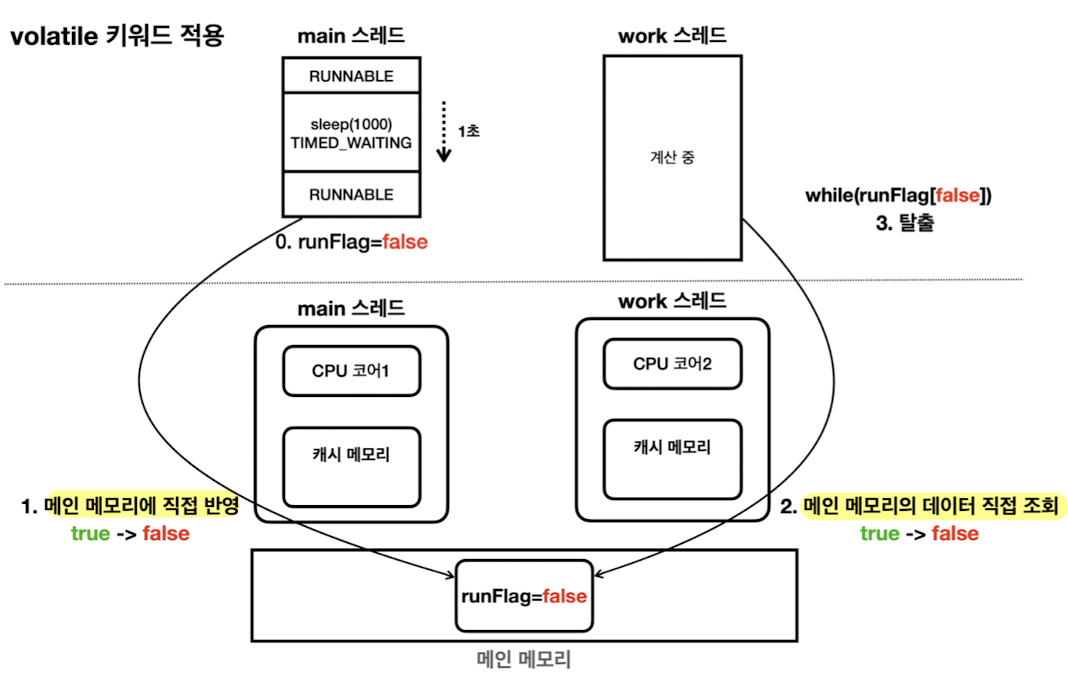
- 성능을 약간 포기하는 대신에, 값 읽기 및 쓰기를 모두 메인 메모리에 직접 접근해 진행
- 사용 상황
- 여러 스레드에서 같은 시점에 정확히 같은 데이터를 보는게 중요할 때 사용
- 캐시 메모리보다 성능이 떨어지므로 꼭 필요한 곳에만 사용! (약 5배 차이, 환경에 따라 다름)
Memory Wall
메모리 액세스 속도보다 CPU 처리 속도가 훨씬 빠르기 때문에 발생하는 문제를 말한다.
일반적으로 CPU에 캐시를 두어 속도를 개선한다. (L1, L2, L3)
자바 메모리 모델 (Java Memory Model)
자바 프로그램이 어떻게 메모리에 접근하고 수정할 수 있는지 규정한다. 특히, 멀티스레드 프로그래밍에서 여러 스레드들의 작업 순서를 보장하는 happens-before 관계를 정의한다.
만일 A happens before B 관계가 성립한다면, A 작업의 모든 메모리 변경 사항은 B 작업 시작 전에 메인 메모리에 반영되어 B 작업에서 볼 수 있다.
즉, 다른 스레드 작업의 최신 상태를 참조하는 것(메모리 가시성)을 보장한다. 이 규칙을 따르면, 멀티스레드 프로그래밍 시 예상치 못한 동작을 피할 수 있다.스레드 시작 및 종료, 인터럽트, 객체 생성 등의 규칙이 있지만 핵심은
volatile혹은 동기화 기법(synchronized,ReentrantLock)을 사용하면 메모리 가시성 문제가 발생하지 않는다는 점이다.
동시성 문제와 동기화
- 동시성 문제
- 멀티 스레드 상황에서 공유 자원에 여러 스레드가 동시에 접근할 때 발생
- e.g. 두 개 스레드가 계좌 출금 로직을 실행할 때, 둘 다 검증 로직을 통과해 잔액 없는데도 출금
-
근본 원인
- 공유자원에 대한 변경이 있는 연산을 여러 단계로 나누어 사용하는 것
- e.g. 출금은 검증 단계와 계산 단계로 나뉘어 있어 원자적이지 않은 연산
- 여러 단계 없이 원자적인 변경이라면 문제 없음
- 변경 없이 읽기만 한다면, 이것 역시 문제될 것이 없음
- 공유자원에 대한 변경이 있는 연산을 여러 단계로 나누어 사용하는 것
- 멀티 스레드에서는 공유 자원에 대한 접근을 적절하게 동기화해서 동시성 문제를 예방하는게 중요
- 동시성 문제가 있다면 메모리 가시성을 해결해도 문제가 지속됨
- 멀티 스레드 상황에서 공유 자원에 여러 스레드가 동시에 접근할 때 발생
- 임계 영역 (Critical Section)
-
공유 자원 접근 및 수정으로 인해 여러 스레드가 동시에 작업할 때 문제가 생기는 코드
- e.g. 임계영역 = 검증 단계 + 계산 단계
-
공유 자원 접근 및 수정으로 인해 여러 스레드가 동시에 작업할 때 문제가 생기는 코드
- 동기화 (Synchronization)
-
공유 자원에 대해 일관성 있고 안전한 접근을 보장하기 위한 메커니즘
- 임계 영역은 한 번에 하나의 스레드만 접근할 수 있도록 보호해야 함
-
멀티 스레드 상황에서의 동시성 문제를 해결하기 위해 사용
-
경합 조건(Race Condition) 해결
- 두 개 이상의 스레드가 경쟁적으로 동일한 자원을 수정할 때 발생하는 문제
- 데이터 정합성이 깨짐
-
데이터 일관성 해결
- 여러 스레드가 동시에 읽고 쓰는 데이터의 일관성 유지
- e.g. 입출금 예제 (1000원 잔액에서 두 개 스레드가 800원 출금 시도)
- 순차 실행 결과로 -600은 데이터 일관성이 있음 (숫자는 맞으니까)
- 완전 동시 실행 결과로 200은 데이터 일관성이 깨짐 (아얘 800원 증발)
-
경합 조건(Race Condition) 해결
- 멀티스레드 환경에서 필수적인 기능이지만, 성능저하 예방을 위해 꼭 필요한 곳에 사용해야 함
-
공유 자원에 대해 일관성 있고 안전한 접근을 보장하기 위한 메커니즘
- 동기화 기법
-
synchronized-
모니터 락을 사용해 동기화하는 방법
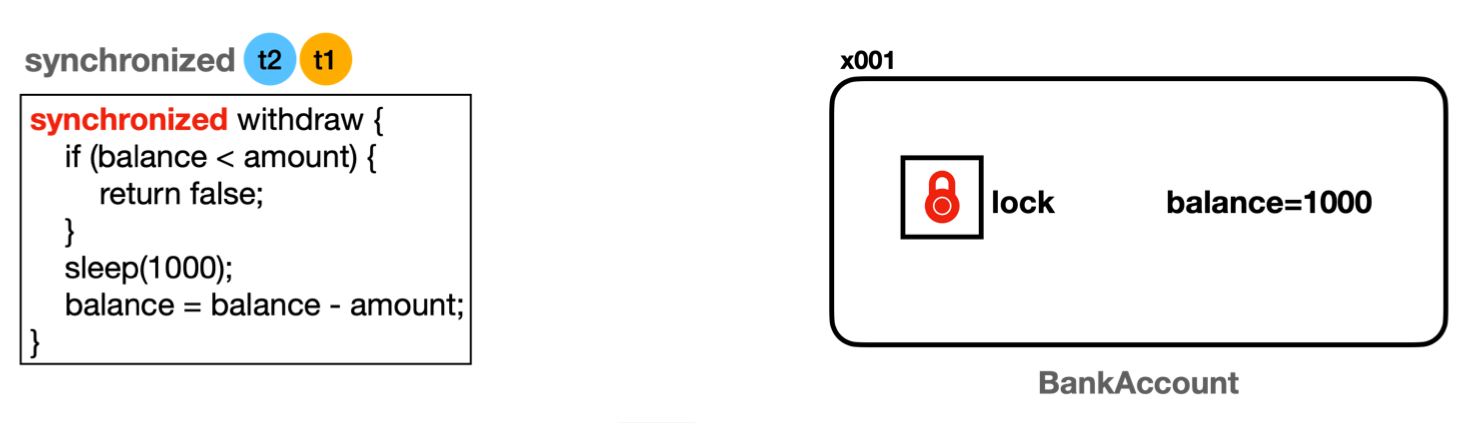
- 모니터 락(monitor lock)
- 모든 객체(인스턴스)가 내부에 가지고 있는 자신만의 락
- 자바 기본 제공
- 스레드가
synchronized메서드에 진입하려면 반드시 모니터 락을 얻어야 함
- 모니터 락(monitor lock)
- 적용 범위는 인스턴스 단위
- 한 스레드가
withdraw()실행 중일 때,
다른 스레드는withdraw()와getBalance()모두 호출 불가
- 한 스레드가
- 장점
- 프로그래밍 언어 문법으로 제공 (자바 1.0)
- 단순하고 편리한 사용
- 단점
- 무한정 대기 문제
-
BLOCKED상태 스레드는 락 획득까지 무한정 대기 - 타임아웃 or 인터럽트 불가능 - e.g. 웹의 경우 요청한 고객의 화면에 계속 요청 중만 뜨고 응답 X
-
- 공정성 문제
-
BLOCKED상태 스레드들의 락 획득 순서는 보장 X (자바 표준에 정의 X) - 최악의 경우 특정 스레드가 너무 오랜기간 락을 획득하지 못할 수 있음
-
- 무한정 대기 문제
- 예시 코드
- 메서드 동기화
public class BankAccountImpl implements BankAccount { private int balance; ... @Override public synchronized boolean withdraw(int amount) { ... } @Override public synchronized int getBalance() { ... } }- 클래스 내 모든 메서드에 일일이 키워드 적용하는게 일반적
- 블록 동기화 (권장)
@Override public boolean withdraw(int amount) { log("거래 시작: " + getClass().getSimpleName()); synchronized (this) { ... } log("거래 종료"); return true; }-
동기화 구간은 꼭 필요한 코드 블럭만 최소한으로 한정해 설정해야 함 (최적화)
- 동기화는 여러 스레드가 동시에 실행하지 못하므로 성능이 떨어짐
- 동시 처리 구간을 늘려서 전체적인 성능을 더 높일 수 있음
- 괄호 () 안에 들어가는 값은 락을 획득할 인스턴스의 참조
-
동기화 구간은 꼭 필요한 코드 블럭만 최소한으로 한정해 설정해야 함 (최적화)
- 메서드 동기화
-
모니터 락을 사용해 동기화하는 방법
-
ReentrantLock
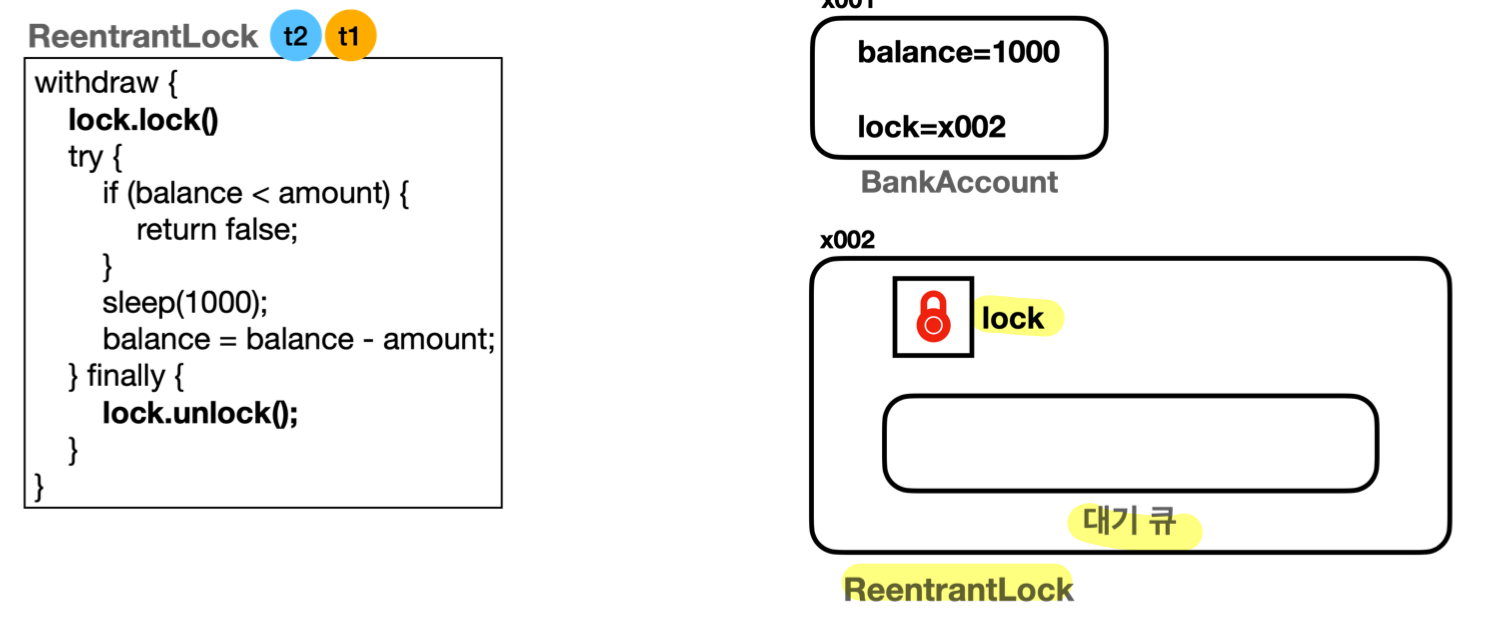
- 자바는 더 유연하고 세밀한 제어를 위한 동시성 문제 해결 라이브러리 패키지 지원
(java.util.concurrent, 자바 1.5)-
Lock인터페이스와ReentrantLock구현체 지원 (LockSupport활용) - 모니터 락이 아닌 자체적으로 구현한 락 사용
-
-
synchronized의 단점 극복- 무한 대기 문제 ->
LockSupport이용해 해결 - 공정성 문제 ->
ReentrantLock공정 모드 옵션으로 해결- 비공정 모드 (Non-fair mode) - 디폴트
private final Lock nonFairLock = new ReentrantLock();- 성능 우선: 락을 획득하는 속도가 빠름
- 선점 가능: 새 스레드가 대기 스레드보다 먼저 락 획득할 수도 있음
-
기아 현상 가능: 특정 스레드가 계속해서 락 획득 못할 수 있음
- 비공정 모드도 내부는 큐로 구현되어 있음
- 대부분의 경우 오래된 스레드 먼저 실행
- Race Condition 정말 심할 때 가끔 새치기 스레드 나올 수 있음
- 공정 모드 (Fair mode)
- 서비스에서 로직상 반드시 순서가 지켜져야 할 때 사용 (e.g. 선착순)
private final Lock fairLock = new ReentrantLock(true);- 공정성 보장: 먼저 대기한 스레드가 락을 먼저 획득
- 기아 현상 방지: 모든 스레드가 언젠가 락 획득할 수 있도록 보장
- 성능 저하: 락 획득 속도 느려짐
- 비공정 모드 (Non-fair mode) - 디폴트
- 무한 대기 문제 ->
-
LockSupport- 스레드를
WAITING상태로 변경 (BLOCKEDX, 무한 대기 문제 해결)-
unpark()로 깨울 수 있음 - 타임아웃 및 인터럽트도 가능해짐!
