
JPA 개요
- SQL 중심적인 개발의 문제점
- 반복적인 자바 객체 매핑 작업 (자바 객체 -> SQL, SQL -> 자바 객체)
-
SQL 유지보수의 어려움
- 테이블 필드 추가 시 모든 SQL에 개발자가 직접 필드를 추가해야 함
- 실수 시 기능 이상 발생
- 정형화된 쿼리 반복 (
INSERT,UPDATE,SELECT,DELETE)
-
패러다임의 불일치 (객체 지향 & 관계형 DB)
- 객체 지향 & 관계형 DB의 차이
- 상속
- 객체 상속 VS Table 슈퍼타입 서브타입 관계 (One-to-Many)
- 여러 테이블을 삽입하고 조회하게 되어 객체 변환 과정이 번거로움
- 연관관계 (e.g
Team,Member)- 객체는 참조(Reference) VS Table은 Foreign Key
- 객체를 테이블에 맞추어 모델링하게 됨 (
teamId) - 객체 다운 모델링을 하면 객체 변환 과정이 번거로움(
Team)
- 객체 그래프 탐색
- 객체는 자유롭게 객체 그래프 탐색 VS 실행하는 SQL에 따라 탐색 범위 결정
- 계층형 아키텍처에서 진정한 의미의 계층 분할이 어려움 (엔터티 신뢰 문제)
- 즉, 물리적으로는 계층이 분할되었지만, 논리적으로는 계층이 분할되어 있지 않음
- 계층형 아키텍처는 다음 계층을 믿고 쓸 수 있어야 함
- 만약, 서비스 계층 개발 중에 다른 개발자가 만든 DAO
find를 쓸 때
조회된 엔터티의getTeam,getOrder나아가getDelivery가 가능한지는
DAO 내부의 SQL 쿼리를 까봐야 알 수 있음 - 즉, 다음 계층에 대한 신뢰가 없음
- 데이터 식별 방법 (
==)- 같은 ID를 2번의 조회로 데이터 가져온 상황에서
- SQL로 조회한 2개 데이터는 서로 다르다
- 컬렉션에서 같은 ID로 찾은 객체는 항상 같음
- 같은 ID를 2번의 조회로 데이터 가져온 상황에서
- 상속
- 객체 다운 모델링을 할수록 매핑 작업이 무수히 늘어남
- 객체를 자바 컬렉션에 저장하듯이 DB에 저장할 수는 없을까?
- 객체 지향 & 관계형 DB의 차이
- JPA (Java Persistence API)
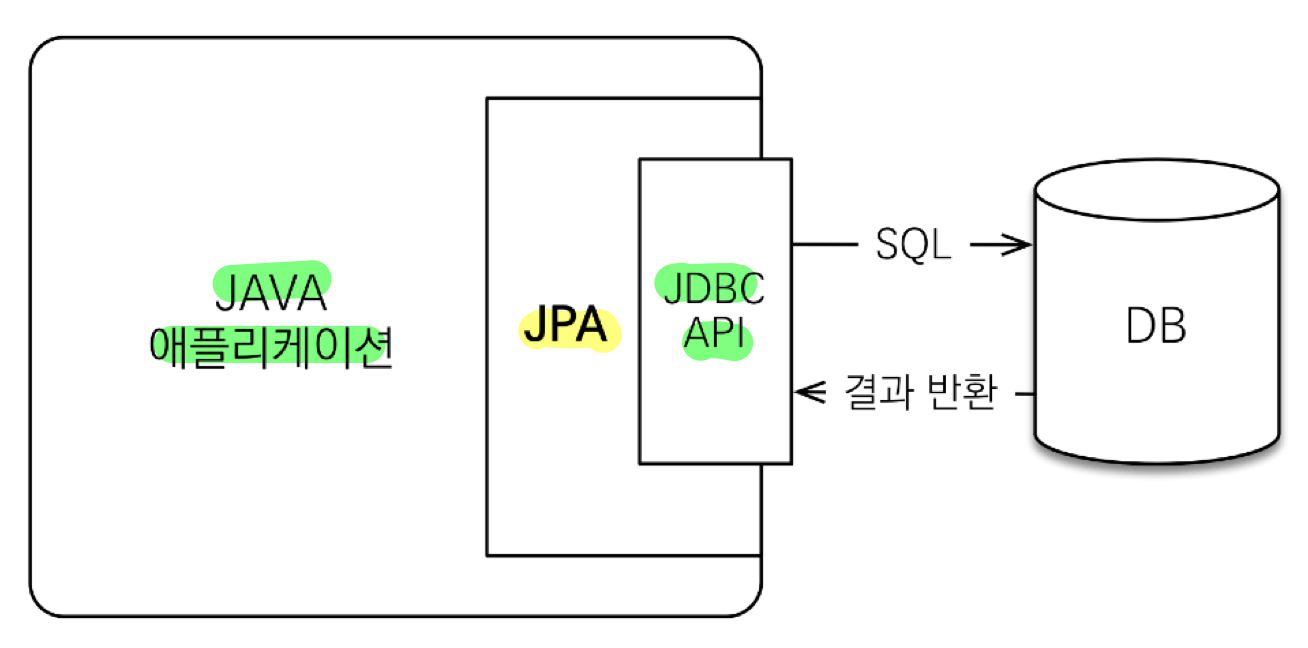
- 자바 진영의 ORM 기술 표준
- JPA 표준 명세로 인터페이스의 모음
- JPA 2.1 표준 명세를 구현한 3가지 구현체 (하이버네이트, EclipseLink, DataNucleus)
- 2.0에서 대부분의 ORM 기능을 포함
- 객체는 객체대로 RDB는 RDB대로 설계하고 ORM 프레임워크가 중간에서 매핑
- JVM 내 JAVA 애플리케이션과 JDBC API 사이에서 동작
- 패러다임 불일치를 중간에서 해결 (SQL 생성, 객체 매핑)
- SQL 중심적인 개발에서 벗어나 객체 중심으로 개발해 생산성 및 유지보수 향상
