
요청과 응답 관련 유의 사항
-
요청 및 응답은 API 스펙에 맞추어 별도의 DTO로 전달하자 (엔터티 노출 X)
- 엔터티를 요청과 응답에 사용하면 프레젠테이션 계층과 엔터티가 결합되어 오염됨 (
@NotEmpty등…)- e.g.
@RequestBody CreateMemberRequest request
- e.g.
- 엔터티를 요청과 응답에 사용하면 프레젠테이션 계층과 엔터티가 결합되어 오염됨 (
-
롬복은 DTO에 적극적으로 사용하자 (Entity에는
getter정도 이외에는 사용 X) -
CQS 개발 스타일 적용하면 유지보수성이 크게 향상됨!
-
Update 메서드는 반환없이 끝내거나 ID 값 정도만 반환
- Update가 엔터티 객체를 반환하면, 업데이트하면서 조회하는 꼴
- Update 후 조회가 필요하다면, PK로 하나 조회하자
- 특별히 트래픽 많은 API가 아니면 큰 이슈 X
- e.g.
memberService.update(id, request.getName());Member findMember = memberService.findOne(id);
-
Update 메서드는 반환없이 끝내거나 ID 값 정도만 반환
-
API 응답은 처음부터
Object로 반환하자 (ArrayX)- 추후 Count를 넣어달라는 요청 등으로 언제든 요구사항이 변할 수 있음 (확장성을 위해)
지연로딩과 조회 성능 최적화
-
항상 지연로딩을 기본으로 하고, 성능 최적화가 필요한 경우 페치 조인 사용하자!
- 즉시 로딩은 연관관계가 필요 없는 경우에도 데이터를 항상 조회해 성능 문제 유발
- JPQL 실행 후 응답을 받을 때 연관 관계에 즉시 로딩이 있으면,
영속성 컨텍스트에서 지연 로딩처럼 하나하나 단건 쿼리 날려 다 조회해 가져옴 (N + 1)
- 참고: 지연로딩은 N + 1을 만들지만, 영속성 컨텍스트에서 조회하므로 운좋게 이미 조회된 객체는 쿼리 생략
-
DTO 직접 조회 방식은 후순위 선택지
- DTO 직접 조회는 페치 조인 없이도 한 번에 쿼리가 나감
- 장점
- SELECT 절에 원하는 데이터 직접 선택 -> 애플리케이션 네트워크 용량 최적화 (생각보다 미비)
- 최근 네트워크 대역폭이 매우 좋음
-
대부분 성능 문제는
join에서 걸리거나where문이 인덱스를 잘 안탈 때 생김 - SELECT 절이 문제가 될 때는 하필 필드 데이터 사이즈가 정말로 컸을 때
- e.g. 필드가 10~30개 정도 되면 트래픽이 정말 많은 API는 영향 받을 수도 있음
- SELECT 절에 원하는 데이터 직접 선택 -> 애플리케이션 네트워크 용량 최적화 (생각보다 미비)
- 단점
-
리포지토리가 API(화면)을 의존 -> API 스펙이 바뀌면 수정
-> 물리적 계층은 나뉘었지만 논리적 계층은 깨져있음 - 리포지토리 재사용성 감소
-
리포지토리가 API(화면)을 의존 -> API 스펙이 바뀌면 수정
컬렉션 조회 최적화
- 컬렉션 조회시 페치 조인의 한계
- 컬렉션 페치 조인은 페이징 불가능
- 결과값은 올바르게 페이징해줄 수도 있으나, 메모리에서 진행되므로 메모리 터질 가능성 매우 큼
- 1 : N : M 같은 둘 이상의 연쇄적 컬렉션 패치 조인은 사용해서는 안됨
- JPA 입장에서 어떤 엔터티를 기준으로 정리할지 모르게 될 수 있음
- 컬렉션 페치 조인은 페이징 불가능
-
페이징 + 컬렉션 조회 전략 (
default_batch_fetch_size)- 전략
- ToOne(OneToOne, ManyToOne) 관계를 모두 페치 조인하기 (=쿼리수 최대한 줄이기)
-
컬렉션은 아래 최적화 적용하고 지연 로딩으로 조회 (=N + 1 문제 완화)
-
hibernate.default_batch_fetch_size: 글로벌 설정 (이것만으로도 충분) -
@BatchSize: 개별 최적화 - -> 컬렉션 및 프록시 객체를 설정한 size만큼 한꺼번에 IN 쿼리로 조회
-
- 장점
- 페이징 가능
- 페치 조인 방식 보다 쿼리 호출 수는 약간 증가하지만, DB 데이터 전송량이 감소
-
적절한 배치 사이즈
- 전략
- WAS, DB가 버틸 수 있으면 1000으로 설정
- WAS, DB가 걱정된다면 100으로 설정하고 점점 늘리기
- 애매하면 500으로 설정 (100~500 두면 큰 문제 없이 사용 가능)
-
DB 및 애플리케이션이 순간 부하를 어느정도로 견딜 수 있는지로 결정
- DB에 따라 IN 절 파라미터를 1000으로 제한하는 경우도 있음
- 1000으로 잡으면 DB 및 WAS의 순간 부하 증가 (CPU 및 리소스)
- 100이면 시간은 더 걸리겠지만 순간 부하는 덜할 것
- WAS 메모리 사용량은 100이든 1000이든 동일
- 전략
- 전략
distinct하이버네이트 6 버전 부터는 컬렉션 조회 시
distinct없이도 애플리케이션 단에서 자동으로 중복을 거른다.6 이전에는 2가지 기능을 함께 수행했다.