-
- 주요 기능
-
park(): 스레드를WAITING상태로 변경 -
parkNanos(nanos): 스레드를TIMED_WAITING상태로 변경 (지정 나노초) -
unpark(thread): 스레드를WAITING,TIME_WAITING->RUNNABLE변경- 대기 상태의 스레드는 외부 스레드의 도움을 받아야 깨어 날 수 있음 (파라미터)
-
-
LockSupport활용은 무한 대기하지 않는 락 기능 개발의 토대if (!lock.tryLock(10초)) { // 내부에서 parkNanos() 사용 log("[진입 실패] 너무 오래 대기했습니다."); return false; } //임계 영역 시작 ... //임계 영역 종료 lock.unlock() // 내부에서 unpark() 사용- 락(
lock) 클래스를 만들어 락 획득 및 반납에 따라 스레드 상태 변경 - 다만, 구현을 위해서는 대기 스레드를 위한 자료구조 및
스레드를 깨우는 우선순위 알고리즘도 필요하므로 복잡 - 자바는 저수준의
LockSupport를 활용하는 고수준의ReentrantLock구현해둠
- 락(
- 스레드를
-
Lock인터페이스public interface Lock { //락 획득 시도, 락 없을 시 WAITING, 인터럽트 반응 X //lock()은 인터럽트 시 잠깐 RUNNABLE 됐다가 강제로 WAITING 상태로 되돌림 void lock(); void lockInterruptibly() throws InterruptedException;//인터럽트O boolean tryLock(); //락 획득 시도, 성공 여부 즉시 반환 boolean tryLock(long time, TimeUnit unit) throws InterruptedException; //주어진 시간 동안 락 획득 시도, 이후 성공 여부 반환 void unlock(); //락 반납, 락을 획득한 스레드가 호출해야 함 //락과 결합해 사용하는 Condition 객체 생성 및 반환 //스레드가 특정 조건을 기다리거나 신호를 받을 수 있도록 함 Condition newCondition(); } - 예시 코드 1 - 무한정 대기 (
lock.lock())public class BankAccountImpl implements BankAccount { private int balance; private final Lock lock = new ReentrantLock(); ... @Override public boolean withdraw(int amount) { log("거래 시작: " + getClass().getSimpleName()); lock.lock(); // ReentrantLock 이용하여 lock을 걸기 try { ... } finally { lock.unlock(); // ReentrantLock 이용하여 lock 해제 } log("거래 종료"); return true; } @Override public int getBalance() { lock.lock(); // ReentrantLock 이용하여 lock 걸기 try { ... } finally { lock.unlock(); // ReentrantLock 이용하여 lock 해제 } } }- 스레드가 락을 획득하지 못하면
WAITING상태가 되고, 대기 큐에서 관리
(내부에서LockSupport.park()호출)
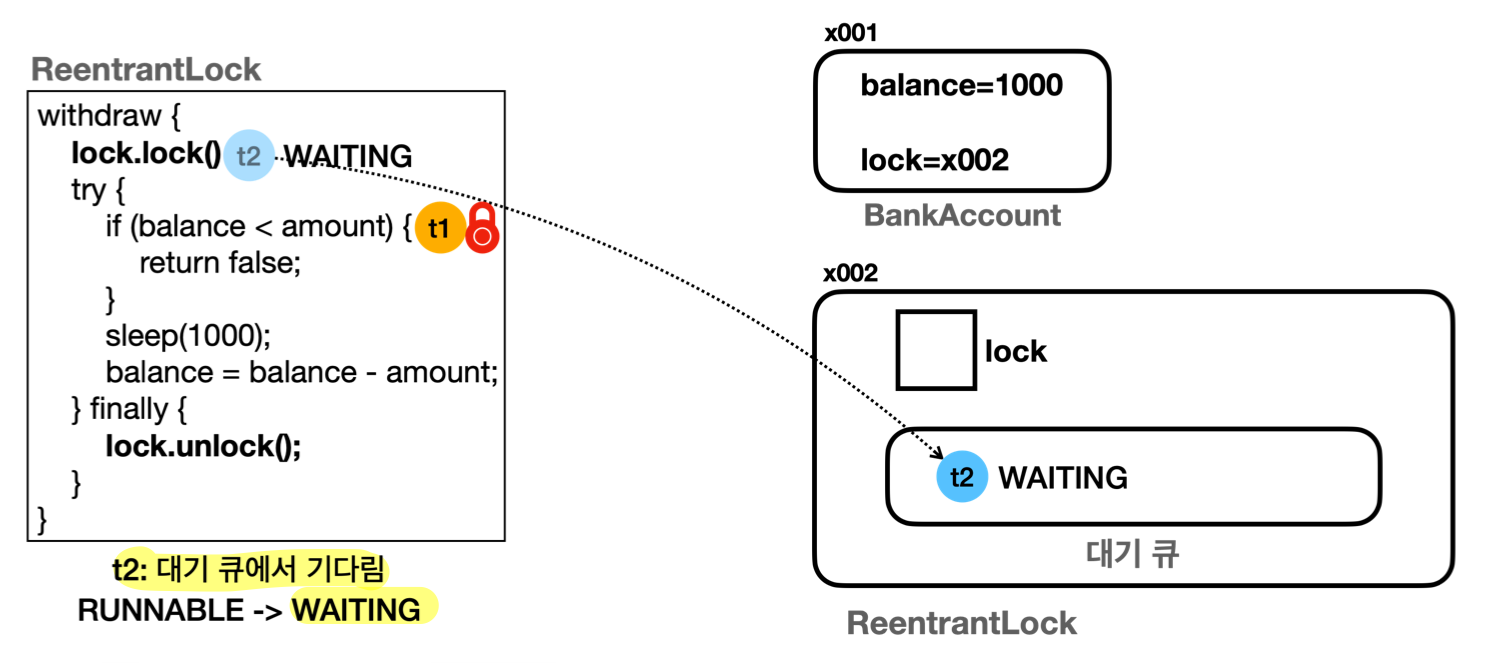
- 락 반납 시, 대기 큐의 스레드를 하나 깨움 (내부에서
LockSupport.unpark()호출)- 대기 큐에 스레드가 없을 시, 깨우지 않음
- 깨어난 스레드는 락 획득을 시도
- 락을 획득하면 대기 큐에서 제거
- 락을 획득하지 못하면 다시 대기 상태가 되면서 대기 큐에 유지
- 비공정 모드
- 락 획득을 시도하는 잠깐 사이에 새 스레드가 락을 먼저 가져갈 수 있음
- 경쟁: 새로 락을 호출하는 스레드 VS 대기 큐에 있는 스레드
- 공정 모드
- 대기 큐에 먼저 대기한 스레드가 락을 가져감
- 비공정 모드
- 스레드가 락을 획득하지 못하면
- 예시 코드 2 - 대기 빠져나오기 (
lock.tryLock())@Override public boolean withdraw(int amount) { log("거래 시작: " + getClass().getSimpleName()); // 대기 없이 획득 여부 바로 판단 if (!lock.tryLock()) { log("[진입 실패] 이미 처리중인 작업이 있습니다."); return false; } // 특정 시간만큼 대기 /** try { if (!lock.tryLock(500, TimeUnit.MILLISECONDS)) { log("[진입 실패] 이미 처리중인 작업이 있습니다."); return false; } } catch (InterruptedException e) { throw new RuntimeException(e); } **/ try { ... } finally { lock.unlock(); // ReentrantLock 이용하여 lock 해제 } log("거래 종료"); return true; }
- 자바는 더 유연하고 세밀한 제어를 위한 동시성 문제 해결 라이브러리 패키지 지원
-
공유 자원
여러 스레드가 접근하는 자원을 말한다. (e.g. 인스턴스 변수, 클래스 변수, 인스턴스 자체)
사실, 공유 자원은 원자적이지 않은 변경이 문제가 되는 것이므로,
final키워드가 붙은 공유자원은 멀티스레드 상황에 안전한 공유자원이다. 어떤 스레드도 값을 변경할 수 없기 때문이다.참고로, 지역 변수는 공유 자원이 아니므로 동시성 문제를 전혀 고민하지 않아도 된다.
지역 변수는 각각의 스레드가 가지는 별도의 스택 공간에 저장되어서 다른 스레드와 공유하지 않기 때문이다.
BLOCKEDVSWAITING(WAITING&TIMED_WAITING)두 상태 모두 스레드가 실행 스케줄링에 들어가지 않고 대기한다는 점에서 비슷한 상태이다. (CPU가 실행 X)
다만,
BLOCKED상태는synchronized에서만 사용되며 타임 아웃이나 인터럽트가 불가능하다.
반면에,WAITING상태는 범용적으로 사용되며 타임아웃이나 인터럽트를 통해 대기 상태를 빠져나올 수 있다.