- 필드 추가 시, JPA가 알아서 SQL을 동적 생성
- 자바 컬렉션에 저장하듯이 코드를 작성하여 패러다임 불일치를 해결 (객체 매핑 자동화)
- 자바 진영의 ORM 기술 표준
JPA 설정하기
- JPA 설정 파일 (
persistence.xml)- 경로:
/META-INF/persistence.xml - 이름 지정:
persistence-unit name - 설정 값 분류
- JPA 표준 속성:
jakarta.persistence.~ - 하이버네이트 전용 속성:
hibernate.~
- JPA 표준 속성:
-
스프링 부트를 쓴다면 생성할 필요 없음
- 대신
application.properties사용 -
spring.jpa.properties하위에 똑같은 속성 추가
- 대신
- 경로:
-
Dialect (방언)
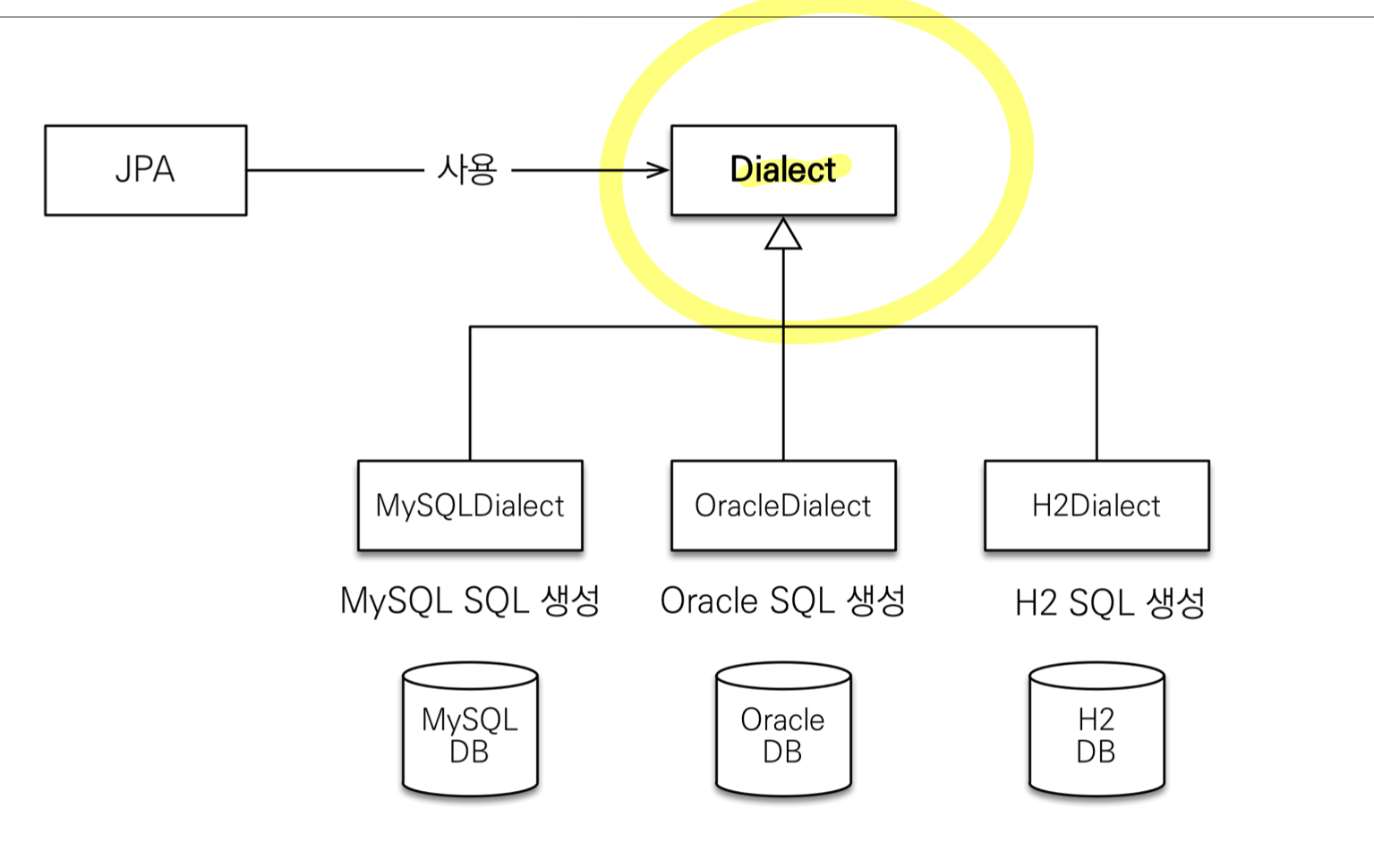
- SQL 표준을 지키지 않는 특정 DB만의 고유한 기능
- 각각 DB가 제공하는 SQL 문법 및 함수가 조금씩 다름
- 페이징: MySQL-LIMIT, Oracle-ROWNUM
- JPA는 특정 DB에 종속되지 않지만 Dialect 설정은 필요
-
hibernate.dialect속성 값 지정 (하이버네이트는 40가지 이상의 Dialect 지원) - H2:
H2Dialect - Oracle:
Oracle10gDialect - MySQL:
MySQL5InnoDBDialect
-
-
데이터베이스 스키마 자동생성 (DDL)
- 애플리케이션 실행 시점에 DDL 자동 생성
- 설정한 Dialect에 맞춰서 적절한 DDL 생성
- 설정값 (
hibernate.hbm2ddl.auto)-
create: 기존 테이블 삭제 후 다시 생성 (DROP+CREATE) -
create-drop-
create+ 종료 시점에 테이블 삭제 (DROP+CREATE+DROP) - 테스트 사용 시 마지막에 깔끔히 날리고 싶을 때 사용
-
-
update-
변경분만 반영 (
ALTER) - 컬럼 추가는 가능하지만 지우기는 안됨
- 운영에서 사용하면 안됨 X
-
변경분만 반영 (
-
validate: 엔터티와 테이블이 정상 매핑되었는지만 확인 -
none: 사용하지 않음 (주석처리하는 것과 똑같음)
-
- 유의사항
- 개발, 스테이지, 운영 서버는 반드시 validate 혹은 none만 사용!!!! (스크립트 권장)
- 개발초기 단계 혹은 로컬에서만 create 혹은 update 사용
DDL 생성 기능
JPA의 DDL 생성 기능(
@TableuniqueConstraints,@Columnnullable등)은 DB에만 영향을 주고 런타임에 영향을 주지 않는다.