- SQL에
distinct추가- 같은 엔터티가 조회되면 애플리케이션 단에서 중복 거르기
네트워크 호출 횟수와 데이터 전송량
네트워크 호출 횟수와 데이터 전송량 사이에는 성능 트레이드 오프가 존재한다.
모두 조인해서 가져오면, 한 번의 호출로 가져오지만 데이터 양이 많을 경우 성능이 저하된다.
여러 쿼리로 나눠 가져오면, 호출 수는 많아지지만 각각 최적화된 데이터 양으로 가져올 수 있어 더 나은 성능을 보일 수도 있다.
예를 들어, 한 쿼리로 1000개 데이터를 퍼올리는 상황이라면 여러 쿼리로 나누는게 나을 수 있다.
쿼리 방식 권장 선택 순서
- 기본: 엔터티 조회 후 DTO 변환 방식 (대부분의 성능 이슈 해결 가능)
-
ToOne 관계 조회
- 페치 조인으로 쿼리 수 최적화
-
OneToMany 관계 조회 (컬렉션 조회)
-
페이징 필요 O
- ToOne인 부분은 최대한 페치 조인해서 가져옴
- 컬렉션은
hibernate.default_batch_fetch_size,@BatchSize로
최적화 후 지연로딩
-
페이징 필요 X
- 페치 조인 최적화
- e.g.
- 페이징이 없는 엑셀 다운로드 같은 기능은 페치 조인으로 조회
- 다만, 용량이 너무 많으면 앞의
default_batch_fetch_size방법 이용
-
페이징 필요 O
-
ToOne 관계 조회
- 차선책: DTO 직접 조회 방법 사용
-
ToOne 관계 조회
- 단순 조인으로 한 번에 쿼리
-
OneToMany 관계 조회 (컬렉션 조회)
- 단건
- One을 조회 -> One의 식별자로 Many를 조회 -> 서로 매핑
- 다건
-
분할 쿼리 (with IN 쿼리) - 권장
- One을 조회 -> 해당 One의 식별자를 모아 Many를 IN 쿼리 -> Map 활용해 매핑
- 플랫 쿼리
- 한방 쿼리로 가져온 후 매핑 (페이징이 불가해 실무 비현실성, 성능 차이도 미비)
-
분할 쿼리 (with IN 쿼리) - 권장
- 단건
- 유지보수 방법
-
복잡한 통계 API 용으로
QueryService,QueryRepository파서 DTO 직접 조회 사용 - 일반 리포지토리는 기본 엔터티 조회용으로 사용
- -> 둘 구분으로 유지보수성 향상
-
복잡한 통계 API 용으로
-
ToOne 관계 조회
- 최후의 방법: JPA 제공 네이티브 SQL 혹은 스프링 JDBC Template으로 직접 SQL 사용
- 이런 경우가 거의 없지만 DB 네이티브한 복잡한 기능 필요시 사용
- 참고
-
엔터티 조회 방식(페치 조인, BatchSize)으로 해결이 안되는 수준의 상황
- 서비스 트래픽이 정말 많은 상황이라 DTO 조회 방식으로도 해결이 안 될 가능성이 높음
- 캐시(레디스, 로컬 메모리 캐시) 사용이나 다른 방식으로 해결해야 함
-
엔터티 조회 방식은 코드 수정 거의 없이 옵션 변경만으로 성능 최적화하는
반면, DTO 직접 조회 방식은 성능 최적화 시 코드 변경이 많음- 개발자는 성능 최적화와 코드 복잡도 사이에서 줄타기를 해야 한다.