생산자 소비자 문제
- 생산자 소비자 문제(producer-consumer problem)
- 여러 스레드가 동시에 특정 자원을 함께 생산하고 소비하는 상황
- 멀티스레드에서 자주 등장하는 동시성 문제
- = 한정된 버퍼 문제(bounded-buffer problem)
- 기본 개념
- 생산자(Producer)
- 데이터를 생성하는 역할
- e.g. 파일에서 데이터를 읽어오거나 네트워크에서 데이터를 받아오는 스레드
- 소비자(Consumer)
- 데이터를 사용하는 역할
- e.g. 데이터를 처리하거나 저장하는 스레드
- 버퍼(Buffer)
- 생산자가 생성한 데이터를 일시적으로 저장하는 공간
- e.g. 큐
- 생산자 소비자 모두 여럿일 수 있음
- 생산자(Producer)
- 문제 상황
- 생산자가 너무 빠를 때
- 생산자가 데이터를 빠르게 생성해 버퍼가 가득차면, 버퍼에 빈 공간이 생길 때까지 기다려야 함
- 소비자가 너무 빠를 때
- 소비자가 데이터를 빠르게 소비해 버퍼가 비면, 버퍼에 새 데이터가 들어올 때까지 기다려야 함
- 생산자가 너무 빠를 때
- 해결책
- 스레드를 제어할 수 있는 특별한 자료구조 사용
- 예제: 스레드를 제어하는 큐 만들기
- 기본 가정: 소비자 스레드와 생산자 스레드는 지속적으로 발생함 (생산자 소비자 구조는 계속 실행)
-
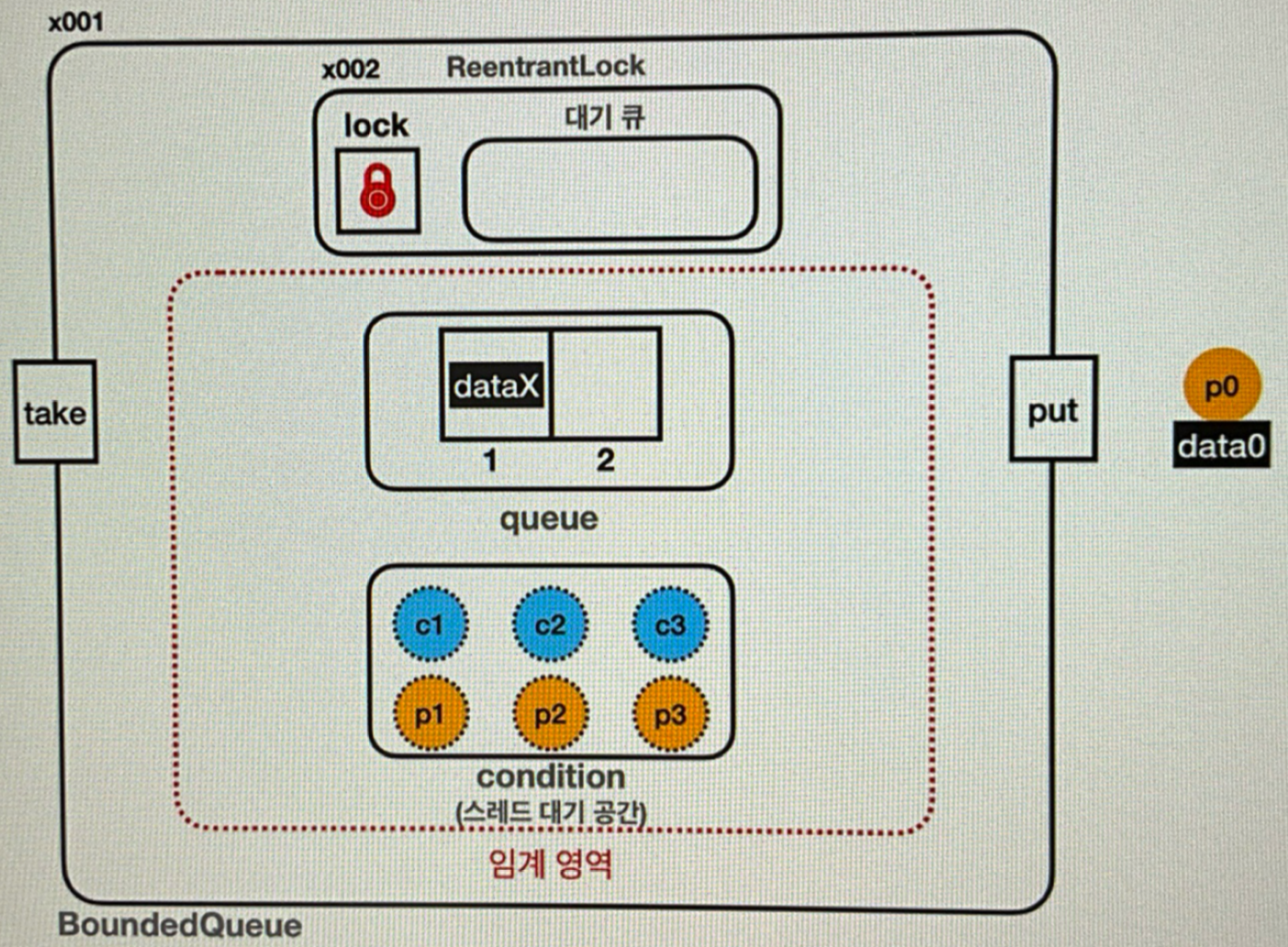
BoundedQueueV1- 특징
- 동기화한 큐 사용 (
take(),put()메서드를synchronized) - 생산자가 자원을 생산할 때, 큐가 가득찼다면 데이터를 버림
- 소비자가 자원을 소비할 때, 큐가 비었다면 아무일도 안하고
null반환
- 동기화한 큐 사용 (
- 문제
- 생산자가 데이터를 버리는 것이 비효율적 (기다림 X)
- 소비자가 데이터를 기다리지 않는 것이 비효율적 (기다림 X)
- 특징
-
BoundedQueueV2- 목표: 생산자 혹은 소비자 스레드가 기다리도록 하기
- 특징
- 생산자는 큐에 빈 공간이 생길 때까지 기다림
-
put()메서드 ->while (queue.size() == max) - 생산자 스레드는 반복문을 통해 큐에 빈공간이 생기는지 주기적으로 체크
-
- 소비자는 큐에 데이터가 추가될 때까지 기다림
-
take()메서드 ->while (queue.isEmpty()) - 소비자 스레드는 반복문을 통해 큐에 데이터가 추가되는지 주기적으로 체크
-
- 생산자는 큐에 빈 공간이 생길 때까지 기다림
- 문제
- 생산자나 소비자 스레드가 락을 가지고 대기하면, 다른 스레드들은
BLOCKED됨
(synchronized)
- 생산자나 소비자 스레드가 락을 가지고 대기하면, 다른 스레드들은
-
BoundedQueueV3- 목표
- 임계 영역 안에서 락을 가지고 기다리는 스레드가 락을 다른 스레드에게 양보하도록 하기
-
Object클래스를 통한 해결 (wait(),notify(),notifyAll())
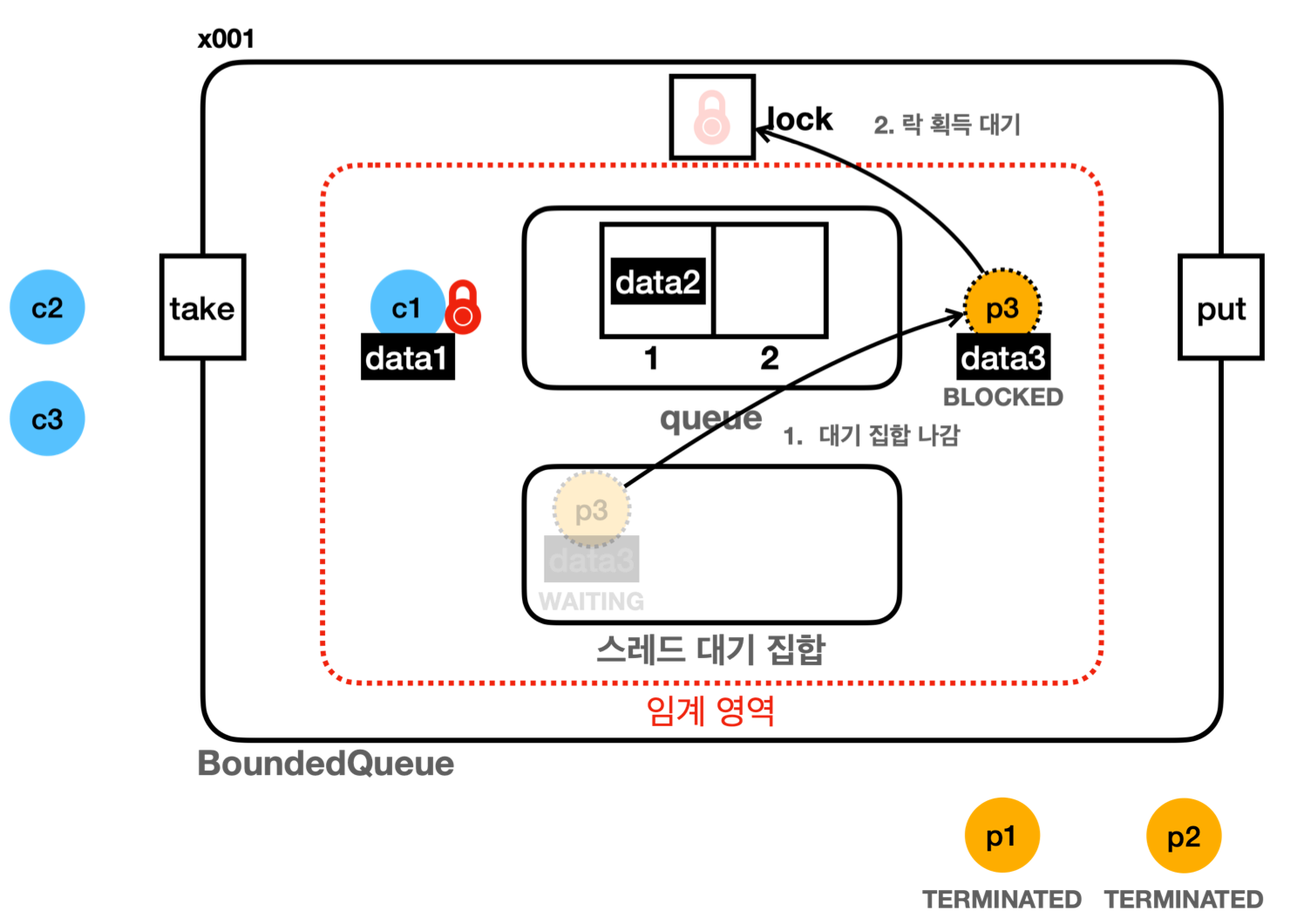
-
synchronized에서 비롯된 락 획득 후 임계영역 내 무한 대기 문제 해결 - 모든 객체가 사용 가능 (자바는 멀티스레드를 고려하며 탄생한 언어)
- 주요 메서드
- 유의점
- 모두
synchronized메서드 및 블록 내에서 호출되어야 함 - 대기하는 스레드는 스레드 대기 집합에서 대기
- 모두
-
Object.wait()- 현재 스레드가 가진 락을 반납하고 대기 (
WAITING, 스레드 대기 집합) - 다른 스레드가
notify(),notifyAll()을 호출할 때까지 대기 유지
- 현재 스레드가 가진 락을 반납하고 대기 (
-
Object.notify()- 스레드 대기 집합에서 대기 중인 스레드 중 하나를 깨움
- 대기 집합에서 어떤 스레드가 깨어날지는 예측 불가능
(JVM 스펙 명시 X)
- 대기 집합에서 어떤 스레드가 깨어날지는 예측 불가능
- 락을 다시 획득할 기회 얻음
- 깨어난 스레드는
WAITING->BLOCKED상태가 됨- 깨어난 스레드는 임계 영역 내에 있음
- 임계 영역 내 코드를 실행하려면 락이 필요
- 락 획득을 위해
BLOCKED상태로 대기
- 스레드 대기 집합에서 대기 중인 스레드 중 하나를 깨움
-
Object.notifyAll()- 스레드 대기 집합에서 대기 중인 모든 스레드를 깨움
- 모두 락 획득 기회를 얻음
- 깨어난 스레드는
WAITING->BLOCKED상태가 됨- 깨어난 스레드는 임계 영역 내에 있음
- 임계 영역 내 코드를 실행하려면 락이 필요
- 락 획득을 위해
BLOCKED상태로 대기
- 유의점
-
- 특징
- 생산자 -
put()- 반복문 내에서
wait()으로 락을 반납하고 큐의 빈 공간을 기다림 (WAITING) - 자원 생산에 성공하면
notify()로 대기 스레드를 깨우고 종료
- 반복문 내에서
- 소비자 -
take()- 반복문 내에서
wait()으로 락을 반납하고 큐의 데이터 추가를 기다림 (WAITING) - 자원 소비에 성공하면
notify()로 대기 스레드를 깨우고 종료
- 반복문 내에서
- 생산자 -
- 문제
- 생산자 소비자 모두 데이터를 정상 생산하고 정상 소비하나…
- 1) 스레드 대기 집합 하나에 생산자, 소비자 스레드를 함께 관리
- 2) 깨울 스레드 선택이 불가능 (
notify())-
같은 종류의 스레드를 깨울 때 비효율 발생
- 큐에 데이터가 없는데 소비자가 소비자를 깨우거나
큐가 가득 찼는데 생산자가 생산자를 깨우는 케이스 존재 - 깨어난 스레드가 CPU 자원만 소모하고 바로 다시 대기 집합에 들어가 비효율
- 큐에 데이터가 없는데 소비자가 소비자를 깨우거나
-
스레드 기아 상태 (
thread starvation) 발생- 최악의 경우 특정 스레드만 영원히 깨어나지 못할 수 있음
-
notify()가 어떤 스레드를 깨우는지 자바 스펙에 명기 X - 물론 보통은 오래 기다린 스레드가 깨어나도록 구현됨
-
- 큐에 데이터가 없는데 소비자 스레드만 계속 깨우거나
큐가 가득 찼는데 생산자 스레드만 계속 깨울 수 있음 -
notifyAll()을 사용하면 스레드 기아 상태를 막을 수 있으나 비효율은 지속
- 최악의 경우 특정 스레드만 영원히 깨어나지 못할 수 있음
-
같은 종류의 스레드를 깨울 때 비효율 발생
- 목표
-
BoundedQueueV4- 목표: 구현을
synchronized에서ReentrantLock으로 변경 - 특징
-
Lock인터페이스와ReentrantLock구현체 사용private final Lock lock = new ReentrantLock();-
private final Condition condition = lock.newCondition();-
ReentrantLock을 사용하는 스레드가 대기하는 스레드 대기 공간 -
Lock(ReentrantLock)을 사용하면 스레드 대기 공간을 직접 만들어야 함
-
- 변경 포인트
-
synchronized->lock.lock() -
wait()->condition.await()- 지정
condition에 현재 스레드를 대기(WAITING) 상태로 보관
- 지정
-
notify()->condition.signal()- 지정
condition에서 대기 중인 스레드를 하나 깨움 -
Condition은Queue구조를 사용하므로 FIFO 순서로 깨움
- 지정
-
-
- 목표: 구현을
-
BoundedQueueV5- 목표: 서로 다른 종류의 스레드를 꺠우도록 생산자용, 소비자용으로 스레드 대기 집합을 분리
- 특징
- 생산자와 소비자 스레드 대기 집합 분리 (
condition)private final Lock lock = new ReentrantLock();private final Condition producerCond = lock.newCondition();private final Condition consumerCond = lock.newCondition();
-
생산자는 소비자를 깨우고 소비자는 생산자를 깨움
- 생산자 -
put()- 큐가 가득 찬 경우:
producerCond.await() - 데이터 저장한 경우:
consumerCond.signal()
- 큐가 가득 찬 경우:
- 소비자 -
take()- 큐가 빈 경우:
consumerCond.await() - 데이터를 소비한 경우:
producerCond.signal()
- 큐가 빈 경우:
- 생산자 -
- 생산자와 소비자 스레드 대기 집합 분리 (
-
BlockingQueue- 자바는 생산자 소비자 문제 해결을 위해
BlockingQueue인터페이스와 구현체를 제공 - 큐가 특정 조건을 만족할 때까지 스레드를 차단할 수 있는 큐 (큐가 가득차거나 비어 있을 때)
- 실무 멀티스레드는 응답성이 중요하므로, 인터럽트나 타임아웃을 받을 수 있게 설계됨
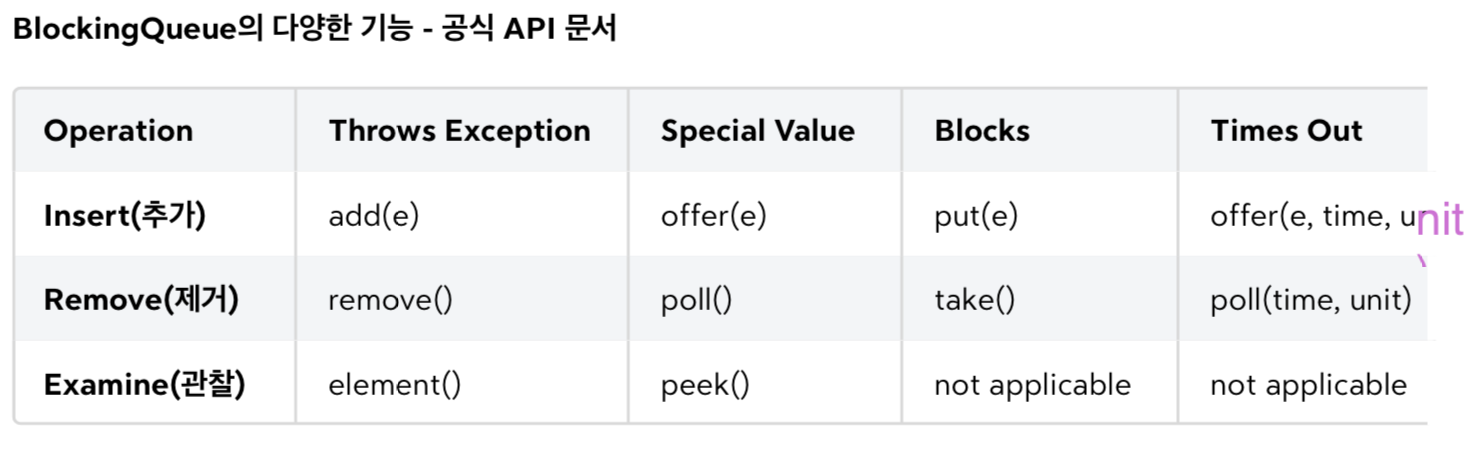
- e.g.