즉, 애플리케이션 시작 시점에 제약 추가 같은 DDL 자동 생성에만 사용하고, 실제 INSERT, SELECT 등의 JPA 실행 로직에는 큰 영향을 주지 않는다.
JPA 동작 원리
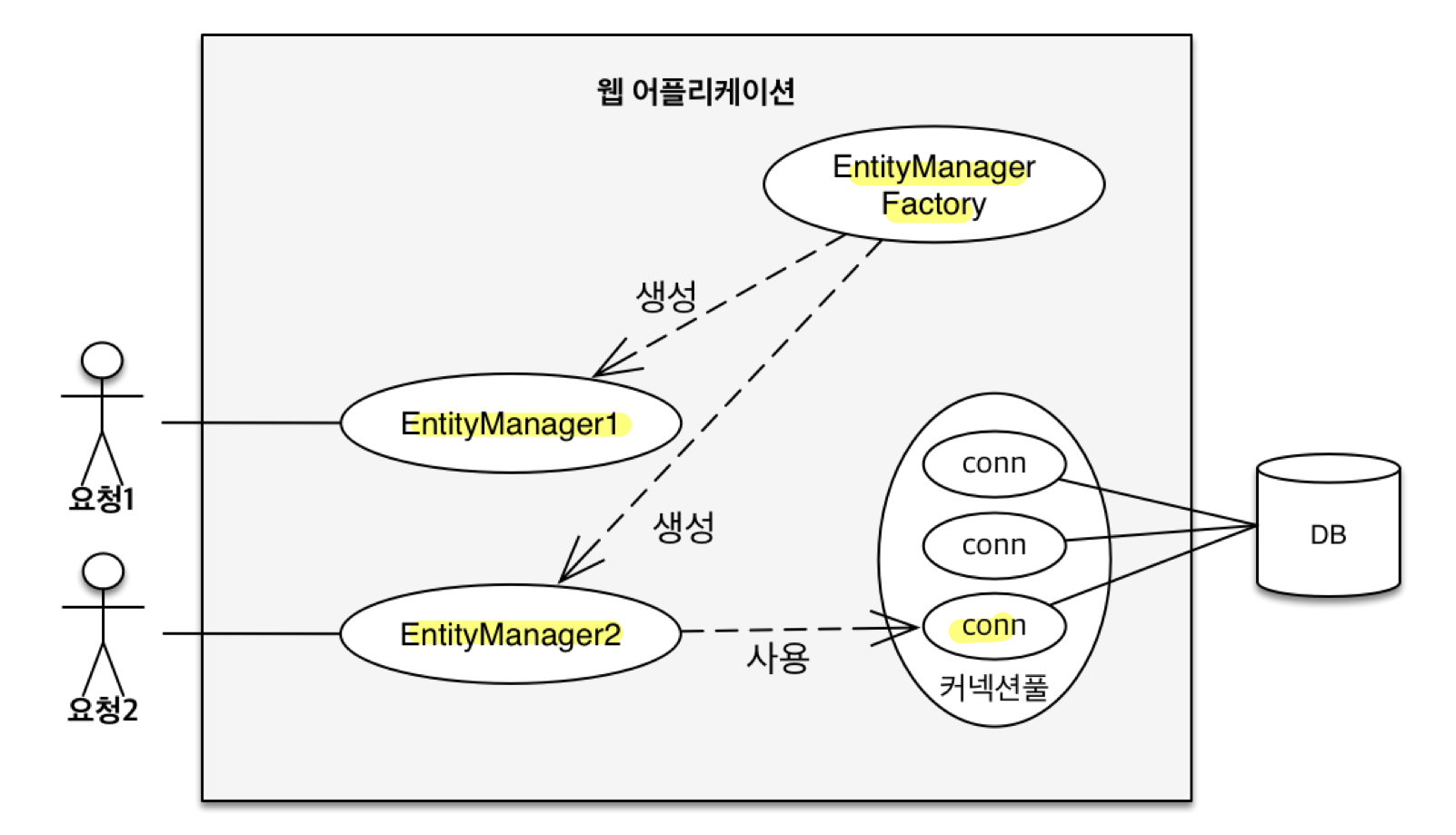
- 주요 객체
-
EntityManagerFactory- 하나만 생성해서 애플리케이션 전체에서 공유
-
EntityManager- 한 요청 당 1회 사용하고 버림 (쓰레드 간 공유 X)
-
-
JPA의 모든 데이터 변경은 트랜잭션 안에서 실행
EntityTransaction transaction = em.getTransaction();transaction.begin();...transaction.commit();
- 동작 순서
-
Persistence(클래스)가persistence.xml설정 정보 조회 -
Persistence가EntityManagerFactory생성 -
EntityManagerFactory가EntityManager생성
-
영속성 컨텍스트
-
애플리케이션과 DB(JDBC API) 사이에서 엔터티를 관리하는 논리적인 영역
- 엔터티를 영구 저장하는 환경
- 눈에 보이지 않는 논리적인 개념
- 엔터티 매니저와 영속성 컨텍스트는 1:1 관계 (엔터티 매니저를 통해 접근)
- 엔터티의 생명주기
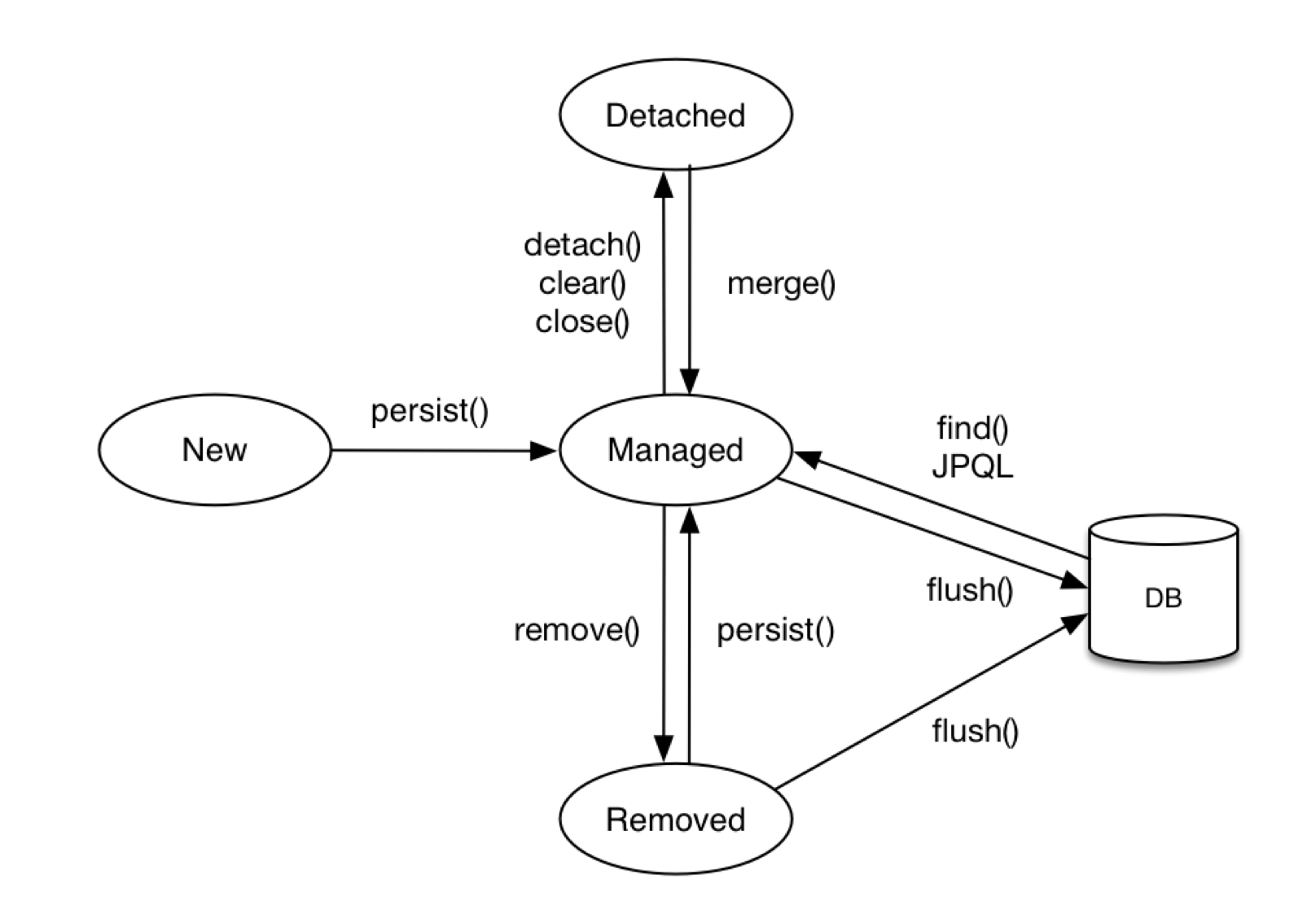
-
비영속 (new/transient)
- 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
- e.g. 새로운 객체 생성
-
영속 (managed)
- 영속성 컨텍스트에 관리되는 상태
- e.g.
em.persist(member);
-
준영속 (detached)
- 영속성 컨텍스트에 저장되었다가 분리된 상태
- 영속성 컨텍스트가 제공하는 기능을 사용하지 못함 (더티 체킹 등…)
- 방법
-
em.detach(member): 특정 엔터티만 준영속상태로 전환 -
em.clear(): 영속성 컨텍스트를 완전히 초기화 -
em.close(): 영속성 컨텍스트를 종료
-
-
삭제 (removed)
- 실제 DB에 삭제를 요청하는 상태 (
DELETESQL 생성) - e.g.
em.remove(member);
- 실제 DB에 삭제를 요청하는 상태 (
-
비영속 (new/transient)
영속성 컨텍스트의 이점 - JPA 성능 최적화 기능
- 애플리케이션과 DB 사이에 영속성 컨텍스트라는 계층이 생기면서 Buffering, Cacheing 등의 이점 얻음
-
1차 캐시
- ID(PK)가 Key, Entity가 value인 Map (메모리 내 영속성 컨택스트 안에 위치)
- 동작
- 엔터티가 1차 캐시에 있으면 1차 캐시에서 조회