-
엔터티 조회 방식(페치 조인, BatchSize)으로 해결이 안되는 수준의 상황
OSIV (Open Session In View) 전략
- 유래
- Open Session In View: 하이버네이트
- Open EntityManager In View: JPA
-
관례상 OSIV라고 함
- 하이버네이트가 JPA보다 먼저 나왔기 때문에, 이름 차이 발생
- 과거 하이버네이트 Session = JPA EntityManager
-
사용 전략
- 고객 서비스의 실시간 API는 OSIV 끄기
- ADMIN 처럼 커넥션을 많이 사용하지 않는 곳에서는 OSIV 켜기
- ADMIN은 해봤자 20~30명이 쓰는 서비스
- 한 프로젝트여도 멀티 모듈 사용해 분리 -> 고객 서비스와 ADMIN 서비스는 배포 군이 다름
-
spring.jpa.open-in-view = true(기본값)
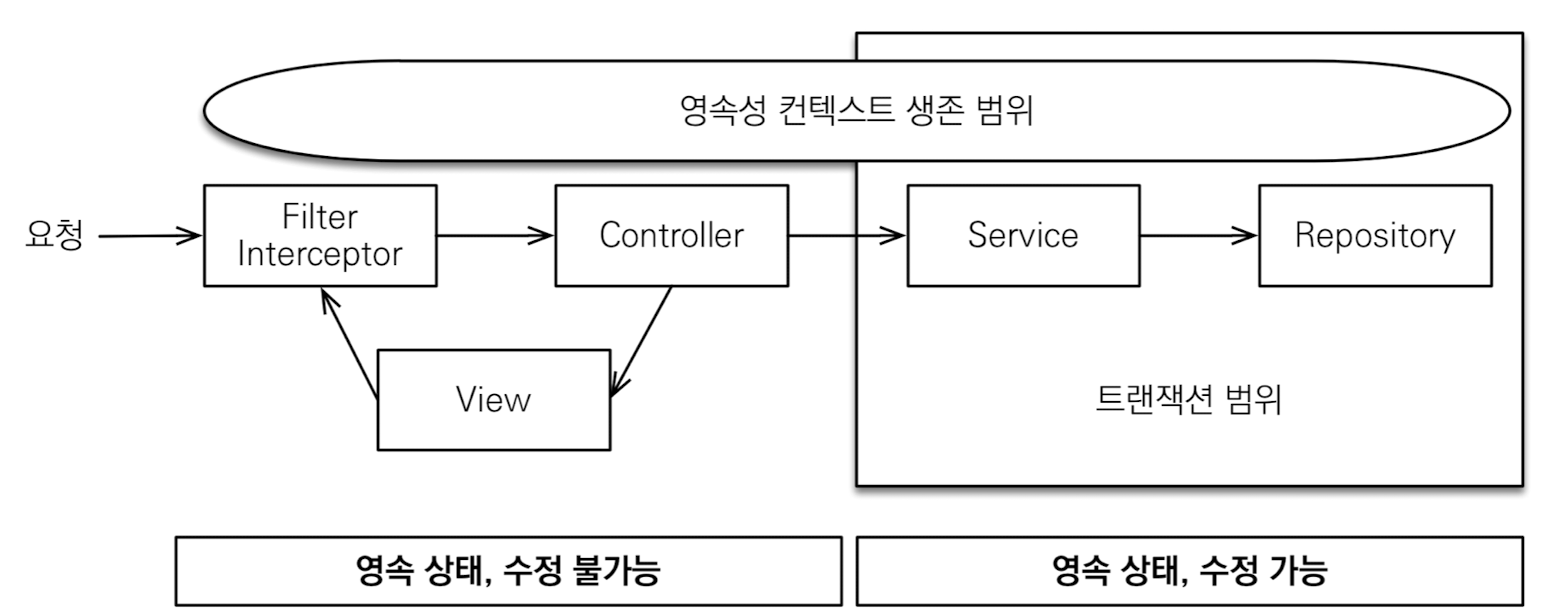
-
최초 DB 커넥션 시작 시점부터 API 응답 종료까지 영속성 컨텍스트와 DB 커넥션을 유지
- 과정
- JPA는
@Transactional로 트랜잭션 시작시점에 커넥션을 가져옴 - API 혹은 뷰 템플릿 렌더링이 끝나고 응답이 완전히 나가면
- 물고 있던 커넥션 반환
- 영속성 컨텍스트 종료
- JPA는
- 과정
- 장점
- API 컨트롤러 & View Template에서도 지연 로딩을 가능하게 함
- 영속성 컨텍스트는 기본적으로 DB 커넥션 유지
- API 컨트롤러 & View Template에서도 지연 로딩을 가능하게 함
- 단점 (치명적)
- 너무 오랜시간 동안 DB 커넥션 리소스를 사용 (e.g. 컨트롤러에서 외부 API 호출)