- 생산자 스레드(서버에 상품을 주문하는 고객)가 고객의 요청을 큐에 넣고
소비자 스레드는 큐에서 주문 요청을 꺼내 처리 - 선착순 할인 이벤트가 크게 성공해 주문이 폭주하면, 소비가 생산을 따라가지 못하고 큐가 가득 차게 될 수 있음
- 수 많은 생산자 스레드가 큐 앞에서 대기 (고객도 응답 없이 무한 대기)
- 너무 오래 기다리지 않고 데이터 추가 포기 및 고객에게 나중에 다시 시도해달라고 응답 보내는게 나은 선택
- 생산자 스레드(서버에 상품을 주문하는 고객)가 고객의 요청을 큐에 넣고
-
큐가 가득 찼을 때 생각할 수 있는 4가지 선택
- 대기 없이 예외 던지기 (Throws Exception)
- 대기 없이 즉시
false반환 (Special Value) - 대기 (Blocks) - 인터럽트 제공
- 특정 시간 만큼 대기 (Times Out) - 인터럽트 제공
- e.g.
- 자바는 생산자 소비자 문제 해결을 위해
synchronized와ReentrantLock의 유사성생산자 소비자 문제는 5, 60년대 해결된 개념이므로
synchronized와ReentrantLock은 유사한 모습을 보인다.ReentrantLock이 조금 더 편하게 쓸 수 있게 나왔을 뿐이다.
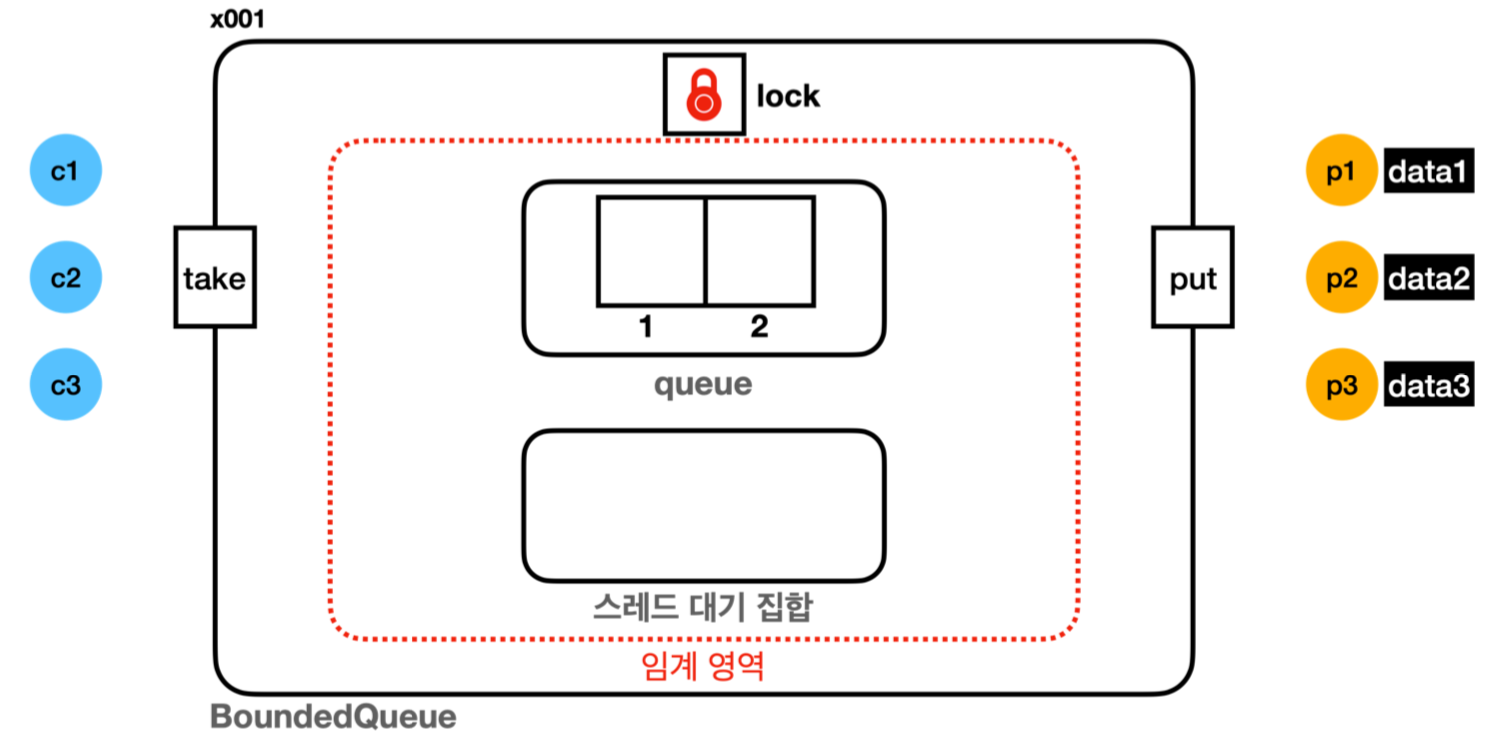
스레드 대기 집합 (wait set) & 락 대기 집합
자바의 모든 객체 인스턴스는 멀티스레드와 임계 영역을 다루기 위해 모니터 락, 락 대기집합, 스레드 대기 집합 3가지 기본 요소를 가지고 있다. (synchronized적용 상황)
synchronized에서 스레드의 대기는wait()대기, 락 획득 대기 2단계가 존재하며, 스레드 대기 집합은 2차 대기소, 락 대기 집합은 1차 대기소라 볼 수 있다.
만일 임의의 스레드들이 동시에 실행되면, 하나의 스레드가 락을 획득하고 나머지 스레드는 1차 대기소에 들어간다.
또한, 특정 스레드가wait()을 호출하면 2차 대기소로 들어가고notify()가 호출되면 2차 대기소에서 나와 락 획득을 시도하며, 락이 없을 경우 1차 대기소로 간다. 즉, 2차 대기소에 있는 스레드는 2차, 1차 대기소를 모두 빠져 나와야 임계 영역을 수행할 수 있다.스레드 대기 집합은 대기 상태에 들어간 스레드를 관리하는 것이다.
예를 들어,synchronized임계 영역 안에서Object.wait()을 호출하면, 스레드는 대기(WAITING) 상태에 들어가고 대기 집합 내에서 관리된다. 이후, 다른 스레드가Object.notify()를 호출하면 대기 집합에서 빠져나간다.
(참고로,wait()호출은 앞에this를 생략할 수 있다.this는 해당 인스턴스를 뜻한다.)락 대기 집합은 락을 기다리는
BLOCKED상태의 스레드들을 관리한다.synchronized를 시작할 때, 락이 없으면BLOCKED상태로 락 대기 집합에서 대기한다.
ReentrantLock도 마찬가지로 2단계 대기 상태로 동작한다.
다만, 다음의 차이가 있다.
- 독립적으로 구현된 락, 락 대기 큐,
condition(스레드 대기 공간)으로 구성- 락 획득 대기 시
WAITING상태로 대기condtion.await()호출 시 스레드 대기 공간에서 대기 (WAITING)- 다른 스레드가
condition.signal()호출 시 스레드 대기 공간 빠져나옴
Doug Lea
동시성 프로그래밍, 멀티스레딩, 병렬 컴퓨팅, 알고리즘 및 데이터 구조 등의 분야에서 많은 업적을 만들었다. 특히,
java.util.concurrent패키지의 주요 설계 및 구현을 주도했다.
java.util.concurrent패키지가 제공하는 동시성 라이브러리는 견고함 및 성능 최적화에 더불어 개발자가 쉽고 편리하게 동시성 문제를 다룰 수 있게 해준다.
이러한 기여는 자바 동시성 프로그래밍을 크게 발전시키고 현대 자바 프로그래밍의 핵심적 부분이 되었다.
이외에도Queue,Deque같은 자료구조에서 Doug Lea의 이름을 찾을 수 있다.
동기화와 원자적 연산 (CAS)
-
원자적 연산
- 해당 연산이 더 이상 나눌 수 없는 단위로 수행되는 것
-
멀티스레드 상황에서 다른 스레드의 간섭 없이 안전하게 처리되는 연산
- 원자적 연산은 멀티스레드 상황에서 전혀 문제가 없음
- 원자적 연산이 아닌 경우,
synchronized나Lock등을 사용해 안전한 임계 영역 만들어야 함
- e.g.