- 1차 캐시에 없으면 DB에서 조회한 후 1차 캐시에 저장 (=DB 조회가 엔터티를 영속 상태로 만듦)
- 이점
- 조회 성능 향상
- 같은 트랜잭션 안에서는 1차 캐시를 조회해 같은 엔티티를 반환
- 다만, 큰 성능 향상은 없음
- 조회가 DB까지 가지 않아서 약간의 성능 향상
- 하지만, 서비스 전체적으로 봤을 때 이점을 얻는 순간이 매우 짧고 효과가 적음
- 한 비즈니스 로직 당 하나의 영속성 컨텍스트를 사용해서 이점 순간이 짧음
- 고객 10명이 와도 모두 별도의 1차 캐시를 가지므로 효과가 적음
- 같은 것을 여러 번 조회할 정도로 비즈니스 로직이 매우 복잡한 경우 도움이 될 때가 있을 것
- 동일성 보장
- 같은 트랜잭션 내에서 영속 엔터티는 여러 번 조회해도 동일성이 보장됨
-
애플리케이션 차원에서
Repeatable Read트랜잭션 격리 수준 보장- 예를 들어, 트랜잭션 격리수준이
Read Committed여도 보장
- 예를 들어, 트랜잭션 격리수준이
- 조회 성능 향상
- 트랜잭션을 지원하는 쓰기 지연 (transactional write-behind)
-
쓰기 지연
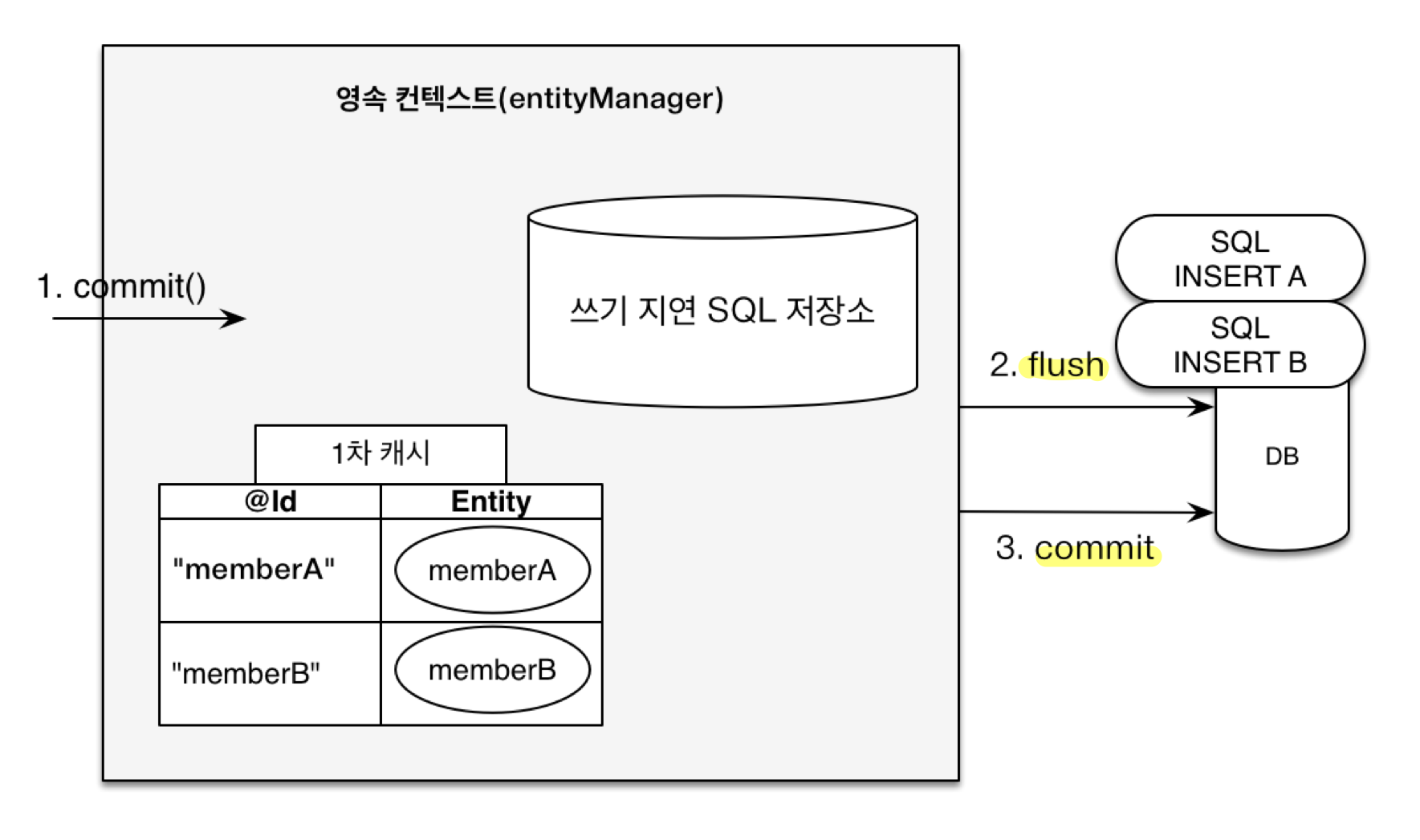
- 트랜잭션 커밋 순간 쓰기 지연 SQL 저장소에 쌓아둔 SQL을 한 번에 DB에 전달하고 바로 커밋
-
INSERTSQL을 버퍼에 모아두었다 트랜잭션 커밋 시 한 번에 DB에 보냄 -
UPDATE,DELETE도 트랜잭션 커밋 시 한 번에 보내서 락(Lock) 시간을 최소화 - JDBC BATCH SQL 이용
- 성능 상 이점 (일반 상황 & 배치 작업) - 큰 성능향상은 아님
-
- 트랜잭션 커밋 순간 쓰기 지연 SQL 저장소에 쌓아둔 SQL을 한 번에 DB에 전달하고 바로 커밋
-
변경 감지 (Dirty Checking)
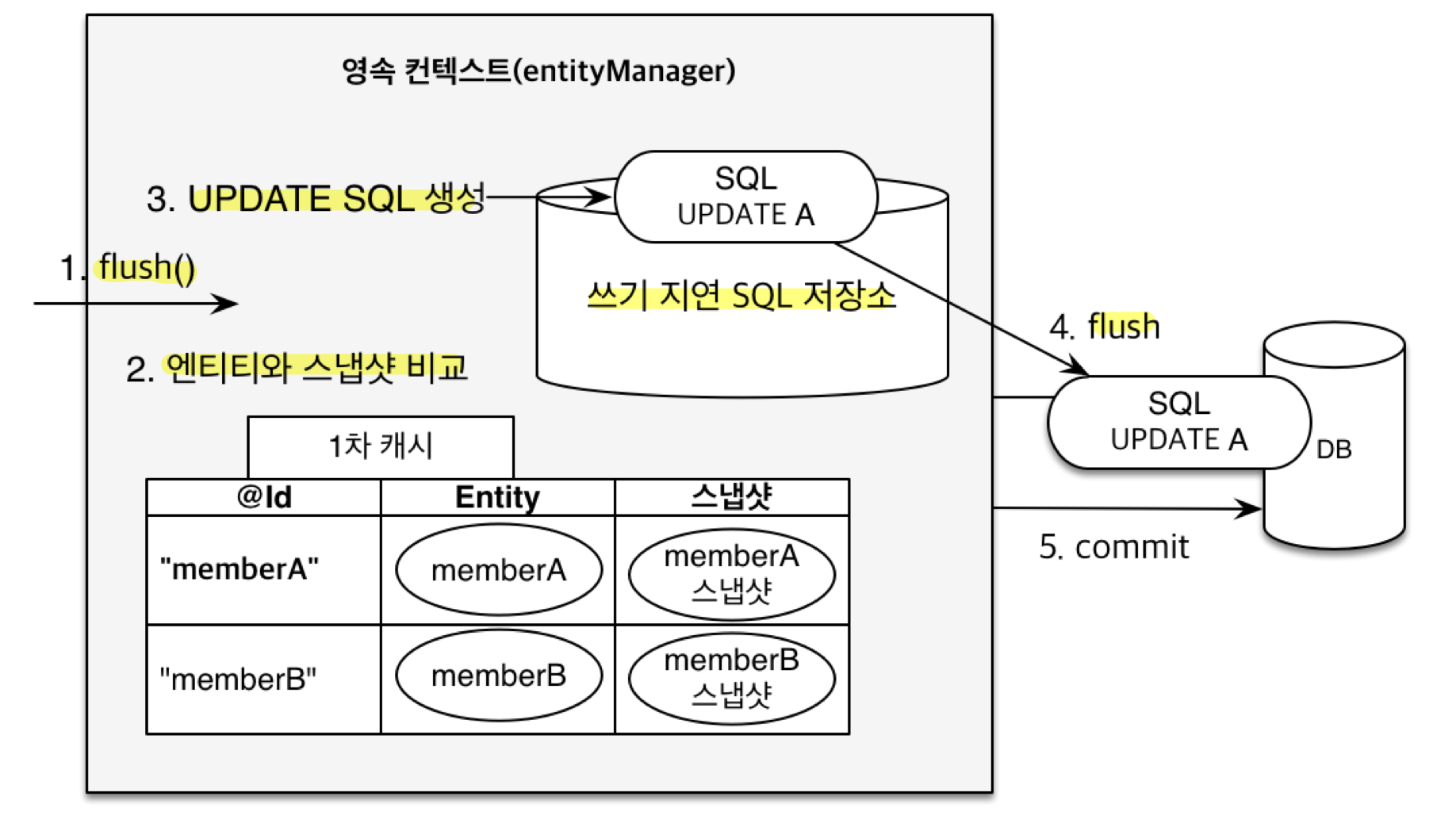
- 엔터티의 조회 순간 1차 캐시에 엔터티와 스냅샷을 함께 보관
- 변경 감지 과정
-
transaction.commit()호출 ->flush()메서드 호출 - 현재 엔터티와 스냅샷을 비교
-
변경사항이 있으면
UPDATESQL을 생성해 쓰기 지연 SQL 저장소에 적재 - 적재된 SQL을 한 번에 DB로 보냄 (실제 flush)
- 실제 DB 커밋 발생
-
-
쓰기 지연
-
지연 로딩 (Lazy Loading) & 즉시 로딩 (Eager Loading)
- 지연 로딩: 객체가 실제 사용될 때 로딩
- 즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
- 지연 로딩으로 개발하다가 성능 최적화가 필요한 부분은 즉시 로딩을 적용해 해결
기술 사이에 계층이 생길 때
중간에 기술이 껴서 계층이 생긴다면 항상 2가지의 성능 최적화가 가능하다.