- 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자라 장애 유발
- 일반적인 애플리케이션이라면 트랜잭션 종료 시 커넥션도 반환하는게 자연스러움
-
최초 DB 커넥션 시작 시점부터 API 응답 종료까지 영속성 컨텍스트와 DB 커넥션을 유지
-
spring.jpa.open-in-view = false
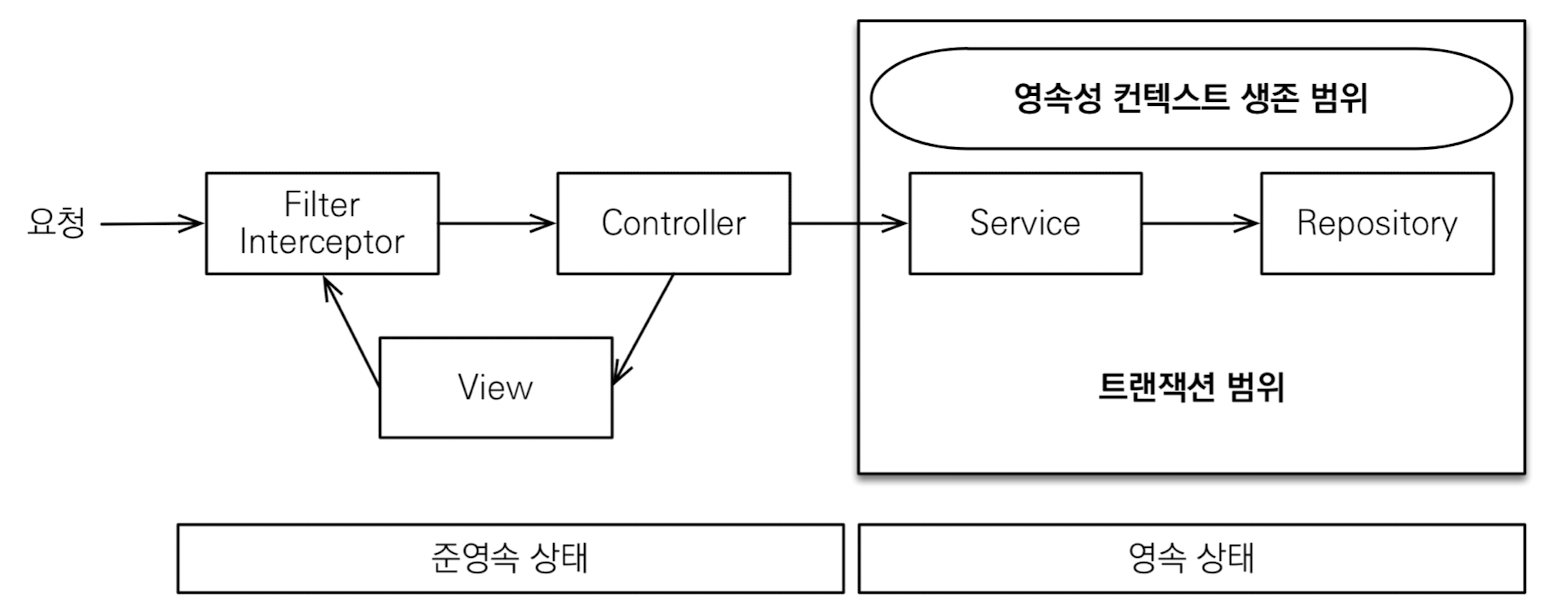
- 트랜잭션을 종료할 때, 영속성 컨텍스트를 닫고 DB 커넥션 반환
- 장점: 커넥션 리소스 낭비 X
- 단점: 모든 지연 로딩은 트랜잭션안에서 처리해야 함
- 부분적 해결책: OSIV 켜기 / 트랜잭션 내에서 지연로딩 모두 처리 / 페치조인
- 영속성 컨텍스트 종료 후 바깥에서 지연 로딩 시 다음 예외 발생
LazyInitializationException: could not initialize proxy
-
Command와 Query를 분리(CQS)하면 OSIV 끈 상태에서도 복잡성 관리가 편리
- 보통 성능 이슈는 조회에서 발생
- 핵심 비즈니스 로직과 조회 로직은 라이프사이클이 다름
- 뷰는 자주 변함
- 한 곳에 모았는데 핵심 비즈니스 로직 4~5개, 조회 로직 30개면 유지보수성 급격히 감소
- 패키지 구조
-
service.order.OrderService: 핵심 비즈니스 로직 -
service.order.query.OrderQueryService: 뷰 (주로 읽기 전용 트랜잭션 사용)- 쿼리 서비스 용 패키지를 따로 두는게 좋음
- 엔터티를 뷰 용 DTO로 변환하는 작업을
QueryService에서 처리
-