-
i = 1은 원자적 연산 O (대입 연산) -
i = i + 1,i++은 원자적 연산 X (3단계:i값 읽기, 더하기 연산, 대입 연산)
-
-
원자적 연산 제공 클래스
- 자바는 각 타입 별로 멀티스레드 상황에 안전하면서 다양한 값 증가, 감소 연산을 제공
-
AtomicInteger,AtomicLong,AtomicBoolean,AtomicXxx…
- 원자적 연산 구현 성능 비교
- 상황: 1000개 스레드를 사용해 값을 0에서 1000으로 증가시키기
- 성능 비교
-
BasicInteger(result: 950, 39ms)- CPU 캐시를 적극 사용하므로 가장 빠름
- 멀티스레드에서 사용 불가하지만 단일 스레드 사용 시 효율적
-
VolatileInteger(result: 961, 455ms)- CPU 캐시를 사용하지 않고 메인 메모리 사용해 느려짐
- 멀티스레드에서 사용 불가
-
SyncInteger(result: 1000, 625ms)-
멀티스레드 상황에서 안전 (
synchronized) -
MyAtomicInteger보다 느림
-
멀티스레드 상황에서 안전 (
-
MyAtomicInteger(result: 1000, 367ms)-
멀티스레드 상황에서 안전 (
incrementAndGet(), CAS) -
synchronized,Lock(ReentrantLock)보다 1.5~2배 빠름
-
멀티스레드 상황에서 안전 (
-
-
CAS 연산 (Compare-And-Swap, Compare-And-Set)
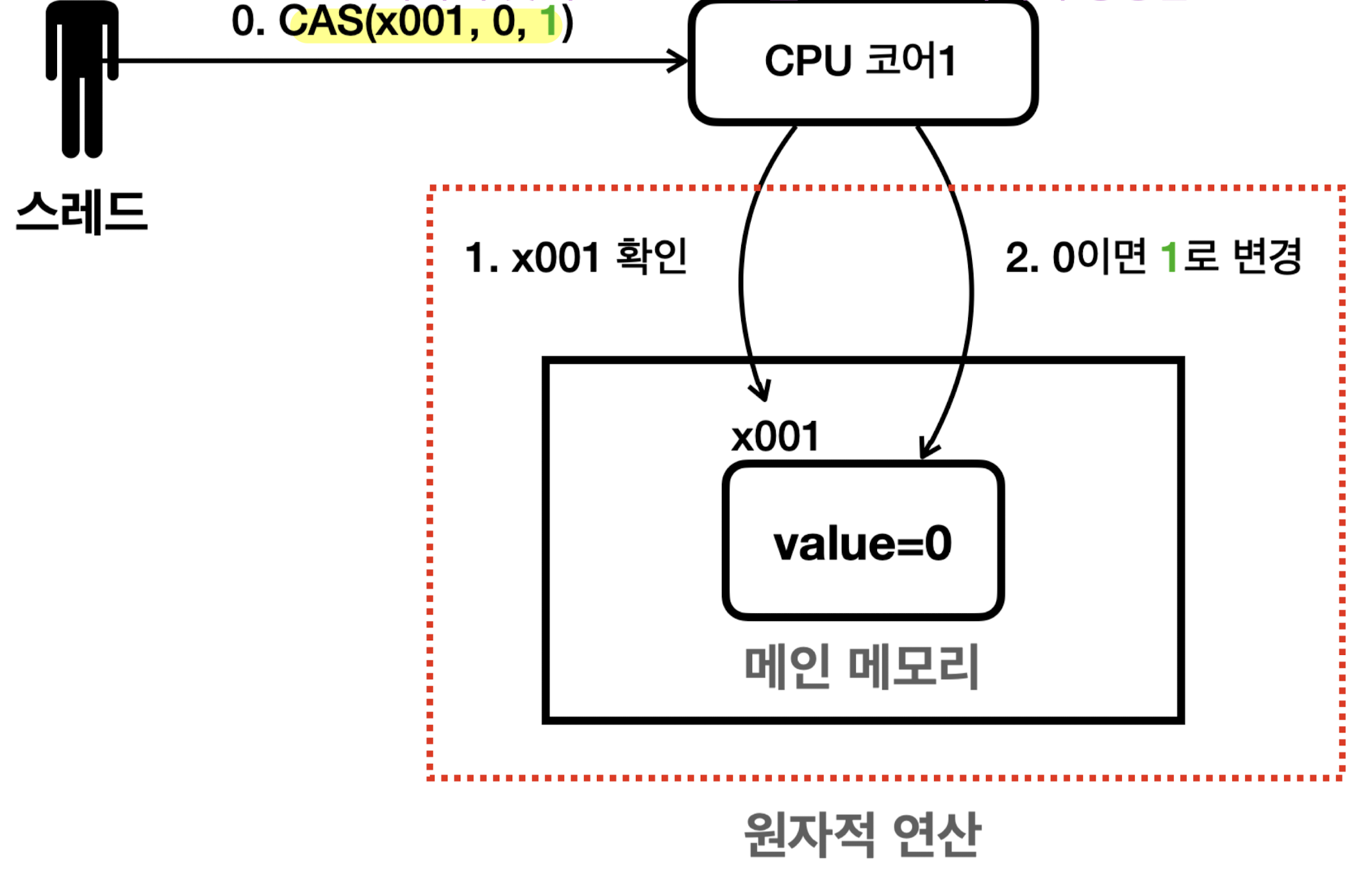
- 락을 걸지 않고 원자적인 연산 수행 (락 프리(lock-free) 기법)
-
CPU 하드웨어 차원에서 내리는 특별한 명령
- CPU는 잠깐 다른 스레드가 메모리에 write하는 것을 막음
- 너무 찰나의 시간이므로 락이라 부르진 않음 (성능에 큰 영향 X)
- 원자적이지 않은 두 과정을 묶어 하나의 원자적 명령으로 만듦 (중간에 다른 스레드 개입 X)
- 주 메모리에서 값 읽기
- 기대하는 값이 맞다면 읽은 값을 변경하기 (아니라면 변경 X)
-
대부분의 현대 CPU가 CAS 연산 명령어 제공
- JAVA가 CAS 연산 요청 시 운영체제는 현재 컴퓨터 CPU 종류 확인
(인텔, AMD, MAC…) - 그 후 그에 맞는 CAS 연산을 CPU 코어에 명령
- JAVA가 CAS 연산 요청 시 운영체제는 현재 컴퓨터 CPU 종류 확인
- 자바는
AtomicXxx클래스에서 CAS 연산 메서드 제공 (compareAndSet())- e.g.
compareAndSet(0, 1)- 주 메모리 현재 값이 0이라면 1로 변경하고
true반환 - 주 메모리 현재 값이 0이 아니라면 변경없이
false반환
- 주 메모리 현재 값이 0이라면 1로 변경하고
- e.g.
incrementAndGet()내부 구현 예시 (CAS 활용)private static int incrementAndGet(AtomicInteger atomicInteger) { int getValue; boolean result; do { getValue = atomicInteger.get(); log("getValue: " + getValue); result = atomicInteger.compareAndSet(getValue, getValue + 1); log("result: " + result); } while (!result); return getValue + 1; }- 스레드 충돌이 발생해도 CAS 연산이 성공할 때까지 반복 재시도
- 덕분에 락 없이 안전한 데이터 변경 가능
- e.g.
- CPU는 잠깐 다른 스레드가 메모리에 write하는 것을 막음
-
작은 단위의 일부 영역에 적용 가능 (락 완전히 대체 X)
- 락 기반 방식의 문제점 (
synchronized,Lock(ReentrantLock))- 락 기반 방식은 직관적이지만 무거움
- 스레드의 상태 변경으로 CPU 스케줄러에 들어갔다 나왔다 하는 무거운 과정 동반
- 락 획득 및 반납에 시간 소요
- 락 획득 및 반납하는 과정의 반복
- 락 기반 방식은 직관적이지만 무거움
- 락 기반 방식의 문제점 (
-
스핀 락(Spin-Lock) - CAS 활용 락 구현
public class SpinLock { private final AtomicBoolean lock = new AtomicBoolean(false); public void lock() { log("락 획득 시도"); while (!lock.compareAndSet(false, true)) { // 락을 획득할 때 까지 스핀 대기(바쁜 대기) 한다. log("락 획득 실패 - 스핀 대기"); } log("락 획득 완료"); } public void unlock() { lock.set(false); log("락 반납 완료"); } }-
스핀 락
- 락을 획득하기 위해 자원을 소모하면서 반복적으로 확인하는 락 메커니즘
- CAS를 사용해서 구현
- CAS는 단순한 연산 뿐만 아니라, 가벼운 락 구현에도 사용 가능
- 락 획득은 원자적이지 않은 임계 영역
-
- 락 사용 여부 확인
-
- 락의 값 변경
-
-
synchronized,Lock등으로 동기화할 수도 있지만, CAS를 사용하면 원자적 연산 가능
- 락 획득은 원자적이지 않은 임계 영역
- 장점
- 무거운 동기화 작업(락) 없이 아주 가벼운 락을 만들 수 있음
(RUNNABLE상태를 유지, 빠른 성능 동작)
- 무거운 동기화 작업(락) 없이 아주 가벼운 락을 만들 수 있음
- 단점
- 반복문으로 CPU 자원을 계속 사용하면서 락을 대기 (스핀 대기, 바쁜 대기)
- 사용 방향
-
아주 짧은 CPU 연산 수행 시에만 사용해야 효율적
- 나노 초 단위에서 사용해야 함
- e.g. 숫자 값 증가, 자료 구조 데이터 추가
-
I/O 작업 같이 오래 기다리는 작업에서는 최악
- CPU를 계속 사용하며 기다림
- e.g. DB 쿼리, 다른 서버 응답 기다리기
- 보통 I/O 작업은 0.X초 ~ X초까지 걸릴 수 있음 (최소 10ms 이상)
- 이 경우 일반적인 락을 사용해야 함
-
아주 짧은 CPU 연산 수행 시에만 사용해야 효율적
-
스핀 락
-
동기화 락 방식 VS 락 프리 방식(CAS 활용)
- 두 방식 모두 안정적인 데이터 변경 보장
- 동기화 락 방식
- 비관적 접근법 (pessimistic, 가정: “스레드 충돌이 반드시 일어날 것이다”)
- 항상 락 획득하고 데이터 접근
- 다른 스레드의 접근을 막음
- 스레드를 하나씩 순서대로 돌림
- 멀티스레드에서 순간적으로 싱글 스레드로 바뀜
- 장점
- 하나의 스레드만 리소스에 접근할 수 있으므로 충돌 발생 X
- 락을 대기하는 스레드는 CPU를 거의 사용 X
- 단점
- 락 획득을 위한 대기 시간이 길어질 수 있음
- 스레드 상태 변경으로 인한 컨텍스트 스위칭 오버헤드
- 락 프리 방식(CAS 활용)
- 낙관적 접근법 (optimistic, 가정: “대부분의 경우 충돌이 없을 것이다”)
- 락을 사용하지 않고 데이터에 바로 접근
- 어떤 스레드도 멈추지 않음 (10개 스레드면 모두 돌아감)
- 충돌이 발생하면 그 때 재시도
- 장점
- 충돌이 적은 환경에서 높은 성능 발휘
- 스레드가 블로킹되지 않아(
RUNNABLE) 병렬 처리가 더 효율적일 수 있음
- 단점
- 충돌이 빈번한 환경이라면 대기 시에도 CPU 자원 계속 소모해 비효율적
-
실무 사용 전략
-
기본은 동기화 락을 사용하고 특별한 경우에 CAS를 적용하여 최적화
- 임계 영역이 필요한 매우 간단한 CPU 연산에만 CAS 연산 사용이 효과적
- 간단한 CPU 연산은 매우 빨리 처리되므로 충돌이 자주 발생 X
-
나노 초 단위에서 간단한 연산에서 사용해야 함
- e.g. 숫자 값 증가, 자료 구조 데이터 추가
-
I/O 작업 혹은 몇 초씩 걸리는 복잡한 비즈니스 로직이라면 락 사용
- 충돌이 어마어마하게 날 것이므로
-
보통 I/O 작업은 0.X초 ~ X초까지 걸릴 수 있음 (최소 10ms 이상)
- e.g. DB 쿼리, 다른 서버 응답 기다리기
- 임계 영역이 필요한 매우 간단한 CPU 연산에만 CAS 연산 사용이 효과적
-
실무에서 대부분의 애플리케이션은 공유 자원 사용시, 생각보다 충돌하지 않을 가능성이 훨씬 높음
- e.g. 주문 수 실시간 카운트
-
특정 피크 시간에 주문이 100만건 들어오는 서비스
(1시간 100만건이면 우리나라 탑 서비스) - 1,000,000 / 60분 = 1분에 16,666건, 1초에 277건
- 1초 CPU 연산수 고려하면, 100만 건 중 충돌 나는 경우는 넉넉 잡아도 몇 십건 이하일 것
-
특정 피크 시간에 주문이 100만건 들어오는 서비스
-
주문 수 증가 같은 단순한 연산은
AtomicInteger같은 CAS가 더 나은 성능 보임
- e.g. 주문 수 실시간 카운트
-
기본은 동기화 락을 사용하고 특별한 경우에 CAS를 적용하여 최적화
CAS 연산과 라이브러리
복잡한 동시성 라이브러리들은 CAS 연산을 사용하지만, 개발자가 직접 사용하는 경우는 거의 없다.
CAS 연산을 사용하는 라이브러리를 잘 사용하는 정도면 충분하다. (AtomicInteger…)
스레드 충돌
두 스레드가 동시에 실행되면서 문제가 발생하는 상황을 말한다.
스레드 세이프
여러 스레드가 동시에 접근해도 괜찮은 경우를 말한다.
동시성 컬렉션
-
실무 전략
- 멀티스레드 환경에서 필요한 동시성 컬렉션을 잘 선택해 사용할 수 있으면 충분
- 단일 스레드에는 일반 컬렉션 사용, 멀티스레드에는 동시성 컬렉션 사용 (성능 트레이드 오프)
- 기존 컬렉션 프레임워크 (
java.util)는 스레드 세이프 X- 원자적 연산 제공 X -> 동시성 문제 및 버그 발생
- e.g.