- 캐시
- Buffer로 Write 가능 (모아서 보내기 가능)
플러시 (Flush)
- 영속성 컨텍스트의 변경내용을 DB에 반영하는 것 (=동기화)
- 쓰기 지연 SQL 저장소에 쌓아둔 쿼리를 DB에 날리는 작업
- 영속성 컨텍스트를 비우지는 않음
-
트랜잭션이 있기 때문에 플러시 개념이 존재할 수 있음
- 플러시는 SQL 전달 타이밍만 조절
- 결국 커밋 직전에만 동기화하면 됨
- 플러시 방법
-
em.flush()- 직접 호출- 테스트 이외에 직접 사용할 일은 거의 없음
- 쿼리를 직접 확인하고 싶거나 커밋 전에 SQL을 미리 반영하고 싶을 때
-
트랜잭션 커밋 - 플러시 자동 호출
- 변경 감지가 먼저 발생
- 쓰기 지연 SQL 저장소의 쿼리(등록, 수정, 삭제)를 DB에 전송
-
JPQL 쿼리 실행 - 플러시 자동 호출
em.persist(memberA); em.persist(memberB); em.persist(memberC); //중간에 JPQL 실행 query = em.createQuery("select m from Member m", Member.class); List<Member> members= query.getResultList();- JPQL은 1차 캐시를 거치지 않고 SQL로 번역되어 바로 실행되므로 항상 플러시를 자동 호출
- 영속성 컨텍스트에 새로 생성된 엔터티가 아직 DB에 반영되지 않았기 떄문
-
em.setFlushMode로 조절할 수 있으나 굳이 이 옵션을 사용할 일은 없음
-
Entity 매핑
객체 & 테이블 매핑
-
@Entity- JPA가 관리하는 객체 (=엔터티)
- 기본 생성자 필수 (public 또는 protected)
- final 클래스, final 필드, enum, interface, inner 클래스 사용 X
-
name속성: JPA에서 사용할 엔터티 이름 지정 (기본값: 클래스 이름, 가급적 기본값 사용)
-
@Table- 엔터티와 매핑할 테이블 지정
- 속성
-
name- 매핑할 테이블 이름 지정
- 기본값: 엔터티 이름
- 지정DB 이름이
ORDERS면name="ORDERS"지정)
-
uniqueConstraints(DDL): DDL 생성 시 유니크 제약 조건 생성 -
catalog: DB catalog 매핑 -
schema: DB schema 매핑
-
필드 & 컬럼 매핑
-
@Column(컬럼 매핑)-
name: 매핑할 컬럼 이름 -
nullable(DDL): null 값 허용 여부 설정 -
length(DDL): 문자 길이 제약조건 설정 (String타입에만 사용, 기본값 255) -
precision,scale(DDL):BigDecimal혹은BigInteger에서 사용 -
insertable,updatable: DB는 못막지만 애플리케이션 단에서 등록 및 변경을 막거나 허용 -
unique: 유니크 제약 적용 (제약이름이 랜덤 생성되어 보통@Table의 속성으로 유니크 적용) -
columnDefinition: DB 컬럼 정보 적용 (특정 DB 종속적인 옵션 적용 가능)
-
-
@Enumerated(enum 타입 매핑)-
EnumType.String을 반드시 적용할 것! (DB에VARCHAR(255)로 삽입) -
EnumType.ORDINAL는 값이 순서를 기준으로 숫자(Integer)로 DB에 삽입됨 - 따라서,
EnumType.ORDINAL는 새로운 Enum 값 추가 시 매우 위험!
-
-
@Lob(BLOB,CLOB타입 매핑)- 필드 타입에 따라 매핑이 달라짐
-
String,char[]: DB 타입CLOB매핑 -
byte[]: DB 타입BLOB매핑
-
@Transient- 메모리 상에서만 임시로 어떤 값을 보관하고 싶을 때 사용 (메모리 임시 계산값, 캐시 데이터…)
- 해당 컬럼은 메모리에서만 쓰고 DB에서 쓰지 않음
-
@Temporal(날짜 타입 매핑)-
@Temporal은 생략하고LocalDate,LocalDateTime타입을 사용하자! - JAVA 8부터 하이버네이트가 애노테이션 없이 타입만으로 컬럼 매핑
-
기본키 매핑 (Primary Key)
-
권장 식별자 전략
- Long 형 + 인조키 + 키 생성전략 사용 (auto-increment 혹은 sequence 전략 사용)
- 때에 따라 UUID나 회사 내 룰에 따른 랜덤값 사용
-
@Id(직접 할당)-
@Id만 사용 시 PK를 사용자가 직접 할당
-
-
@GeneratedValue(자동 생성)- DB가 PK 자동 생성
-
generator속성-
@SequeceGenerator의name혹은@TableGenerator의name을 등록
-
-
strategy속성-
IDENTITY- 기본 키 생성을 데이터베이스에 위임
- ID 값을 NULL로 주고 INSERT 쿼리 진행하면 DB가 자동 생성
-
em.persist()시점에 즉시 INSERT SQL 실행해 DB에서 식별자 조회- DB 접근 없이는 PK 값을 알 수 없어, 영속성 컨텍스트 관리가 불가
- INSERT 후 JDBC API 반환값으로 1차 캐시에 ID 및 엔터티 등록
- MySQL, PostgreSQL, SQL Server, DB2 (MySQL
AUTO_INCREMENT)
-
SEQUENCE- DB 시퀀스 오브젝트 사용 (유일한 값을 순서대로 생성하는 DB 오브젝트)
-
트랜잭션 커밋 시점에 실제 INSERT SQL 실행
-
em.persist()시점에 DB에 접근해 현재 DB 시퀀스 값 조회Hibernate: call next value for MEMBER_SEQ
- 메모리에 조회 시퀀스 값을 올려두고 1차 캐시에 ID 및 엔터티 등록
-
- Oracle, PostgreSQL, DB2, H2
-
@SequenceGenerator: 테이블마다 시퀀스를 따로 관리하고 싶을 때 사용-
name: 식별자 생성기 이름 -
sequenceName- 매핑할 DB 시퀀스 오브젝트 이름
- 기본값:
hibernate_sequence
-
initialValue: 처음 시작하는 수 지정 (기본값: 1) -
allocationSize- 시퀀스 한 번 호출에 증가하는 수
- SELECT 네트워크 호출을 줄여서 성능 최적화를 시키는 방법
- 기본값: 50 (50~100정도가 적당)
- DB에 미리 50개를 올려두고 메모리에서 그 개수만큼 1씩 사용
- 즉, 50개마다 call next 호출
- 웹 서버가 여러 개여도 동시성 문제 X
- 시퀀스 사이에 구멍이 생길 뿐
- 웹서버를 껐다키면 메모리의 시퀀스 정보가 날라가므로
- 구멍이 문제는 없지만 낭비 최소화 위해 사이즈 너무 크게 하지 말 것
-
catalog,schema: DB catalog, schema 이름
-
-
TABLE- 키 생성용 테이블을 사용해 마치 시퀀스처럼 동작시키는 전략
- 모든 DB에서 사용 가능하지만 성능이 안좋음
-
@TableGenerator: 키 생성기-
name: 식별자 생성기 이름 -
table: 키 생성 테이블 명 -
pkColumnValue: 키로 사용할 값 이름 (기본값: 엔터티 이름) -
allocationSize: 시퀀스 한 번 호출에 증가하는 수 (성능 최적화) - …
-
-
AUTO(기본값): 방언에 따라 자동 지정 (IDENTITY, SEQUENCE, TABLE 중 하나 선택)
-
연관관계 매핑
-
객체 지향 모델링의 필요성
-
객체는 참조를 사용해 연관된 객체를 찾아야 함
- 엔터티 서로를 참조하는 단방향 연관관계 2개를 만들어야 함 (=양방향 연관관계)