ArrayList,LinkedList,HashSet,HashMap… - 다만, 성능 트레이드 오프로 인해 처음부터 모든 자료구조에 동기화를 해둘 수는 없음
- 단일 스레드 환경에서 불필요한 동기화는 성능 저하 발생
- e.g.
java.util.Vector는 현재 거의 사용 X
- 대안 1: 기존 컬렉션 프레임워크에
synchronized,Lock을 적용해 임계 영역 만들기- 컬렉션을 모두 복사해서 동기화 용으로 새로 구현해야하는데 비효율적
- 구현 변경 시 2곳에서 변경해야 함
- 컬렉션을 모두 복사해서 동기화 용으로 새로 구현해야하는데 비효율적
- 대안 2: 프록시가 대신 동기화 기능 처리 (프록시 패턴)
- 자료구조의 인터페이스를 구현한 프록시 클래스를 만들어
synchronized적용해target호출- 클라이언트 ->
SyncProxyList(인터페이스 구현 및synchronized적용) ->BasicList
- 클라이언트 ->
-
자바는 기본 컬렉션을 스레드 세이프하게 만드는 동기화 프록시 기능 제공
-
Collections를 통해 다양한synchronized동기화 메서드 지원synchronizedList()synchronizedCollection()synchronizedMap()synchronizedSet()synchronizedNavigableMap()synchronizedNavigableSet()synchronizedSortedMap()synchronizedSortedSet()
-
- 장점
-
기존 코드를 그대로 사용하면서
synchronized만 살짝 추가 가능 - 예를 들어,
SimpleList인터페이스를 구현한 모든 구현체에 적용 가능
-
기존 코드를 그대로 사용하면서
- 단점
-
대상 컬렉션 전체에 동기화가 이뤄져 잠금 범위가 넓어짐
- 동기화 필요 없는 메서드에도
synchronized적용해야 함
- 동기화 필요 없는 메서드에도
- 메서드 내 특정 부분에만 정교한 동기화 불가능 (최적화 불가)
-
대상 컬렉션 전체에 동기화가 이뤄져 잠금 범위가 넓어짐
- 자료구조의 인터페이스를 구현한 프록시 클래스를 만들어
- 대안 3: 자바는 스레드 세이프한 동시성 컬렉션을 제공 (
java.util.concurrent, 자바 1.5)-
유연하고 성능 최적화된 동기화 전략 사용
- 일부 메서드에 대해서만 동기화 적용
- 더욱 정교한 잠금을 통해 성능 최적화
- e.g.
synchronized,Lock(ReentrantLock),CAS, 분할 잠금 기술(segment lock)- 분할 잠금 기술
- e.g. 해시맵 -> 버킷마다 락을 분산
- 다른 버킷에 접근한 스레드는 락 획득을 위해 경쟁하지 않음
- 같은 버킷 접근해 충돌 시 락 혹은 CAS 기법 적용
- e.g. 해시맵 -> 버킷마다 락을 분산
- 분할 잠금 기술
- 종류 (
ConcurrentHashMap가장 많이 사용, 다른 것은 자주 사용 X)-
List-
CopyOnWriteArrayList:ArrayList의 대안
-
-
Set-
CopyOnWriteArraySet:HashSet의 대안 -
ConcurrentSkipListSet:TreeSet의 대안
(정렬된 순서 유지,Comparator사용 가능)
-
-
Map-
ConcurrentHashMap:HashMap의 대안 -
ConcurrentSkipListMap:TreeMap의 대안
(정렬된 순서 유지,Comparator사용 가능)
-
-
Queue-
ConcurrentLinkedQueue: 동시성 큐, 비 차단(non-blocking) 큐 -
BlockingQueue: 동시성 큐, 스레드 차단(blocking) 큐-
ArrayBlockingQueue- 크기가 고정된 블로킹 큐
- 공정(fair) 모드를 사용 가능 (사용 시 성능이 저하될 수 있음)
-
LinkedBlockingQueue- 크기가 무한하거나 고정된 블로킹 큐
-
PriorityBlockingQueue- 우선순위가 높은 요소를 먼저 처리하는 블로킹 큐
-
SynchronousQueue-
데이터를 저장하지 않는 블로킹 큐
- 생산자가 데이터를 추가하면 소비자가 그 데이터를 받을 때까지 대기
-
중간에 큐 없이 생산자, 소비자가 직접 거래
- 생산자-소비자 간의 직접적인 핸드오프(hand-off) 메커니즘을 제공
-
데이터를 저장하지 않는 블로킹 큐
-
DelayQueue- 지연된 요소를 처리하는 블로킹 큐 (지정된 지연 시간이 지난 후 소비)
- 일정 시간이 지난 후 작업을 처리해야 하는 스케줄링 작업에 사용
-
-
-
Deque-
ConcurrentLinkedDeque: 동시성 덱, 비 차단(non-blocking) 큐
-
-
LinkedHashSet,LinkedHashMap의 동시성 컬렉션은 제공 X- 필요하다면
Collections.synchronizedXxx()사용할 것
- 필요하다면
-
-
유연하고 성능 최적화된 동기화 전략 사용
스레드 풀 (Thread Pool)
-
스레드 직접 사용의 문제점
-
스레드 생성 비용으로 인한 성능 문제
- 스레드 생성 = 스레드 객체 생성 (
new Thread()) + 스레드 시작 (thread.start())-
new Thread는 단순히 자바 객체만 생성하는 것 -
thread.start()호출 시 실제 스레드 생성 (메모리 할당, 시스템 콜, 스케줄링…)
-
-
스레드 생성은 매우 무거운 작업 (스레드 하나는 보통 1MB 이상의 메모리 사용)
- 메모리 할당: 스레드 생성 시 호출 스택을 위한 메모리 공간을 할당해야 함
- 운영체제 자원 사용: 운영체제 커널 수준에서 시스템 콜을 통해 처리 (CPU와 메모리 소모)
- 운영체제 스케줄러 설정: 새 스레드를 관리하고 실행 순서 조정
-
스레드를 재사용하면 효율적일 것
- 스레드 생성은 단순 자바 객체 생성보다 비교할 수 없을 정도로 큰 작업
- 아주 가벼운 작업이라면, 작업 실행 시간보다 스레드 생성 시간이 더 오래 걸릴 수 있음
- 스레드를 재사용하면 처음 생성 후에는 생성 시간 없이 아주 빠르게 작업 수행 가능
- 스레드 생성 = 스레드 객체 생성 (
-
스레드 관리 문제
- 시스템이 버틸 수 있는 최대 스레드 수까지만 스레드를 생성할 수 있게 관리해야 함
- 서버의 CPU, 메모리 자원이 한정되어 있으므로, 스레드 무한 생성 불가
-
애플리케이션 종료 시에도 스레드 관리 필요
- 실행 중 스레드가 남은 작업을 모두 수행한 후 프로그램 종료하도록 관리
- 급하게 종료해야할 때는 인터럽트를 통해 바로 스레드를 종료하도록 관리
- 시스템이 버틸 수 있는 최대 스레드 수까지만 스레드를 생성할 수 있게 관리해야 함
-
Runnable인터페이스의 불편함-
반환 값이 없음
-
run()메서드에 반환 값 X -> 스레드 실행 결과를 직접 받을 수 없음 - e.g. 스레드 실행 결과를 멤버 변수에 넣어두고
join()으로 기다린 후 보관 값을 사용
-
-
예외 처리
- 체크 예외를 던질 수 없어 메서드 내부에서 반드시 처리해야 함
-
반환 값이 없음
-
스레드 생성 비용으로 인한 성능 문제
-
스레드 풀
- 스레드를 생성하고 관리하는 풀
- 단순히 컬렉션에 스레드를 보관하고 재사용하는 것이지만, 구현은 복잡
- 스레드 상태 관리 (
WAITING,RUNNABLE) - 생산자 소비자 문제 (스레드 풀의 스레드가 소비자)
-
Executor프레임워크 사용시 편리하게 사용 가능
- 스레드 상태 관리 (
- 작업 흐름
- 스레드를 필요한만큼 미리 생성
- 작업 요청이 오면 이미 만들어진 스레드를 조회해 작업 처리
- 작업 완료 후, 스레드를 재사용할 수 있도록 스레드 풀에 다시 반납
-
스레드 풀을 사용하면 스레드 생성 및 관리 문제 해결
- 재사용을 통해 스레드 생성 시간을 절약
- 필요한 만큼만 스레드를 만들고 관리
Executor 프레임워크 (스레드 사용 시 실무 권장)
- 자바 멀티스레드를 쉽고 편리하게 사용하도록 돕는 프레임워크
- 작업 실행 관리, 스레드 풀 관리, 스레드 상태 관리,
Runnable한계, 생산자 소비자 문제…
- 작업 실행 관리, 스레드 풀 관리, 스레드 상태 관리,
-
개발자가 직접 스레드 생성 및 관리하는 복잡함을 줄임
- Future 패턴(
Callable)은 마치 싱글 스레드 방식으로 개발하는 느낌- 스레드 생성이나
join()으로 제어하는 코드가 없음
- 스레드 생성이나
- 단순히
ExecutorService에 필요한 작업을 요청하고 결과를 받아서 쓰면 된다!
- Future 패턴(
- 주요 구성 요소 1
- 최상위
Executor인터페이스public interface Executor { void execute(Runnable command); } -
ExecutorService인터페이스 (주로 사용)public interface ExecutorService extends Executor, AutoCloseable { <T> Future<T> submit(Callable<T> task); <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException @Override default void close(){...} ... }- 주요 메서드로 작업 제출과 제어 기능 추가 제공
- 작업 단건 처리 -
submit(),Future.get() - 작업 컬렉션 처리 -
invokeAll(),invokeAny()- 여러 작업을 한 번에 요청하고 처리하는 메서드 제공
-
invokeAll()List<CallableTask> tasks = List.of(taskA, taskB, taskC); List<Future<Integer>> futures = es.invokeAll(tasks); //이 코드에서 메인스레드가 블로킹됨 for (Future<Integer> future : futures) { Integer value = future.get(); log("value = " + value); }-
모든
Callable작업이 완료될 때까지 기다림 - 타임아웃 설정도 가능
-
모든
-
invokeAny()List<CallableTask> tasks = List.of(taskA, taskB, taskC); Integer value = es.invokeAny(tasks); //이 코드에서 메인 스레드가 블로킹됨-
하나의
Callable작업이 완료될 때까지 기다리고, 가장 먼저 완료된 작업 결과 반환 - 완료되지 않은 나머지 작업은 인터럽트를 통해 취소함
- 타임아웃 설정도 가능
-
하나의
-
ThreadPoolExecutor(ExecutorService의 기본 구현체)
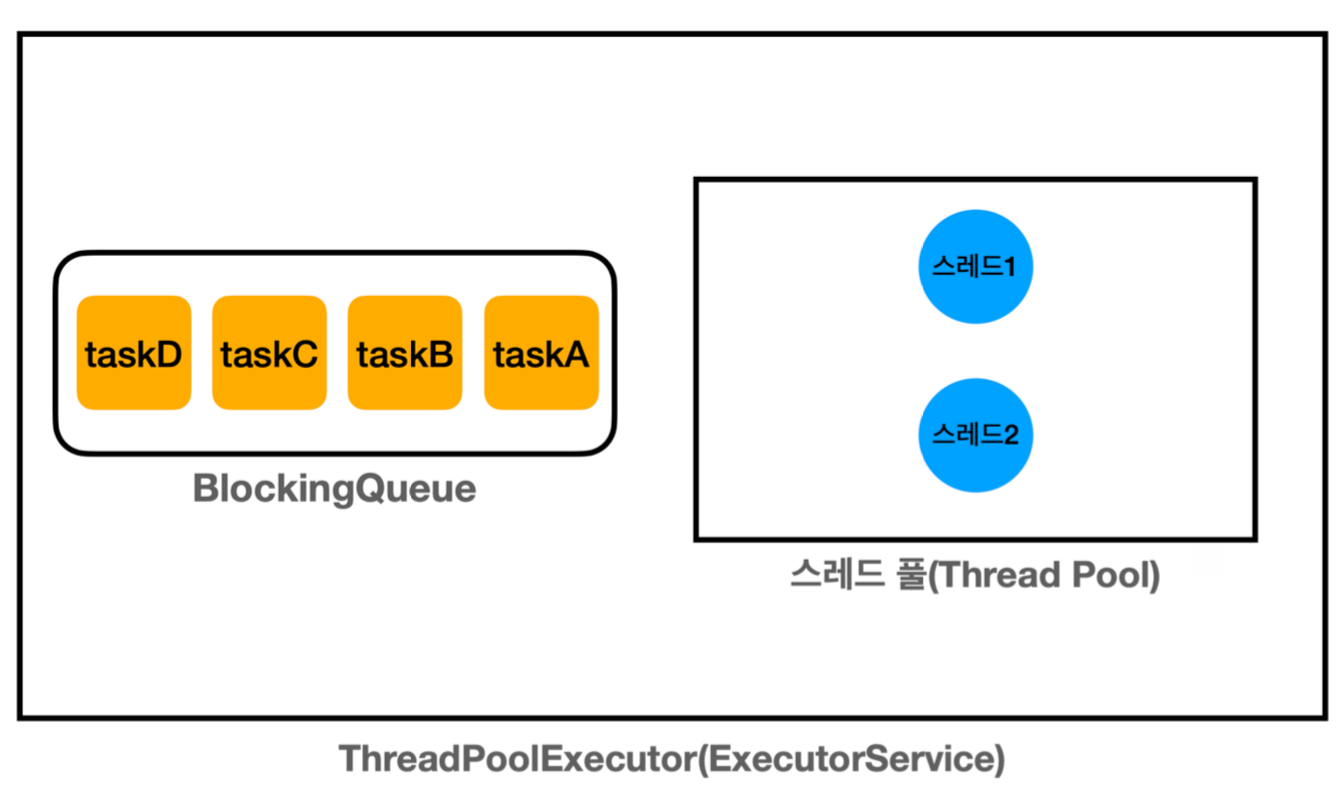
- 크게 스레드풀 + 블로킹 큐로 구성
- 기본 사용 예시
ExecutorService es = new ThreadPoolExecutor(2,2,0, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>()); //ExecutorService es = Executors.newFixedThreadPool(2); //편의 코드 es.execute(new RunnableTask("taskA")); es.execute(new RunnableTask("taskB")); es.close()-
생산자 (
main스레드)-
es.execute(작업)호출 시, 작업 인스턴스를 내부BlockingQueue에 보관
-
-
소비자 (스레드 풀에 있는 스레드)
- 소비자 중 하나가
BlockingQueue에 들어 있는 작업을 받아 처리
- 소비자 중 하나가
- 작업 과정
-
ThreadPoolExecutor생성 시점에는 스레드 풀에 스레드를 미리 만들지 않음 -
es.execute(작업)호출로 작업이 올 때마다corePoolSize까지 스레드 생성- 생산자 스레드는 작업만 전달하고 다음 코드 수행 (Non-Blocking)
-
corePoolSize까지 생성하고 나면, 이후 스레드 재사용- 작업이 완료되면 스레드 풀에 스레드 반납 (= 스레드 상태 변경)
- = 스레드가
WAITING상태로 스레드 풀에서 대기 - 반납된 스레드는 재사용
-
close()호출 시,ThreadPoolExecutor종료- 스레드 풀에 대기하는 스레드도 함께 제거
-
-
생산자 (
- 생성자 사용 속성
-
corePoolSize- 스레드 풀에서 관리되는 기본 스레드의 수
- 요청이 들어올 때마다 하나씩 생성
-
maximumPoolSize- 스레드 풀에서 관리되는 최대 스레드 수
- 요청이 너무 많거나 급한 경우 최대 수만큼 초과 스레드 생성해 사용
- 급한 경우: 큐까지 가득찼는데 새로운 작업 요청이 오는 경우
-
keepAliveTime,TimeUnit unit- 기본 스레드 수를 초과해서 만들어진 스레드가 생존할 수 있는 대기 시간
- 이 시간 동안 초과 스레드가 처리할 작업이 없다면 초과 스레드는 제거
-
BlockingQueue workQueue: 작업을 보관할 블로킹 큐 (생산자 소비자 문제 해결)
-
- 스레드 풀 상태 확인 메서드
getPoolSize(); //스레드 풀에서 관리되는 스레드의 숫자getActiveCount(); //작업을 수행하는 스레드의 숫자getQueue().size(); //큐에 대기중인 작업의 숫자getCompletedTaskCount(); //완료된 작업의 숫자
- 최상위
- 주요 구성 요소 2 -
Runnable사용의 불편함 해소-
Callable인터페이스 -java.util.concurrentpublic interface Callable<V> { V call() throws Exception; }-
ExecutorService의submit()메서드를 통해 작업으로 전달-
Runnable을 대신해 작업 정의 가능
-
-
call()메서드는 값 반환 가능 (제네릭V반환 타입) -
throws Exception예외가 선언되어 있어 체크 예외를 던질 수 있음
-
-