- 테이블 중심 설계 지양 (=외래키를 그대로 엔터티에 가져오는 설계)
- 외래키 하나로 양방향 연관관계 맺음 (조인을 통해 서로 조회)
- 이는 객체 지향적 X, 객체 간 협력 관계를 만들 수 없음
-
객체는 참조를 사용해 연관된 객체를 찾아야 함
- 연관관계 방향
- 단방향 연관관계
- 한 쪽 엔터티만 다른 쪽 엔터티를 참조 (참조가 1군데)
-
@JoinColumn,@ManyToOne
- 양방향 연관관계
- 엔터티가 서로를 참조 (참조가 2군데)
- 외래키를 관리하지 않는 엔터티 쪽에도 단방향 연관관계 추가 (
mappedBy) -
@OneToMany(mappedBy = "team")(멤버 엔터티의 팀 변수를mappedBy에 지정)
- 단방향 연관관계
-
연관관계 주인
- 양방향 매핑에서 외래키를 관리하는 참조
-
@JoinColumn위치한 곳이 연관관계 주인 - 연관관계 주인을 통해서만 외래키 설정 가능 (양방향 매핑 시 주의점)
-
- 주인이 아닌 쪽은 외래키에 영향을 주지 않고 읽기만 가능
-
mappedBy위치한 곳 - 참조 추가가 DB에 영향을 주지 않음
-
- 양방향 매핑에서 외래키를 관리하는 참조
-
다중성
-
다대일 (N:1,
@ManyToOne)- 연관관계 주인이 N쪽 (외래키가 있는 쪽에
@JoinColumn) -
사용 지향 (가장 많이 사용)
- 객체지향적으로 조금 손해 보더라도 DB에 맞춰 ORM 관리하면 운영이 편해짐
- 객체지향적 손해 예:
Member에서Team으로 갈 일이 없는데 참조를 만들어야 할 때
- 연관관계 주인이 N쪽 (외래키가 있는 쪽에
- 일대다 (1:N,
@OneToMany)- 연관관계 주인이 1쪽 (외래키가 없는 쪽에
@JoinColumn) - 사용 지양
- 일대다 양방향은 공식적으로 존재하지 않아서 읽기 전용 필드로 우회해 구현
@JoinColumn(insertable=false, updatable=false)- 양쪽 엔터티에 모두
@JoinColumn이 있고 N쪽이 읽기전용 컬럼
- 연관관계 주인이 1쪽 (외래키가 없는 쪽에
-
일대일 (1:1,
@OneToOne)- 주 테이블과 대상 테이블 중 외래키 위치 선택 가능
- 주테이블: 주로 많이 액세스하는 테이블
- 먼 미래 보지 않고 주 테이블 쪽에 위치시키는 것이 괜찮다
- 외래키가 있는 곳이 마찬가지로 연관관계의 주인 (
@JoinColumn), 반대편은mappedBy - 제약 조건없이 애플리케이션 단에서 일대일이 가능하지만 세심한 관리 필요
- DB 입장에서는 외래키에 UNIQUE 제약조건이 추가된게 일대일 관계
- 주 테이블과 대상 테이블 중 외래키 위치 선택 가능
- 다대다 (N:M,
@ManyToMany)- 다대다는 연결 테이블을 추가해 일대다, 다대일 관계로 풀어내야 함
- 관계형 DB는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
- 다만,
@ManyToMany사용은 지양-
@ManyToMany는 자동으로 연결 테이블을 생성하지만 다른 데이터 필드 추가가 불가 - 쿼리가 생각하지 못한 방향으로 나갈 수 있음
-
-
@OneToMany,@ManyToOne사용!- 연결 테이블을 엔터티로 승격시키자
- 연결 테이블 PK는 Compound Key (FK + FK)보다 하나의 인조키 만드는게 낫다
- 운영하다보면 종속되지 않은 아이디 값이 매우 유용!
- 다대다는 연결 테이블을 추가해 일대다, 다대일 관계로 풀어내야 함
-
다대일 (N:1,
-
지향할 연관관계 매핑 전략
-
최대한 단방향 매핑으로만 설계 한 후, 애플리케이션 개발 시 고민하며 양방향 매핑 추가하자
- 단방향 매핑만으로도 이미 연관관계 매핑은 완료, 양방향 매핑은 조회 추가일 뿐
- 객체 입장에서는 양방향이 큰 메리트가 없으므로, 필요한 곳에만 추가하는 것이 더 좋음
- 다만 실무에서 JPQL 짜다보면 결국 양방향 매핑을 많이 쓰게되긴 함
-
연관관계의 주인은 DB 테이블 상 외래키가 있는 곳으로 정하자
- 반대로 주인을 정하면
- 직관적이지 않은 쿼리로 테이블이 헷갈림
- Team에 멤버를 추가했는데 Member Table로 쿼리가 나가 헷갈림
- 성능 문제가 생김 (크진 않아도 손해는 손해)
- Team과 Member를 추가할 때 INSERT 2번 UPDATE 1번 실행
- Team은 자신의 엔터티의 외래키가 없으므로 Member에 외래키 업데이트 실행
- 직관적이지 않은 쿼리로 테이블이 헷갈림
- 반대로 주인을 정하면
-
양방향 매핑시 연관관계 편의 메서드를 생성하자
- JPA 기능적으로는 연관관계 주인에만 값을 세팅하면 동작
- 다만, 객체지향 관점에서 항상 양쪽 모두 값을 입력하는 것이 옳다!
- 주인만 값 세팅하면 커밋 전까지 1차 캐시에만 있어서 주인이 아닌 쪽 접근 시 실패
- 테스트 시에도 순수한 자바코드를 사용하므로 양쪽 다 입력하는 것이 문제를 예방
- 메서드 네이밍 시 setXxx는 지양 (e.g.
changeTeam) - 주인 쪽, 주인이 아닌 쪽 중 한 곳에만 연관관계 편의 메서드 작성해야 함
- 모두 작성하면 무한 루프 발생 확률 높음
- Lombok
toString만드는 것도 왠만하면 쓰지 말 것! - 컨트롤러에 엔터티 절대 반환하지 말 것! (DTO로 변환 반환, API 스펙 변경 X)
- Lombok
- 상황마다 좋은 쪽이 다름 (특정 객체를 기준으로 풀고 싶을 때 해당 객체에 위치시킴)
- 모두 작성하면 무한 루프 발생 확률 높음
-
일대일 관계에서는 주 테이블에 외래키 위치시키자 (너무 먼 미래 고려하지 말고!)
- 주 테이블에 외래키
- 객체지향 개발자가 선호 (JPA 매핑 편리)
- 장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능 (프록시 객체)
- 단점: 값이 없으면 외래키에 null 허용
- 대상 테이블에 외래키 (양방향만 가능)
- 전통적인 데이터베이스 개발자 선호
- 장점: 일대다 관계로 변경시 테이블 구조가 유지되어 편리 (변경 포인트가 적음)
-
프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨
- 주 객체의 대상 객체 참조 여부를 판단하려면, 대상 테이블에 쿼리를 날려 외래키 존재 여부를 확인해야 하므로 즉시로딩 진행 (지연로딩 세팅이 의미가 없음)
- 주 테이블에 외래키
-
최대한 단방향 매핑으로만 설계 한 후, 애플리케이션 개발 시 고민하며 양방향 매핑 추가하자
상속 관계 매핑
- DB의 슈퍼타입-서브타입 관계 논리 모델링 기법을 객체 상속을 활용해 매핑
- 지향 전략
- 기본은 조인 전략
- 서비스가 단순할 때는 단일 테이블 전략으로 진행 (복잡하게 에너지 쓰지 않기)
-
일부 컬럼을 JSON으로 저장하는 방식으로 대체하기도 함
- 테이블 상속 전략은 대규모 서비스에서 복잡도가 높을 수 있음
- 상황 맞게 선택!
- 주요 어노테이션
-
@Inheritance(strategy=InheritanceType.XXX)- 슈퍼타입-서브타입 관계에 대해 물리 모델 구현 방법 지정
- 부모 클래스에 적용
- 부모 클래스는 의도상 사용하지 않으므로
abstract class지향- 부모만 단독으로 저장할 일이 있다면 일반 클래스로 사용
-
TABLE_PER_CLASS는 반드시abstract class를 사용 (부모 테이블 생성 막음)
- 테이블 상속 전략 종류 (
InheritanceType)-
JOINED(Identity = One to One Type = 조인 전략)- 조인 전략이 정석!!
- 장점
- 테이블 정규화
- 객체랑 잘맞고 설계 관점에서 매우 깔끔
- 단점
- 조회시 쿼리가 복잡하고 조인을 많이 사용 (조인은 잘 맞추면 성능 매우 잘나옴)
- 데이터 저장 시 INSERT 쿼리 2번 호출
-
@DiscriminatorColumn필요성- 항상
@DiscriminatorColumn적용하자 (운영에 유리) -
DTYPE이 없어도 기능상 문제는 없음
- 항상
-
SINGLE_TABLE(Rollup = Single Type = 단일 테이블 전략)- 장점
- 조인이 없어 조회 성능이 빠르고 쿼리가 단순함
- 단점
- 자식 엔터티 매핑 컬럼은 모두 NULL 허용 (데이터 무결성 관점에서 치명적)
- 단일 테이블에 모든 것 저장하므로 테이블이 커지고 상황에 따라 조회 성능 감소
-
@DiscriminatorColumn필요성-
@DiscriminatorColumn생략해도DTYPE컬럼 생성 -
DTYPE이 반드시 필요하므로
-
- 장점
-
TABLE_PER_CLASS(Rolldown = Plus Type = 구현 클래스마다 테이블 전략)- DB 설계 관점 및 객체 ORM 관점 모두에서 지양 (사용 X)
- 장점
- 서브 타입을 명확히 구분해 처리할 때 효과적
- 단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느림 (UNION SQL 필요)
- ID로 조회해도 3개 테이블을 다 찔러봐야 알 수 있음
- 변경에도 유연하지 못한 설계
- 여러 자식 테이블을 함께 조회할 때 성능이 느림 (UNION SQL 필요)
-
@DiscriminatorColumn필요성@DiscriminatorColumn필요 없음
-
-
@DiscriminatorColumn-
DTYPE컬럼 생성 - 부모 클래스에 적용
-
name속성으로 컬럼 이름 지정 (기본값:DTYPE)
-
-
@DiscriminatorValue("XXX")-
DTYPE에 들어갈 Value 지정 - 자식 클래스에 적용
- 기본값: 자식 엔터티의 이름
-
-
공통 정보 매핑
-
@MappedSuperclass-
공통 매핑 정보가 필요할 때 사용
- 부모를 상속 받는 자식 클래스에 매핑 정보만 제공
- 등록일, 수정일, 등록자, 수정자 등 (
id,createdAt,createdBy…)
-
부모 클래스에 적용 (
abstract class권장)-
BaseEntity를 하나 만들고 다른 엔터티가 이를 상속
-
- 상속관계 매핑 X, 엔터티 X, 테이블과 매핑 X
- 조회, 검색 불가 (
em.find(BaseEntity)불가)
- 조회, 검색 불가 (
-
공통 매핑 정보가 필요할 때 사용
JPA에서의 상속
JPA에서는 상속관계 매핑 혹은 공통 정보 매핑만 상속 가능하다.
즉,@Entity클래스는@Entity나@MappedSuperclass로 지정한 클래스만 상속 가능
JPA 프록시 객체
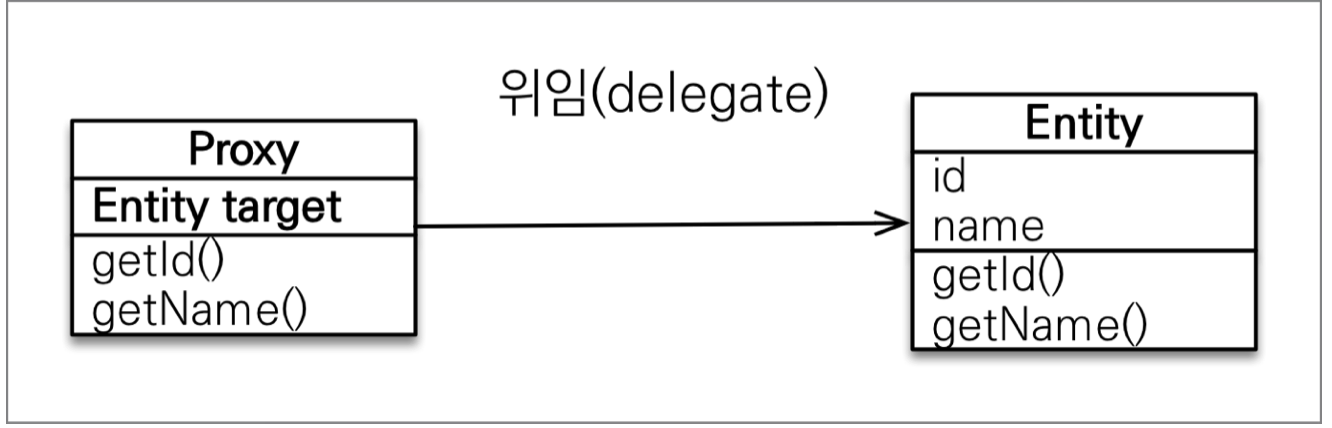
-
실제 객체의 참조를 보관하는 객체
- 사용자 입장에서는 진짜인지 프록시인지 구분하지 않고 사용
- 프록시 객체를 호출하면 프록시는 실제 객체의 메서드 호출
-
실제 클래스를 상속 받아서 만들어짐
- 실제 객체에 값만 빈 껍데기 생성
-
target(실제 객체 주소)만 추가됨
- 관련 메서드
-
em.find(): DB에서 실제 엔터티 객체 조회 -
em.getReference(): DB 조회를 미루는 프록시(가짜) 엔터티 객체 조회 -
emf.getPersistenceUnitUtil().isLoaded(entity): 프록시 인스턴스의 초기화 여부 -
entity.getClass(): 프록시 클래스 확인 -
org.hibernate.Hibernate.initialize(entity): 프록시 강제 초기화 (JPA 표준 X)
-
-
프록시 객체의 초기화
- 프록시 객체에서처음
getXxx호출 시 한 번만 초기화 진행 (=실제 객체 사용 시)- ID는 클라이언트에서 이미 알고 있는 정보이므로,
getId호출 시에는 초기화 진행 X
- ID는 클라이언트에서 이미 알고 있는 정보이므로,
- 이 때, 프록시 객체의
target이null이므로 영속성 컨텍스트에 초기화 요청 - 영속성 컨텍스트는 DB에 쿼리를 날려 실제 엔터티 객체를 만들어 프록시의
target과 연결
- 프록시 객체에서처음
- 주의사항
- 타입 체크 시
==대신instanceOf를 사용해야 한다-
언제 프록시가 반환될지, 실제 엔터티가 반환될지 예측 힘듦
- 영속성 컨텍스트에 엔터티가 이미 있다면
getReference()가 실제 엔터티 반환 -
getReference()로 프록시를 먼저 조회했다면, 이후find()는 쿼리로 실제 엔터티를 생성했음에도 프록시를 반환
- 영속성 컨텍스트에 엔터티가 이미 있다면
- 이는 JPA 동일성 보장을 지키기 위함
- JPA는 한 영속성 컨텍스트 내라면 PK 값이 동일한 객체에 대해 동일성이 보장됨
- 즉, 실제 엔터티든 프록시 객체든 pk 값이 같을 때는
==비교 결과가 true여야함
-
언제 프록시가 반환될지, 실제 엔터티가 반환될지 예측 힘듦
-
준영속 상태일 때, 프록시를 초기화하면 예외 발생
- 프록시는 영속성 컨텍스트를 이용해 초기화를 시도하므로
em.detach(),em.close(),em.clear()를 호출한 준영속 상태 엔터티는 세션이 없거나 끝났다는 예외 발생- 하이버네이트 예외:
LazyInitializationException
- 하이버네이트 예외:
- 실무에서는 보통 트랜잭션 끝나고 나서 프록시를 조회할 때 노세션 예외를 자주 만남
- 보통 트랜잭션 시작 및 끝을 영속성 컨텍스트 시작 및 끝과 맞추므로
- 프록시는 영속성 컨텍스트를 이용해 초기화를 시도하므로
- 타입 체크 시
즉시 로딩 & 지연 로딩
-
지연 로딩 (
FetchType.LAZY)- 처음 로딩 시 연관 객체는 직접 조회하지 않고 프록시로 조회
- 연관 객체는 실제로 사용하는 시점에 초기화
- 즉시 로딩 (
FetchType.EAGER)- 처음 로딩 시 한 번에 DB 쿼리를 날려 연관 객체의 실제 엔터티를 가져옴
- 조인을 사용해 가능한 SQL 한 번에 함께 조회
-
글로벌 패치 전략
- 모든 연관관계를 지연 로딩으로 사용하고 필요할 때만 패치조인으로 한 번에 가져오기
- 즉시 로딩은 예상치 못한 SQL 발생
- 즉시 로딩은 JPQL에서 N + 1 문제 일으킴
-
em.find()는 JPA가 최적화해 적어도 하나의 조인 쿼리로 가져오므로 위험도가 덜 함 - 문제는 JPQL인데, JPQL은 SQL로 바로 번역되어 쿼리를 날림
- 만일, 멤버 전체를 조회하는 쿼리를 날리면 전체 멤버를 가져옴
- 이 때, 즉시 로딩이라면 팀 값을 반드시 채워야 함
- 멤버 조회 후 바로 팀에 대한 쿼리를 멤버 각각에 대해 날려 N + 1 개 쿼리가 발생
-
- 기본값 설정 유의사항
-
@ManyToOne,@OneToOne: 기본이 즉시 로딩이므로 반드시 LAZY로 설정 -
@OneToMany,@ManyToMany: 기본이 지연 로딩
-
영속성 전이와 고아 객체
-
영속성 전이 (CASCADE)
- 엔터티를 영속화할 때, 연관된 엔터티까지 함께 영속화 (단순히 편리성 제공)
- 따로 Child 까지 영속화하지 않아도 Parent의 Childs 컬렉션에 등록된 모든 Child를 함께 영속화
- 사용 조건
-
단일 엔터티에 완전히 종속적일 때
- 하나의 부모가 자식들을 관리
- 자식들은 다른 엔터티와 연관이 없음 (소유자가 하나)
- 부모와 자식의 라이프 사이클이 동일
-
단일 엔터티에 완전히 종속적일 때
- 보통
CascadeType.ALL,CascadeType.PERSIST정도만 사용
-
고아 객체 제거 (
orphanRemoval = true)- 부모 엔터티와 연관관계가 끊어진 자식 엔터티를 자동으로 삭제
-
자식 엔터티를 부모 컬렉션에서 제거하면 자동으로 DELETE 쿼리가 나감 (참조가 끊어짐)
Parent parent1 = em.find(Parent.class, id);parent1.getChildren().remove(0);- =>
DELETE FROM CHILD WHERE ID = ?