Future인터페이스public interface Future<V> { //아직 완료되지 않은 작업 취소하고 Future를 취소 상태로 변경 (CACELLED) //작업이 큐에 아직 있다면 취소 상태로 변경하는 것만으로도 작업이 수행되지 않음 //cancel(true): 작업이 실행 중이면 Thread.interrupt() 호출해 작업 중단 //cancel(false): 이미 실행 중인 작업은 중단하지 않음 boolean cancel(boolean mayInterruptIfRunning); boolean isCancelled(); //작업이 취소되었는지 여부 확인 boolean isDone(); //작업 완료 여부 확인 (작업완료: 정상완료, 취소, 예외종료) //작업 완료까지 대기(Blocking), 완료되면 결과 반환 V get() throws InterruptedException, ExecutionException; //get()과 동일, 시간 초과되면 예외 발생시킴 V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; enum State { RUNNING, SUCCESS, FAILED, CANCELLED } default State state() {} //Future의 상태 반환 }-
전달한 작업의 미래 결과를 받을 수 있는 객체
-
ExecutorService의submit()메서드 반환 타입
-
-
Future객체는 내부에 3가지를 보관-
작업(
Callable인스턴스) - 작업의 완료 여부 (완료 상태)
- 작업의 결과값 (
call()메서드가 반환할 결과)
-
작업(
- 필요성
- 전달한 작업의 결과는 즉시 받을 수 없음
-
Callable을submit()하면 미래 어떤 시점에 스레드풀의 스레드가 실행할 것 - 따라서, 언제 실행이 완료되어 결과를 반환할지 알 수 없음
-
-
Future반환 덕분에 요청 스레드는 블로킹 되지 않고 필요한 작업 수행 가능- 즉, 필요한 여러 작업을
ExecutorService에 계속 요청 가능 (동시작업 가능) - 모든 작업 요청이 끝난 후, 필요할 때
get()을 호출해서 최종 결과 받으면 됨
- 즉, 필요한 여러 작업을
- 반면에, 직접 결과값 반환 설계는 요청스레드가 블로킹됨
- 즉, 한 작업을 요청하면 블로킹되어 다른 작업을 이어 요청할 수 없음
- 전달한 작업의 결과는 즉시 받을 수 없음
-
FutureTask-
Future의 실제 구현체 -
Future인터페이스 뿐만 아니라Runnable인터페이스도 함께 구현 -
run()메서드가 작업의call()메서드를 호출하고 그 결과를 받아 처리
-
-
전달한 작업의 미래 결과를 받을 수 있는 객체
- 기본 사용 예시
public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService es = Executors.newFixedThreadPool(1); //편의 메서드 Future<Integer> future = es.submit(new MyCallable()); Integer result = future.get(); es.close(); } static class MyCallable implements Callable<Integer> { @Override public Integer call() { int value = new Random().nextInt(10); return value; } }- 요청 스레드가
submit(작업)호출하면 즉시Future객체 반환-
ExecutorService는Future객체(FutureTask)를 생성 - 생성된
Future를 블로킹 큐에 전달 - 나중에 스레드 풀의 스레드가 처리 - 요청 스레드에게
Future객체를 반환
-
-
스레드 풀의 스레드가 큐에
Future객체를 꺼내서 작업 수행-
FutureTask.run()호출 ->MyCallable.call()호출
-
- 요청 스레드는 본인이 필요할 때
future.get()을 호출한다. 이 때,-
Future가 완료 상태- 요청스레드는 대기 없이 바로 결과값 반환 받음
-
Future가 미완료 상태- 요청 스레드가 결과 받기 위해 블로킹 상태로 대기 (
RUNNABLE->WAITING) - 스레드 풀의 소비자 스레드는 작업이 완료되면
-
Future에 작업 결과값 담음 -
Future상태를 완료로 변경 -
요청 스레드를 깨움 (
WAITING->RUNNABLE)-
Future가 어떤 요청 스레드가 대기하는지 알고 있음
-
-
- 요청 스레드가 완료 상태
Future에서 결과를 반환 받음
- 요청 스레드가 결과 받기 위해 블로킹 상태로 대기 (
-
- 작업 완료 소비자 스레드는 스레드 풀로 반환 (
RUNNABLE->WAITING)
- 요청 스레드가
-
Future요청 예시-
바른 예시 - 수행 시간 2초
Future<Integer> future1 = es.submit(task1); // non-blocking Future<Integer> future2 = es.submit(task2); // non-blocking Integer sum1 = future1.get(); // blocking, 2초 대기 Integer sum2 = future2.get(); // blocking, 즉시 반환 - 잘못된 예시 1 - 수행 시간 4초
Future<Integer> future1 = es.submit(task1); // non-blocking Integer sum1 = future1.get(); // blocking, 2초 대기 Future<Integer> future2 = es.submit(task2); // non-blocking Integer sum2 = future2.get(); // blocking, 2초 대기 - 잘못된 예시 2 - 수행 시간 4초
Integer sum1 = es.submit(task1).get(); // get()에서 블로킹 Integer sum2 = es.submit(task2).get(); // get()에서 블로킹
-
바른 예시 - 수행 시간 2초
-
close()VSshutdown()
close()는 자바 19부터 지원되는 메서드다. 19 미만 버전을 사용한다면shutdown()을 호출해야 한다.
블로킹 메서드
어떤 스레드가 결과를 얻기 위해 대기하는 것을 블로킹(Blocking)이라고 한다. 이 때, 스레드의 상태는
BLOCKED,WAITING에 해당한다.
그리고Thread.join(),Future.get()같이 다른 작업이 완료될 때까지 호출한 스레드를 대기하게 하는 메서드를 블로킹 메서드라고 한다.
우아한 종료 (Graceful Shutdown) - ExecutorService
-
실무 전략
- 기본적으로 우아한 종료를 선택 (보통 60초로 우아한 종료 시간 지정)
- 시간안에 우아한 종료가 되지 않으면 다음으로 강제 종료 시도
- 우아한 종료 (Graceful Shutdown)
- 문제 없이 안정적으로 종료하는 방식
- e.g. 서버 재시작 시 새로운 요청은 막고, 이미 진행중인 요청은 모두 완료한 후 재시작하는게 이상적
-
ExecutorService종료 메서드- 서비스 종료 -> 풀의 스레드 자원 정리
-
shutdown()-
새로운 작업을 받지 않고, 이미 제출된 작업을 완료한 후 종료
- 이미 제출된 작업 = 처리중 작업 + 큐에 남아있는 작업
- 서비스 정상 종료 시도 (이상적)
- Non-Blocking 메서드
-
새로운 작업을 받지 않고, 이미 제출된 작업을 완료한 후 종료
-
List<Runnable> shutdownNow()- 인터럽트를 통해 실행 중인 작업을 중단하고, 대기 중인 작업을 반환하며 즉시 종료
- 새로운 요청 거절 + 실행중 작업 중단 + 큐에 남아있는 작업은 반환
-
FutureTask반환 (FutureTask는Runnable을 구현한 것)
- 서비스 강제 종료 시도
- Non-Blocking 메서드
- 인터럽트를 통해 실행 중인 작업을 중단하고, 대기 중인 작업을 반환하며 즉시 종료
-
close()- 자바 19부터 지원,
shutdown()과 동일 -
shutdown()호출 후, 하루를 기다려도 작업이 미완료면shutdownNow()호출 - 실용적인 방식이지만, 하루는 너무 김
- 호출 스레드에 인터럽트가 발생해도
shutdownNow()호출
- 자바 19부터 지원,
-
- 서비스 상태 확인
-
boolean isShutdown()- 서비스 종료 여부 확인
-
boolean isTerminated()-
shutdown(),shutdownNow()호출 후, 모든 작업이 완료되었는지 확인
-
-
- 작업 완료 대기
-
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException- 서비스 종료 시 모든 작업이 완료될 때까지 대기 (지정 시간까지만 대기)
-
shutdown()류의 서비스 종료와 함께 사용 - Blocking 메서드
-
- 서비스 종료 -> 풀의 스레드 자원 정리
- 실무 구현 (
shutdownAndAwaitTermination()) -ExecutorService공식 API 문서 제안 방식public static void main(String[] args) throws InterruptedException { ExecutorService es = Executors.newFixedThreadPool(2); es.execute(new RunnableTask("taskA")); es.execute(new RunnableTask("taskB")); es.execute(new RunnableTask("taskC")); es.execute(new RunnableTask("longTask", 100_000)); // 100초 대기 log("== shutdown 시작 =="); shutdownAndAwaitTermination(es); log("== shutdown 완료 =="); } static void shutdownAndAwaitTermination(ExecutorService es) { // non-blocking, 새로운 작업을 받지 않는다. // 처리 중이거나, 큐에 이미 대기중인 작업은 처리한다. 이후에 풀의 스레드를 종료한다. es.shutdown(); try { // 이미 대기중인 작업들을 모두 완료할 때 까지 10초 기다린다. log("서비스 정상 종료 시도"); if (!es.awaitTermination(10, TimeUnit.SECONDS)) { // 정상 종료가 너무 오래 걸리면... log("서비스 정상 종료 실패 -> 강제 종료 시도"); es.shutdownNow(); // 작업이 취소될 때 까지 대기한다. 인터럽트 이후 자원정리 등이 존재할 수 있음 if (!es.awaitTermination(10, TimeUnit.SECONDS)) { //이 구간이 되면 자바를 강제종료 해야함 //최악의 경우 스레드가 인터럽트를 받을 수 없는 코드 수행 중일 수 있음 //이런 스레드는 자바를 강제 종료해야 제거할 수 있음 //e.g. while(true) {...} //로그를 남겨두고 추후 문제 코드 수정 log("서비스가 종료되지 않았습니다."); } } } catch (InterruptedException ex) { // awaitTermination()으로 대기중인 현재 스레드가 인터럽트 될 수 있다. es.shutdownNow(); } }- 우아한 종료가 이상적이지만 서비스가 너무 늦게 종료되거나 종료되지 않는 문제 발생 가능
- 갑자기 많은 요청으로 큐에 대기중인 작업이 많아 작업 완료가 어려움
- 작업이 너무 오래 걸림
- 버그 발생으로 특정 작업이 안끝남
- 보통 60초까지 우아하게 종료하는 시간을 정하고, 넘어가면 작업 강제 종료 시도
- 우아한 종료가 이상적이지만 서비스가 너무 늦게 종료되거나 종료되지 않는 문제 발생 가능
Executor 프레임워크의 스레드 풀 관리
- 대량의 요청을 별도의 스레드에서 어떻게 처리해야하는지에 대한 기본기
-
스레드 풀 관리 사이클
-
corePoolSize크기까지는 작업 요청이 올 때마다 스레드를 생성하고 바로 작업 실행 -
corePoolSize를 초과하면 큐에 작업을 넣음 -
큐를 초과하면
maximumPoolSize크기까지만 요청이 올 때마다 초과 스레드를 생성하고 작업 실행 -
maximumPoolSize를 초과하면 요청이 거절되고 예외 발생 (RejectedExecutionException)- 즉, 큐도 가득차고 풀 최대 생성 가능한 스레드 수도 가득 차서 작업을 받을 수 없음
-
초과스레드는 지정 시간까지 작업 없이 대기하면 제거됨
- 긴급한 작업들이 끝난 것
-
shutdown()진행 시 풀의 스레드가 모두 제거됨
-
- 예시 코드
public class PoolSizeMain { public static void main(String[] args) throws InterruptedException { BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2); ExecutorService es = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, workQueue); printState(es); es.execute(new RunnableTask("task1")); printState(es, "task1"); es.execute(new RunnableTask("task2")); printState(es, "task2"); es.execute(new RunnableTask("task3")); printState(es, "task3"); es.execute(new RunnableTask("task4")); printState(es, "task4"); es.execute(new RunnableTask("task5")); printState(es, "task5"); es.execute(new RunnableTask("task6")); printState(es, "task6"); try { es.execute(new RunnableTask("task7")); } catch (RejectedExecutionException e) { log("task7 실행 거절 예외 발생: " + e); } sleep(3000); log("== 작업 수행 완료 =="); printState(es); sleep(3000); log("== maximumPoolSize 대기 시간 초과 =="); printState(es); es.close(); log("== shutdown 완료 =="); printState(es); } } //실행 결과 11:36:23.260 [main] [pool=0, active=0, queuedTasks=0, completedTasks=0] 11:36:23.263 [pool-1-thread-1] task1 시작 11:36:23.267 [main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0] 11:36:23.267 [main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0] 11:36:23.267 [pool-1-thread-2] task2 시작 11:36:23.267 [main] task3 -> [pool=2, active=2, queuedTasks=1, completedTasks=0] 11:36:23.268 [main] task4 -> [pool=2, active=2, queuedTasks=2, completedTasks=0] 11:36:23.268 [main] task5 -> [pool=3, active=3, queuedTasks=2, completedTasks=0] 11:36:23.268 [pool-1-thread-3] task5 시작 11:36:23.268 [main] task6 -> [pool=4, active=4, queuedTasks=2, completedTasks=0] 11:36:23.268 [pool-1-thread-4] task6 시작 11:36:23.268 [main] task7 실행 거절 예외 발생: java.util.concurrent.RejectedExecutionException: Task thread.executor.RunnableTask@3abbfa04 rejected from java.util.concurrent.ThreadPoolExecutor@7f690630[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0] 11:36:24.268 [pool-1-thread-1] task1 완료 11:36:24.268 [pool-1-thread-1] task3 시작 11:36:24.269 [pool-1-thread-3] task5 완료 11:36:24.269 [pool-1-thread-3] task4 시작 11:36:24.269 [pool-1-thread-2] task2 완료 11:36:24.269 [pool-1-thread-4] task6 완료 11:36:25.273 [pool-1-thread-1] task3 완료 11:36:25.273 [pool-1-thread-3] task4 완료 11:36:26.273 [main] ==작업수행완료== 11:36:26.273 [main] [pool=4, active=0, queuedTasks=0, completedTasks=6] 11:36:29.276 [main] == maximumPoolSize 대기 시간 초과 == 11:36:29.277 [main] [pool=2, active=0, queuedTasks=0, completedTasks=6] 11:36:29.278 [main] == shutdown 완료 == 11:36:29.278 [main] [pool=0, active=0, queuedTasks=0, completedTasks=6] - 스레드 미리 생성하기
- 서버는 고객의 첫 요청을 받기 전에 스레드 풀에 스레드를 미리 생성해두길 권장
- 처음 요청시 스레드 생성시간을 줄여 응답시간 빨라짐
- 처음 서버 올릴 때 CPU가 치고 올라오므로 미리 스레드 생성해두는게 좋음
-
ThreadPoolExecutor.prestartAllCoreThreads()- 기본 스레드 미리 생성
-
ExecutorService는 해당 메서드 제공 X
- 서버는 고객의 첫 요청을 받기 전에 스레드 풀에 스레드를 미리 생성해두길 권장
-
스레드 풀 관리 전략
-
실무 전략 선택 - 개발자의 시간 아끼기
-
일반적인 상황이라면 고정 스레드 풀 전략이나 캐시 스레드 풀 전략 선택으로 충분
- 한 번에 처리할 수 있는 수를 제한해 안정적으로 처리 - 고정 풀 전략
- 돈이 많다면 풀의 수를 많이 늘리는 전략도 가능 (안정 + 사용자 요청 빠르게 대응)
- 사용자 요청에 빠르게 대응 - 캐시 스레드 풀 전략
- 한 번에 처리할 수 있는 수를 제한해 안정적으로 처리 - 고정 풀 전략
- 일반 상황을 벗어날 정도로 서비스가 잘 운영되면, 그 때 최적화 시도 (사용자 정의 풀 전략)
- 각 전략의 특징
- 고정 스레드 풀 전략: 트래픽이 일정하고, 시스템 안전성이 가장 중요한 서비스
- 캐시 스레드 풀 전략: 일반적인 성장하는 서비스
- 사용자 정의 풀 전략: 다양한 상황에 대응
-
일반적인 상황이라면 고정 스레드 풀 전략이나 캐시 스레드 풀 전략 선택으로 충분
- 단일 스레드 풀 전략 (
newSingleThreadPool())- 스레드 풀에 기본 스레드 1개만 사용
- 큐 사이즈 제한 X (
LinkedBlockingQueue) - 간단한 사용 및 테스트 용도
- 고정 스레드 풀 전략 (
newFixedThreadPool(nThreads))- 스레드 풀에
nThreads만큼의 기본 스레드 생성 (초과 스레드는 생성 X) - 큐 사이즈 제한 X (
LinkedBlockingQueue) - 스레드 수가 고정되어 있어 CPU, 메모리 리소스가 어느정도 예측 가능한 안정적인 방식
- 장점
- 일반적인 상황에서 가장 안정적으로 서비스를 운영할 수 있음
- 단점
-
서버 자원(CPU, 메모리)이 여유가 있음에도 사용자가 증가하면 응답이 느려짐
- 실행되는 스레드 수가 고정되어 있어 요청 처리 시간 보다 큐에 쌓이는 시간이 빠름
- e.g. 큐에 10000건 쌓여 있고, 고정 스레드 수가 10, 작업 처리 시간 1초
- 모든 작업 처리 시 1000초 걸림
- 서비스 초기 사용자 적을 때는 문제 없지만 사용자가 많아지면 문제
- 점진적 사용자 확대 시 서비스 응답이 점점 느려짐
- 갑작스런 요청 증가 시 고객이 응답을 받지 못함
- 실행되는 스레드 수가 고정되어 있어 요청 처리 시간 보다 큐에 쌓이는 시간이 빠름
-
서버 자원(CPU, 메모리)이 여유가 있음에도 사용자가 증가하면 응답이 느려짐
- 스레드 풀에
- 캐시 스레드 풀 전략 (
newCachedThreadPool())- 기본 스레드를 사용하지 않고 60초 생존 주기를 가진 초과 스레드만 사용 (스레드 수 제한 X)
- corePoolSize가 0, SynchronousQueue는 작업 넣기 불가, maxPoolSize는 무한
-
큐에 작업을 저장하지 않음 (
SynchronousQueue, 저장 공간이 0인 특별한 큐)-
생산자의 요청을스레드 풀의 소비자 스레드가 직접 받아서 바로 처리
- 모든 작업이 대기 없이 작업 수 만큼 초과 스레드가 생기면서 바로 실행
- 중간에 버퍼를 두지 않는 스레드 간 직거래
- 빠른 처리 O
-
생산자의 요청을스레드 풀의 소비자 스레드가 직접 받아서 바로 처리
- 장점
- 서버 자원을 최대로 사용할 수 있어 매우 빠름 (초과 스레드 수 제한 X)
- 작업 요청 수에 따라 스레드가 증감되어 유연한 처리 (생존 주기 내 스레드 적절히 재사용)
-
점진적 사용자 확대 시 크게 문제 되지 않음
- 사용자 증가 -> 스레드 사용량 증가 -> CPU, 메모리 사용량 증가
- 서버 자원에 한계를 고려해 적절한 시점에 시스템 증설 필요
- 단점
-
갑작스런 요청 증가 시 서버 자원의 임계점을 넘는 순간 시스템이 다운될 수 있음
- 사용자 급증 -> 스레드 수 급증 -> CPU, 메모리 사용량 급증 -> 시스템 전체 느려짐
-
너무 많은 스레드에 시스템이 잠식되어 장애 발생
- 수 천개 스레드가 처리하는 속도 보다 더 많은 작업 들어옴
- 수 천개 스레드로 메모리도 가득참 (1개 스레드는 1MB 이상)
-
갑작스런 요청 증가 시 서버 자원의 임계점을 넘는 순간 시스템이 다운될 수 있음
- 기본 스레드를 사용하지 않고 60초 생존 주기를 가진 초과 스레드만 사용 (스레드 수 제한 X)
-
사용자 정의 스레드 풀 관리 전략
- 목표
- 점진적인 사용자 확대 상황 처리
- 갑작스런 요청 증가 상황 처리
- 어떤 경우도 서버가 다운되어서는 안됨
- 전략
- 일반: 고정 크기 스레드로 서비스를 안정적으로 운영 (CPU, 메모리 예측 가능)
- 긴급: 사용자 요청 급증 시 초과 스레드 추가 투입
- 긴급 상황 때는 스레드 수가 늘어나므로 작업 처리 속도도 더 빨라짐
-
시스템 자원을 고려해 적정한
maxPoolSize를 설정해야함
- 거절: 긴급 대응도 어렵다면 추가되는 사용자 요청 거절
- 즉, 큐가 가득차고 초과 스레드도 모두 사용 중인데 작업이 더 들어오는 상황
- = 처리 속도가 높아졌음에도 작업이 빠르게 소모되지 않는 상황
- = 시스템이 감당하기 어려운 많은 요청이 들어오고 있는 것
- 구현 예시
-
ExecutorService es = new ThreadPoolExecutor(100, 200, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000));- 100개 기본 스레드
- 긴급 대응 초과 스레드 100개(60초 생존)
- 1000개 작업 가능한 큐
- 하나의 작업은 1초 걸림
-
일반 상황:
static final int TASK_SIZE = 1100;- 100개 기본 스레드로 처리
- 작업 처리 시간: 1100 / 100 = 11초
-
긴급 상황:
static final int TASK_SIZE = 1200;- 100개 기본 스레드 + 100개 초과 스레드로 처리
- 작업 처리 시간: 1200 / 200 = 6초
- 긴급 투입 스레드 덕분에 풀의 스레드 수가 2배가 되어 작업 2배 빠르게 처리
-
거절 상황:
static final int TASK_SIZE = 1201;- 100개 기본 스레드 + 100개 초과 스레드로 처리
- 1201번째 작업은 거절 (예외 발생)
-
-
실무 주의사항
-
new ThreadPoolExecutor(100, 200, 60, TimeUnit.SECONDS, new LinkedBlockingQueue());- 큐 사이즈: 무한대
-
큐 사이즈를 무한대로 해서는 절대로 안됨!
- 큐가 가득차야 긴급 상황으로 인지 가능
- 큐 사이즈가 무한대면 큐가 가득찰 수 없음
- 기본 스레드 100개만으로 무한대 작업을 처리하는 문제 발생
-
- 목표
-
실무 전략 선택 - 개발자의 시간 아끼기
가장 좋은 최적화는 최적화하지 않는 것
예측 불가능한 먼 미래보다는 현재 상황에 맞는 최적화가 필요하다. 발생하지 않을 일에 최적화 시간을 쏟다가 버리는 경우가 많기 때문이다.
제일 비싼 자원은 개발자의 인건비다. 최적화에 쏟는 시간보다 간단히 서버 증설하는게 저렴할 수도 있다.따라서, 중요한 것은 모니터링 환경을 잘 구축하는 것이다.
성장하는 서비스를 포함해 대부분의 서비스는 트래픽이 어느정도 예측 가능하다.
서비스 운영이 정말 잘되어 특출나게 유의미한 트래픽 상승이 예상된다면 그 때 최적화하자.다만, 어떤 경우에도 절대 시스템이 다운되지 않도록 해야한다!
Executor 거절 정책
-
ThreadPoolExecutor는 소비자가 처리할 수 없을 정도로 생산 요청이 가득 차면 후속 작업을 거절함 -
ThreadPoolExecutor는 작업을 거절하는 다양한 정책 제공- 설정 방법
-
ThreadPoolExecutor생성자 마지막에 원하는 정책을 인자로 전달-
RejectedExecutionHandler구현체 전달 -
ThreadPoolExecutor는 거절 상황이 발생 시rejectedExecution()호출
-
- e.g.
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS, new SynchronousQueue<>(), ThreadPoolExecutor.AbortPolicy());
-
- 정책 종류 (
RejectedExecutionHandler구현체)-
AbortPolicy(Default)- 추가 작업 거절시
RejectedExecutionException예외 발생시킴 - 개발자는 예외를 잡아서 작업을 포기하거나, 사용자에게 알리거나, 다시 시도 등 구현 가능
- 추가 작업 거절시
-
DiscardPolicy- 추가 작업을 조용히 버림
-
CallerRunsPolicy- 거절하지 않고 추가 작업을 제출하는 스레드가 대신해서 작업을 실행
- = 소비자 스레드가 없어서 생산자 스레드가 작업을 대신 처리
- 해당 생산자 스레드의 속도가 저하될 수 있음 (Blocking)
- = 작업 생산 속도가 너무 빠를 때, 작업의 생산 속도를 늦출 수 있음
- 거절하지 않고 추가 작업을 제출하는 스레드가 대신해서 작업을 실행
- 사용자 정의
- 개발자가 직접 정의한 거절 정책 사용 가능 (
RejectedExecutionHandler구현) - e.g.
static class MyRejectedExecutionHandler implements RejectedExecutionHandler { static AtomicInteger count = new AtomicInteger(0); @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { int i = count.incrementAndGet(); log("[경고] 거절된 누적 작업 수: " + i); } }
- 개발자가 직접 정의한 거절 정책 사용 가능 (
-
- 설정 방법