- 반대로 부모를 제거할 때도 자식 함께 제거
- 개념적으로 부모를 제거하면 자식은 고아
- 마치
CascadeType.ALL,CascadeType.REMOVE처럼 동작
-
자식 엔터티를 부모 컬렉션에서 제거하면 자동으로 DELETE 쿼리가 나감 (참조가 끊어짐)
- 사용 조건
-
단일 엔터티에 완전히 종속적일 때 (
@OneToOne,@OneToMany만 가능)
-
단일 엔터티에 완전히 종속적일 때 (
- 부모 엔터티와 연관관계가 끊어진 자식 엔터티를 자동으로 삭제
-
CascadeType.ALL+orphanRemoval = true- 부모 엔터티를 통해 자식의 생명주기를 관리할 수 있음
- 부모 엔터티에 적용
- DDD Aggregate Root 구현에 용이
값 타입
- 값타입은 엔터티와 혼동하지 않고 정말 값 타입이라 판단될 때만 사용
- XY 좌표 수준 말고 실무에서 거의 없음
- 식별자가 필요하고 지속해서 값을 추적해야한다면 엔터티
- JPA 데이터 타입 분류
- 엔터티 타입
-
@Entity정의한 객체 - 데이터 변경이 있어도 식별자로 지속해서 추적 가능
- 생명 주기 관리
- 공유 O
-
- 값 타입
- 단순히 값으로 사용하는 자바 기본 타입 혹은 객체 (
int,Integer,String) - 식별자 없이 값만 있으므로 변경시 추적 불가
- 생명주기를 엔터티에 의존 (회원을 삭제하면 이름, 나이 필드도 함께 삭제)
-
값타입은 공유되어서는 안됨
- e.g. 회원 이름 변경시 다른 회원의 이름도 함께 변경되면 안됨
- 항상 값을 복사해서 사용 (Side effect를 예방)
- 불변 객체로 설계하는 것이 안전
- 타입 별 공유 예방 방법
- 기본 타입(primitive type)은 항상 값을 복사 (
int,double) - 래퍼 클래스나 특수 클래스(
String)는 참조를 막을 수 없어서 값 변경 자체를 막음 -
임베디드 타입은 불변 객체로 설계해야함
- 생성자로만 값을 설정하고 수정자(Setter)를 모두 없애기
- 혹은 수정자를
private으로 만들면 같은 효과
- 기본 타입(primitive type)은 항상 값을 복사 (
- 값 타입은 인스턴스가 달라도 내부 값이 같으면 같은 것으로 봐야함
- 값 타입은 동등성 비교 필요
- 동등성(equivalence) 비교: 인스턴스의 값을 비교,
equals() - 동일성(identity) 비교: 인스턴스의 참조 값을 비교,
==사용
- 동등성(equivalence) 비교: 인스턴스의 값을 비교,
- 값 타입의
equals()메서드를 적절하게 재정의해야 함-
equals()는 기본이==비교이므로, 동등성 비교를 하도록 재정의 필요 - IntelliJ 자동 생성 권장 (hashcode도 같이 만들것)
-
Use getters when available옵션 사용 -
getter를 사용하지 않으면 바로 필드에 접근 -> 프록시일 때 필드 접근 불가
-
-
- 값 타입은 동등성 비교 필요
- 분류
- 기본값 타입
- e.g. 자바 기본 타입 (
int,double), 래퍼 클래스 (Integer,Long),String
- e.g. 자바 기본 타입 (
-
임베디드 타입 (복합 값 타입)
- 주로 기본 값 타입을 모아서 새로운 값 타입을 직접 정의
- e.g. XY 좌표,
Address(city,street,zipcode),Period(startDate,endDate) - 주요 애노테이션
-
@Embeddable: 값 타입을 정의하는 곳에 표시 (기본 생성자 필수) -
@Embedded: 값 타입을 사용하는 곳에 표시 - 둘 중 하나만 사용해도 동작하지만 둘 다 명시적으로 사용하는 방향 지향
-
- 장점
- 재사용 가능, 높은 응집도
- 객체와 테이블을 세밀하게 매핑하여 설계시 개념적으로 유의미
-
Period.isWork()처럼 해당 값 타입만의 유의미한 메서드를 만들 수 있음
- 유의 사항
- 적용 전 후 DB 테이블이 달라지는 것은 없음
- 임베디드 타입 내에도 엔터티를 가질 수 있음
- 한 엔터티 내에서 같은 값 타입을 재사용 가능
-
@AttributeOverrides를 사용해 DB 컬럼 이름 매핑
-
- 임베디드 타입 값이
null이면 매핑한 컬럼 값도 모두null
- 값 타입 컬렉션
- 값 타입을 하나 이상 저장할 때 사용 (별도의 테이블 생성)
-
@ElementCollection,@CollectionTable - 부모의 라이프 사이클의 의존 (영속성 전이 + 고아 객체 제거 기능 자동 내포)
-
수정이라는 개념이 없고, 컬렉션에서 값 타입 데이터를 찾아 제거하고 새로 추가
- 임베디드 값 타입이라면 해당 객체와 값이 똑같은 객체를 새로 생성해 remove
- 이 때, 해시코드가 중요 (해시코드를 정의하지 않았다면 컬렉션에서 안지워짐)
-
식별자 개념이 없어 변경 시 추적이 어려움
- 업데이트 시 테이블 데이터 전부 제거하고 다시 새로 INSERT
- PK는 값 타입의 모든 컬럼이 묶여 구성됨
- 유의 사항
- 값 타입 컬렉션은 정말 단순할 때만 사용
- 셀렉트 박스 (치킨, 피자, etc…) 수준의 단순한 비즈니스 로직
- 추적할 필요 없고 값이 바뀌어도 업데이트 칠 필요 없을 때
- 이외에는 상황에 따라 일대다 관계로 풀 것
- 일대다 관계를 위한 엔터티를 만들고, 그 안에서 값 타입을 사용
-
영속성 전이 + 고아 객체 제거를 사용해 값타입 컬렉션처럼 사용
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true) @JoinColumn(name = “MEMBER_ID”) private List<AddressEntity> addressHistory = new ArrayList<>();
-
영속성 전이 + 고아 객체 제거를 사용해 값타입 컬렉션처럼 사용
- INSERT시 UPDATE 쿼리 한 번 더 나가지만 쿼리 최적화 등이 편리
- 다대일 일대다 양방향 매핑하면 UPDATE 쿼리 제거 가능
- 일대다 관계를 위한 엔터티를 만들고, 그 안에서 값 타입을 사용
- 값 타입 컬렉션은 정말 단순할 때만 사용
- 기본값 타입
- 단순히 값으로 사용하는 자바 기본 타입 혹은 객체 (
- 엔터티 타입
잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많음